
La reconnaissance d'images peut paraître intimidante au premier abord. Réseaux neuronaux, jeux de données, boucles d'apprentissage, GPU : tout cela peut sembler complexe avant même d'avoir écrit une seule ligne de code. Mais en pratique, la création d'une IA de reconnaissance d'images consiste davantage à prendre de bonnes décisions étape par étape qu'à tout maîtriser d'un coup.
La reconnaissance d'images consiste essentiellement à apprendre à un système à repérer des motifs dans les images et à formuler des jugements cohérents à partir de ce qu'il voit. Il peut s'agir d'identifier des objets, de classifier des scènes, de détecter des défauts ou de signaler des anomalies. La technologie sous-jacente est puissante, mais le processus lui-même est étonnamment simple : définir la tâche, préparer les données, entraîner un modèle, le tester rigoureusement et le déployer là où il est réellement utile.
Cet article décrit ce processus de manière pratique et directe. Pas de fioritures, pas de raccourcis, et aucune présomption que vous rédigez un article de recherche. Juste un aperçu clair de la façon dont l'IA de reconnaissance d'images est construite aujourd'hui, des éléments essentiels à chaque étape et des erreurs courantes.

Commencez par un problème que vous pouvez décrire clairement.
Avant de manipuler des données ou des modèles, il vous faut une tâche clairement définie. Pas “ reconnaître des images ”, mais quelque chose de concret.
- Vous classez une image entière dans une seule catégorie ?
- Vous repérez des objets et vous les encadrez ?
- Identifiez-vous des formes ou des contours précis au niveau du pixel ?
Chacun de ces problèmes est différent et comporte des coûts et des risques différents.
De nombreux projets échouent car ils sont mal définis dès le départ et se complexifient trop tard. Si vous ne pouvez pas expliquer votre objectif en une phrase à une personne non spécialiste, c'est qu'il n'est pas encore prêt.
Bons exemples
- “ Détecter les dommages visibles sur les panneaux de carrosserie à partir de photos. ”
- “ Compter les bûches empilées sur les images aériennes. ”
- “ Déterminer si une zone cultivée présente des signes précoces de stress. ”
Mauvais exemples
- “ Utiliser l’IA pour analyser les images. ”
- “ Développer une vision par ordinateur intelligente. ”
La clarté à ce stade permet d'économiser des mois par la suite.
Comprendre comment les images deviennent des nombres
Un ordinateur ne voit pas d'objets. Il voit des tableaux de nombres.
Chaque image est convertie en pixels, et chaque pixel se voit attribuer une valeur représentant l'intensité ou la couleur. Une image couleur n'est pas une simple image pour un modèle ; c'est une grille de nombres répartis sur plusieurs canaux.
La reconnaissance d'images fonctionne en apprenant les motifs contenus dans ces données numériques : contours, formes, textures, contrastes. Non pas parce que le modèle comprend le sens, mais parce qu'il repère des régularités statistiques corrélées aux étiquettes.
C'est important car cela change votre perception de la qualité des données. Si le modèle échoue, c'est souvent parce que les chiffres qu'il analyse sont incohérents, bruités ou trompeurs.
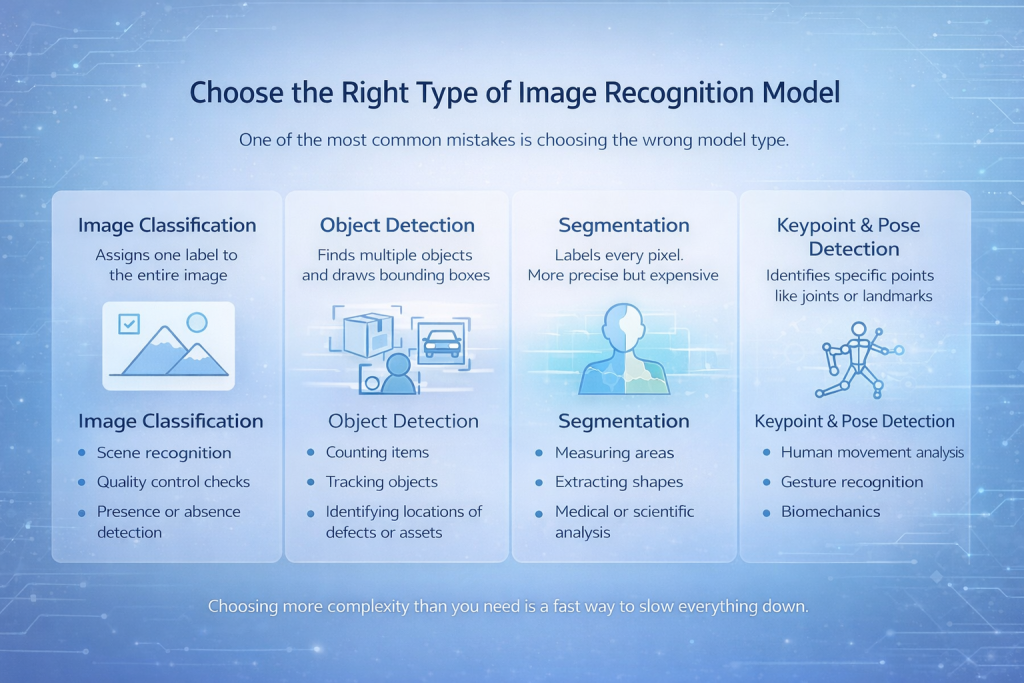
Choisir le bon type de modèle de reconnaissance d'images
L'une des erreurs les plus fréquentes consiste à choisir le mauvais type de modèle.
