

La reconnaissance d'images par l'IA peut sembler complexe, mais il s'agit essentiellement d'apprendre aux machines à percevoir les formes comme les humains, mais plus rapidement et à une échelle bien plus grande. Chaque photo, image satellite ou image vidéo n'est qu'une donnée jusqu'à ce qu'un système d'IA apprenne à l'interpréter. C'est ce processus d'apprentissage qui transforme les pixels bruts en signaux significatifs : objets, formes, texte ou évolutions au fil du temps.
Cet article explique en détail le fonctionnement de la reconnaissance d'images par l'IA. Non pas en théorie abstraite, mais de manière concrète : comment les images sont transformées en données numériques, comment les modèles apprennent à partir d'exemples et pourquoi la qualité des données prime sur les algorithmes sophistiqués. Si vous vous êtes déjà demandé ce qui se passe réellement entre le téléchargement d'une image et l'obtention d'un résultat automatique, c'est ici que tout commence.
Que signifie réellement la reconnaissance d'images en IA ?
La reconnaissance d'images est la capacité d'une machine à identifier des formes, des objets, du texte ou des caractéristiques dans une image et à leur attribuer une signification. Cette signification peut être simple, comme l'identification d'une voiture, ou complexe, comme la détection des premiers signes de stress hydrique des cultures sur des images aériennes.
Contrairement aux logiciels traditionnels, les systèmes d'IA ne suivent pas de règles prédéfinies telles que “ si ça a quatre roues, c'est une voiture ”. Ils apprennent plutôt à partir d'exemples. Des milliers, voire des millions d'images annotées sont utilisées pour enseigner au système l'apparence d'un objet dans différentes conditions, angles, éclairages et environnements.
La reconnaissance d'images repose essentiellement sur la reconnaissance de formes, grâce à l'apprentissage automatique et plus précisément à l'apprentissage profond. Le système ne comprend pas les concepts ; il apprend les relations statistiques entre les caractéristiques visuelles et les résultats.
Comment FlyPix transforme la reconnaissance d'images par IA en résultats concrets
À FlyPix, Nous utilisons la reconnaissance d'images par IA comme outil pratique pour le traitement à grande échelle d'images satellites, aériennes et de drones. Notre objectif est d'aider les équipes à transformer des images brutes en informations exploitables sans des semaines de travail manuel ni de configuration complexe.
Nous utilisons des agents d'IA capables de détecter, surveiller et inspecter des objets au sein d'ensembles de données vastes et denses. Les utilisateurs entraînent des modèles d'IA personnalisés à l'aide de leurs propres images et annotations, sans aucune compétence en programmation. Vous définissez les éléments importants de vos données, et le système apprend à les reconnaître de manière cohérente.
La rapidité est un atout majeur. Ce qui nécessitait autrefois des heures d'annotation manuelle peut désormais être réalisé en quelques secondes. De la classification de l'occupation des sols à l'inspection des infrastructures, en passant par l'agriculture et la surveillance environnementale, l'objectif est toujours de prendre des décisions plus rapides et plus fiables.
FlyPix est conçu pour s'adapter à différents secteurs et cas d'usage, sans les contraindre à un flux de travail unique. En rendant la reconnaissance d'images par IA flexible et accessible, nous facilitons son intégration au quotidien, et pas seulement dans des projets expérimentaux.
Tout commence par les pixels
Chaque image numérique est une grille de pixels. Chaque pixel contient des valeurs numériques qui décrivent sa couleur et sa luminosité. Dans la plupart des images, cela correspond à trois valeurs par pixel : rouge, vert et bleu.
Pour un humain, une photo de rue est immédiatement reconnaissable. Pour un modèle d'IA, cette même image est une vaste matrice de nombres. Il n'existe aucune compréhension innée des routes, des bâtiments ou des personnes. Le défi de la reconnaissance d'images consiste à apprendre à un système à interpréter ces nombres de manière pertinente.
Avant tout apprentissage, l'image est convertie en un format numérique exploitable par le modèle. La résolution, la profondeur des couleurs et la structure du fichier influent sur la quantité d'informations disponibles et sur la complexité du calcul.
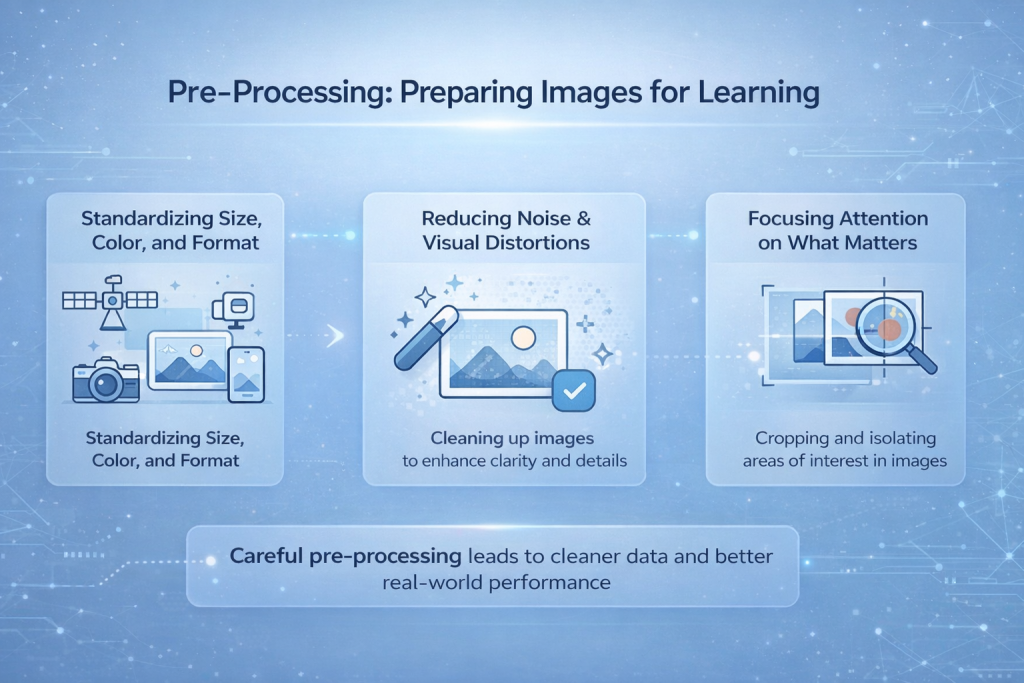
Prétraitement : Préparation des images pour l’apprentissage
Les images collectées par des appareils photo, des drones, des satellites ou des téléphones sont presque toujours hétérogènes. Elles présentent des résolutions, des conditions d'éclairage, des angles et des formats de fichiers variés. Certaines sont nettes, d'autres bruitées ou floues. Intégrer directement ces données brutes dans un modèle rend l'apprentissage instable et imprévisible. Le prétraitement est l'étape qui permet de maîtriser ce chaos visuel.
Normalisation de la taille, de la couleur et du format
L'une des premières étapes consiste à uniformiser les images. Les modèles nécessitent une forme d'entrée constante ; les images sont donc redimensionnées à une résolution fixe. Les valeurs de couleur sont normalisées afin que les différences de luminosité et de contraste ne perturbent pas l'apprentissage. Cela permet au modèle de se concentrer sur la structure plutôt que d'être perturbé par les variations d'exposition ou les réglages de l'appareil photo.
Réduction du bruit et des distorsions visuelles
Le bruit des capteurs, le flou de mouvement, les artefacts de compression ou les conditions météorologiques peuvent masquer des détails importants. Les techniques de prétraitement permettent d'atténuer ces effets, facilitant ainsi la détection des contours et des formes par le modèle. Cette étape n'améliore pas l'image au sens humain du terme, mais elle améliore la lisibilité des données pour le réseau.
Se concentrer sur l'essentiel
Dans de nombreux cas, seule une partie de l'image est pertinente. Le recadrage, le masquage ou l'isolation des zones d'intérêt permettent d'éliminer les distractions. En limitant ce que le modèle perçoit, l'apprentissage devient plus rapide et plus précis, notamment pour des tâches comme la détection d'objets ou l'imagerie médicale.