Il existe plusieurs catégories principales :
Classification des images
Le modèle attribue une seule étiquette à l'image entière. Simple, rapide et efficace lorsque l'objet d'intérêt domine l'image.
Idéal pour :
- Reconnaissance de scène
- contrôles de qualité
- Détection de présence ou d'absence
Détection d'objets
Le modèle détecte plusieurs objets et dessine des cadres de délimitation autour d'eux.
Idéal pour :
- articles de comptage
- Objets de suivi
- Identification des emplacements des défauts ou des actifs
Segmentation
Chaque pixel reçoit une étiquette. C'est plus précis, mais aussi plus coûteux.
Idéal pour :
- Surfaces de mesure
- Extraction de formes
- Analyse médicale ou scientifique
Détection des points clés et de la pose
Le modèle identifie des points spécifiques tels que des articulations ou des points de repère.
Idéal pour :
- Analyse du mouvement humain
- Reconnaissance gestuelle
- Biomécanique
Choisir une complexité supérieure à celle nécessaire est un moyen rapide de tout ralentir.
Les données ne sont pas seulement importantes. Elles sont le projet.
Les modèles attirent l'attention. Ce sont les données qui font le vrai travail.
Un système de reconnaissance d'images performant dépend bien plus de la qualité des données que de son architecture. Même le modèle le plus avancé sera inefficace si les données sont de mauvaise qualité ou incohérentes.
Principes clés qui comptent vraiment :
La variété des données prime sur leur volume.
Dix mille images similaires sont souvent de moins bonne qualité que deux mille images différentes. Les angles de prise de vue, les conditions d'éclairage, les arrière-plans, les résolutions et les types d'appareils utilisés sont plus importants que le simple nombre d'images.
Les étiquettes doivent correspondre à la réalité
Si les humains ont des désaccords sur les étiquettes, le modèle risque d'être confus. Les classes ambiguës doivent être fusionnées ou redéfinies au plus tôt.
L'équilibre est important
Si une classe domine, la précision devient trompeuse. Un modèle peut être “ précis ” en devinant systématiquement la classe majoritaire.
L'annotation est le domaine où la qualité se gagne ou se perd.
L'étiquetage est souvent bâclé, et cela se voit par la suite. Une mauvaise annotation engendre des problèmes difficiles à déceler pendant l'entraînement, mais criants de vérité en situation réelle. Les modèles deviennent instables, les prédictions semblent aléatoires et les cas limites s'accumulent. Chaque image mal étiquetée compromet insidieusement le processus d'apprentissage.
Une bonne annotation repose sur des règles d'étiquetage claires et appliquées de manière uniforme par tous. Lorsque différentes personnes interprètent les étiquettes différemment, le modèle apprend la confusion au lieu de reconnaître des schémas. La cohérence est aussi importante que la précision ; c'est pourquoi des vérifications ponctuelles régulières et des audits de petite envergure sont essentiels. Ils permettent de détecter les dérives dès leur apparition, avant qu'elles ne se propagent à l'ensemble des données.
L'annotation doit également pouvoir évoluer. À mesure que de nouveaux cas particuliers apparaissent, les étiquettes doivent être affinées plutôt que d'être contraintes à des définitions devenues obsolètes. Ce travail de nettoyage itératif est long, mais il garantit la stabilité du modèle.