Pourquoi le prétraitement affecte directement les performances réelles
Le prétraitement ne rend pas un modèle plus intelligent en soi. Il crée des conditions d'apprentissage plus favorables. Si cette étape est bâclée ou mal conçue, les modèles peuvent bien fonctionner lors de tests contrôlés, mais échouer dans des situations réelles. Un prétraitement rigoureux fait souvent la différence entre un système performant en théorie et un système performant en pratique.
Apprentissage des caractéristiques : comment l’IA découvre des modèles
Les humains apprennent à reconnaître les objets en observant leurs caractéristiques. Les contours, les formes, les textures et les proportions jouent tous un rôle. Les modèles d'IA apprennent de manière similaire, mais plus mathématique.
La plupart des systèmes modernes de reconnaissance d'images reposent sur des réseaux neuronaux convolutifs (CNN). Ces réseaux sont conçus pour analyser les images à l'aide de petits filtres qui se déplacent sur l'image et détectent les motifs locaux.
Les premières couches d'un réseau de neurones convolutif (CNN) détectent généralement des caractéristiques très simples comme les contours, les angles et les dégradés de couleurs. Les couches intermédiaires combinent ces éléments pour former des formes et des textures. Les couches profondes assemblent ces formes en motifs de plus haut niveau qui correspondent à des objets ou des régions d'intérêt.
L'idée clé est la hiérarchie. Le modèle ne passe pas directement des pixels à “ ceci est un arbre ”. Il construit cette compréhension couche par couche.
Pourquoi la convolution est importante
La convolution permet d'appliquer le même détecteur de motifs à l'ensemble de l'image. Un contour vertical reste un contour vertical, qu'il se trouve à gauche ou à droite de l'image.
Cette approche rend les modèles plus efficaces et plus robustes. Au lieu de mémoriser des agencements de pixels précis, le système apprend des motifs visuels réutilisables. C'est l'une des raisons pour lesquelles les réseaux de neurones convolutifs (CNN) fonctionnent si bien avec des images de tailles et de mises en page différentes.
On ajoute souvent des couches de regroupement pour réduire la taille des données tout en conservant les informations importantes. Cela permet de maîtriser les coûts de calcul et d'éviter que le modèle ne devienne trop sensible aux variations minimes.
Entraînement du modèle : apprentissage par l’exemple
L'entraînement est l'étape où la reconnaissance d'images prend effet. Le modèle est confronté à un vaste ensemble d'images étiquetées. Chaque image est associée à la réponse correcte, comme “ culture saine ”, “ route endommagée ” ou “ présence d'une personne ”.”
Durant la formation, le processus suit une boucle répétitive :
- Le modèle analyse une image d'entrée et génère une prédiction
- La prédiction est comparée à l'étiquette correcte
- La différence entre les deux est mesurée comme une erreur
- Le modèle ajuste ses paramètres internes pour réduire cette erreur.
- Le même processus se répète sur des milliers, voire des millions d'exemples.
C’est cette adaptation progressive qui permet au système de s’améliorer au fil du temps.
La rétropropagation est le mécanisme qui rend cet apprentissage possible. Elle remonte le réseau en suivant les erreurs et met à jour les poids de chaque couche afin que les prédictions futures soient plus précises.
La qualité de l'entraînement dépend fortement des données utilisées. Si l'ensemble de données est trop petit, mal étiqueté ou biaisé en faveur de certaines conditions, le modèle héritera de ces faiblesses. Aucun réglage ne peut compenser entièrement des données d'entraînement de faible qualité ou déséquilibrées.
Le rôle des données étiquetées
Les données étiquetées constituent le fondement de la reconnaissance d'images supervisée. Chaque étiquette indique au modèle ce qu'il doit apprendre d'une image.
La création de ces étiquettes est souvent l'étape la plus coûteuse et la plus chronophage du processus. Des annotateurs humains doivent marquer soigneusement les objets, tracer des cadres de délimitation, segmenter des régions ou classer les images.
Une annotation de qualité permet d'obtenir de meilleurs modèles. Une annotation de mauvaise qualité engendre confusion et résultats peu fiables. C'est pourquoi de nombreux échecs de reconnaissance d'images sont imputables à l'ensemble de données plutôt qu'à l'algorithme.
Apprentissage par transfert et inférence : d’un modèle pré-entraîné aux prédictions réelles
L'entraînement d'un réseau neuronal profond à partir de zéro nécessite une grande quantité de données étiquetées et une puissance de calcul considérable, c'est pourquoi de nombreuses équipes ne partent pas de zéro. Elles utilisent plutôt l'apprentissage par transfert.
Comment fonctionne l'apprentissage par transfert
L'apprentissage par transfert s'appuie sur un modèle ayant déjà appris des caractéristiques visuelles générales à partir d'un vaste ensemble de données. Ce modèle pré-entraîné comprend déjà des motifs courants tels que les contours, les textures et les formes. Il est ensuite affiné pour une tâche spécifique à l'aide d'un ensemble de données plus restreint et adapté à cette tâche.
En pratique, les premières couches restent généralement inchangées, tandis que les couches suivantes sont réentraînées pour s'adapter à la nouvelle tâche. Par exemple, un modèle entraîné sur des images générales peut être adapté à la reconnaissance de défauts dans des composants industriels ou de motifs dans des examens médicaux. Cette approche accélère le développement et améliore souvent la précision, notamment lorsque le jeu de données est limité.
De l'entraînement à l'inférence
Une fois le modèle entraîné ou affiné, il passe en mode d'inférence. C'est à cette étape qu'il traite de nouvelles images, jamais vues auparavant, et produit des prédictions.
Le pipeline d'inférence est le reflet du pipeline d'entraînement :
- Les images sont prétraitées
- Ils transitent par le réseau
- Le résultat est renvoyé sous forme d'étiquettes, de probabilités, d'objets détectés ou de régions segmentées.
À ce stade, la priorité change. L'objectif n'est plus l'apprentissage, mais la performance constante. Dans les systèmes réels, l'inférence doit souvent s'exécuter en temps réel ou quasi réel ; la vitesse et la fiabilité sont donc tout aussi importantes que la précision brute.
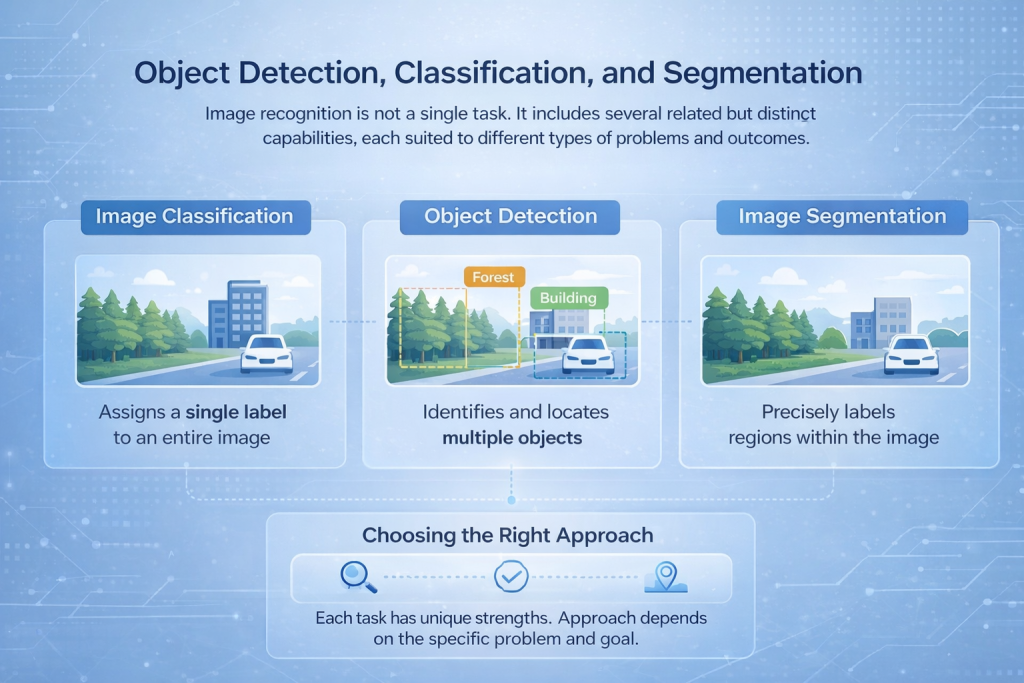
Détection, classification et segmentation d'objets
La reconnaissance d'images n'est pas une tâche unique. Elle comprend plusieurs capacités connexes mais distinctes, chacune adaptée à différents types de problèmes et de résultats.
Classification des images
La classification d'images attribue une étiquette à une image entière. Le modèle analyse la scène dans son ensemble et détermine la description la plus pertinente, par exemple si l'image contient une forêt, un bâtiment ou un véhicule. Cette approche est efficace lorsque le contenu global prime sur la localisation précise.
Détection d'objets
La détection d'objets va plus loin en identifiant et en localisant plusieurs objets au sein d'une même image. Au lieu d'une simple étiquette, le modèle dessine des cadres de délimitation autour des éléments d'intérêt et les classe un par un. Cette technique est couramment utilisée dans des applications telles que la surveillance du trafic, les systèmes de sécurité et l'inspection industrielle.
Segmentation d'images
La segmentation offre le niveau d'analyse le plus détaillé. Elle étiquette les pixels ou régions individuels d'une image, permettant ainsi au système de séparer les objets avec une grande précision. Ceci est essentiel dans des applications telles que l'imagerie médicale, la cartographie de l'occupation des sols ou l'analyse de surface, où la précision des contours est primordiale.
Choisir la bonne approche
Chacune de ces tâches requiert des architectures de réseau et des stratégies d'apprentissage différentes. Le choix approprié dépend du problème à résoudre : comptage de véhicules, lecture de texte ou cartographie précise de l'occupation des sols.
Mesurer la performance
Les modèles de reconnaissance d'images sont évalués à l'aide de métriques telles que l'exactitude, la précision, le rappel et l'intersection sur l'union.
La précision seule est souvent trompeuse. Un modèle qui détecte rarement un objet peut paraître précis simplement parce que cet objet est rare. La précision et le rappel permettent d'évaluer plus clairement la fiabilité du modèle.
Les tests doivent toujours être effectués sur des données que le modèle n'a jamais vues auparavant. Cela permet de déterminer si le système a appris des schémas généraux ou s'il a simplement mémorisé l'ensemble d'entraînement.
Complexité du monde réel, biais et limites pratiques
La reconnaissance d'images par IA fonctionne de manière optimale dans des environnements contrôlés, or les environnements réels sont rarement contrôlés. Une fois que les modèles quittent le laboratoire et sont confrontés aux conditions réelles, leurs limites deviennent beaucoup plus évidentes.
Pourquoi les conditions réelles sont difficiles à modéliser
L'éclairage varie tout au long de la journée. Les objets se chevauchent ou disparaissent partiellement du champ de vision. Les conditions météorologiques affectent la visibilité. Les caméras bougent, tombent en panne ou enregistrent des données imparfaites. Tous ces éléments introduisent du bruit que les modèles doivent apprendre à gérer.
Un système performant en phase de test peut rencontrer des difficultés lorsque ces variables s'accumulent. C'est pourquoi les tests continus, la surveillance et la formation continue sont des éléments essentiels de tout système de production, et non des améliorations optionnelles.
Le rôle de la surveillance humaine
La reconnaissance d'images par IA est performante, mais pas infaillible. Dans les applications critiques pour la sécurité ou à fort impact, une intervention humaine demeure indispensable. L'humain apporte le contexte, le jugement et la responsabilité dans les situations où les décisions automatisées ne suffisent pas.
Comment les biais s'introduisent dans les systèmes de reconnaissance d'images
Les modèles apprennent directement à partir des données sur lesquelles ils sont entraînés, y compris leurs lacunes et leurs déséquilibres. Si certains environnements, populations ou conditions sont sous-représentés, leurs performances s'en trouveront affectées.
Les biais deviennent particulièrement problématiques dans des domaines comme la surveillance, le contrôle d'accès ou la sécurité publique, où les erreurs peuvent avoir de réelles conséquences. Ces problèmes sont rarement dus aux seuls algorithmes.
Pourquoi les biais ne sont pas un problème purement technique
Il n'existe pas de solution technique unique aux biais. Améliorer l'équité et la fiabilité nécessite :
- Des ensembles de données plus diversifiés et représentatifs
- Évaluation minutieuse dans différents scénarios
- Examen continu de l'utilisation et de la mise à jour des modèles
Les biais relèvent en fin de compte d'un problème de données et de processus. Les corriger exige des choix délibérés, et non pas seulement de meilleurs modèles.

Considérations relatives à la confidentialité et à l'éthique
La reconnaissance d'images implique souvent des données sensibles. Les visages, les lieux et les comportements peuvent être déduits d'images, parfois sans que le sujet en soit pleinement conscient.
L’utilisation responsable ne se limite pas à la précision technique. Elle exige des règles claires et des limites conscientes, notamment :
- Politiques transparentes de collecte et d'utilisation des données
- Consentement explicite lorsque des données personnelles sont impliquées
- Stockage sécurisé et accès contrôlé aux données d'images
- Respect des réglementations locales et internationales en matière de protection de la vie privée
- Une responsabilité claire quant à l'utilisation des décisions prises par le système
Les considérations éthiques ne sont pas une simple réflexion après coup. Elles déterminent la confiance du public, l'acceptation juridique et la viabilité à long terme des systèmes de reconnaissance d'images.
Pourquoi la reconnaissance d'images est importante
Malgré ses défis, la reconnaissance d'images par IA est devenue un outil essentiel dans de nombreux secteurs. Elle permet d'automatiser des processus où l'inspection humaine serait lente, coûteuse ou peu fiable.
Du diagnostic médical à l'agriculture, de la surveillance des infrastructures au commerce de détail, la capacité à extraire des informations pertinentes des données visuelles change la façon dont les décisions sont prises.
La véritable valeur réside non pas dans le remplacement du jugement humain, mais dans son enrichissement. L'IA gère l'échelle et la vitesse. Les humains gèrent le contexte et la responsabilité.
Conclusion : Des pixels aux décisions
La reconnaissance d'images par l'IA fonctionne car elle décompose une capacité humaine complexe en étapes plus simples. Les pixels deviennent des nombres, les nombres des motifs, et les motifs des prédictions. Il n'y a pas de moment magique où une machine comprend soudainement une image. Il n'y a que l'apprentissage, l'itération et le perfectionnement.
Comprendre ce processus permet de définir des attentes réalistes. Cela aide également les équipes à concevoir de meilleurs systèmes, à poser les bonnes questions et à utiliser la technologie de manière plus responsable. En fin de compte, la reconnaissance d'images ne consiste pas à ce que les machines voient comme les humains, mais à ce qu'elles voient différemment et utilisent cette différence pour prendre des décisions plus rapides et plus cohérentes au moment opportun.
Questions fréquemment posées
La reconnaissance d'images par IA est le processus qui consiste à apprendre à un ordinateur à identifier des motifs dans des images. Au lieu de comprendre les images comme le font les humains, le système apprend à partir d'exemples et utilise des nombres et des probabilités pour déterminer ce qu'il observe.
Non. L'IA ne comprend pas les images de manière conceptuelle. Elle traite les valeurs des pixels et apprend des schémas à partir de relations statistiques. Les résultats peuvent sembler similaires à la perception humaine, mais le processus est totalement différent.
La plupart des systèmes modernes de reconnaissance d'images utilisent l'apprentissage profond, et plus particulièrement les réseaux neuronaux convolutifs. Ces modèles sont conçus pour apprendre les caractéristiques visuelles telles que les contours, les formes et les textures à travers plusieurs couches.
Cela dépend de la tâche. Les problèmes de classification simples peuvent se contenter de quelques milliers d'images, tandis que les tâches complexes de détection ou de segmentation nécessitent souvent des dizaines, voire des centaines de milliers d'exemples étiquetés. La qualité des données est aussi importante que leur quantité.
L'annotation indique au modèle ce qu'il doit apprendre de chaque image. Un étiquetage de mauvaise qualité entraîne de mauvaises prédictions. L'annotation de haute qualité est souvent l'étape la plus chronophage de la création d'un système de reconnaissance d'images, mais elle influe directement sur la précision et la fiabilité.