Les outils d'étiquetage assisté par IA peuvent accélérer le processus, notamment sur les grands ensembles de données, mais ils ne remplacent pas le jugement humain. Ils se contentent de reproduire la logique qui leur est fournie. Si les règles sont imprécises ou erronées, l'automatisation amplifiera l'erreur au lieu de la corriger.
Le prétraitement n'est pas cosmétique.
Le prétraitement ne consiste pas seulement à embellir les images. Il s'agit de réduire les variations indésirables et de mettre en valeur ce qui compte.
Étapes courantes qui aident réellement :
- Redimensionnement des images à une résolution uniforme
- Normalisation des valeurs de pixels
- Correction de l'orientation
- Couper les zones non pertinentes
L'augmentation des données mérite une attention particulière. De simples transformations comme la rotation, le retournement, la modification de la luminosité ou l'injection de bruit peuvent améliorer considérablement la généralisation. L'objectif n'est pas de tromper le modèle, mais de le préparer à la réalité.
Si vos données paraissent trop parfaites, votre modèle paniquera dans le monde réel.
L'architecture du modèle est moins importante que vous ne le pensez.
Il est tentant de privilégier le modèle le plus récent ou le plus en vogue. Les transformateurs, les architectures massives et les pipelines complexes peuvent paraître impressionnants sur le papier, mais ne garantissent pas de meilleurs résultats.
En pratique, de nombreux systèmes de reconnaissance d'images fiables reposent sur des architectures éprouvées. Les réseaux de neurones convolutifs dominent toujours ce domaine, et ce pour une bonne raison : ils sont stables, efficaces et plus faciles à comprendre en cas de problème. Cette fiabilité est souvent plus importante que de gagner quelques points de pourcentage supplémentaires lors de tests de performance.
L'apprentissage par transfert est généralement le point de départ le plus judicieux. Utiliser un modèle ayant déjà appris à partir de vastes ensembles de données diversifiés offre une base solide, surtout lorsque vos propres données sont limitées. Le réglage fin est optimal lorsque la nouvelle tâche est relativement proche de celles que le modèle a déjà traitées, lorsque le surapprentissage est activement contrôlé et lorsque le réentraînement est effectué avec précaution plutôt que de manière brutale. De petits ajustements réfléchis ont tendance à être plus performants qu'un réentraînement par force brute.
Les modèles plus grands ne sont pas toujours de meilleurs modèles. Leur entraînement coûte plus cher, leur débogage est plus difficile et ils présentent souvent des défaillances subtiles difficiles à déceler.
L'entraînement est un dialogue itératif avec vos données.
La formation ne se fait pas en un clic. C'est un processus itératif.
Vous vous entraînez, observez les résultats, identifiez les schémas de défaillance, ajustez les données ou les paramètres, et vous recommencez.
Pratiques de formation clés :
- Utilisez des ensembles d'entraînement, de validation et de test distincts.
- Observez les courbes de perte, pas seulement la précision.
- Arrêtez l'entraînement lorsque les progrès stagnent.
- Ajustez soigneusement le taux d'apprentissage et la taille des lots.
L'accélération GPU est indispensable pour les applications professionnelles. L'entraînement sur CPU convient à l'apprentissage, mais s'avère impraticable pour les projets concrets. Les GPU réduisent le temps d'itération, ce qui améliore directement la qualité du modèle en permettant l'expérimentation.
L'évaluation doit aller au-delà de la simple exactitude.
La précision est l'une des mesures les plus faciles à calculer, mais aussi l'une des plus faciles à mal interpréter. Un modèle peut paraître très précis et pourtant se révéler inutilisable en situation réelle.
Une bonne évaluation va plus loin. Les matrices de confusion permettent de mettre en évidence les erreurs récurrentes du modèle. La précision et le rappel sont bien plus informatifs lorsque les classes sont déséquilibrées ou lorsque certaines erreurs sont plus coûteuses que d'autres. Tester le modèle sur des images réelles et inédites révèle souvent des problèmes qui n'apparaissent jamais sur des données de validation propres.
L'étape d'évaluation la plus précieuse reste l'analyse manuelle. Examiner directement les prédictions erronées et se demander pourquoi elles se sont produites apporte des informations qu'aucune mesure ne peut pleinement saisir. Les modèles sont étonnamment honnêtes quant à leurs faiblesses si l'on prend le temps d'analyser leurs erreurs plutôt que de se fier à des chiffres synthétiques.
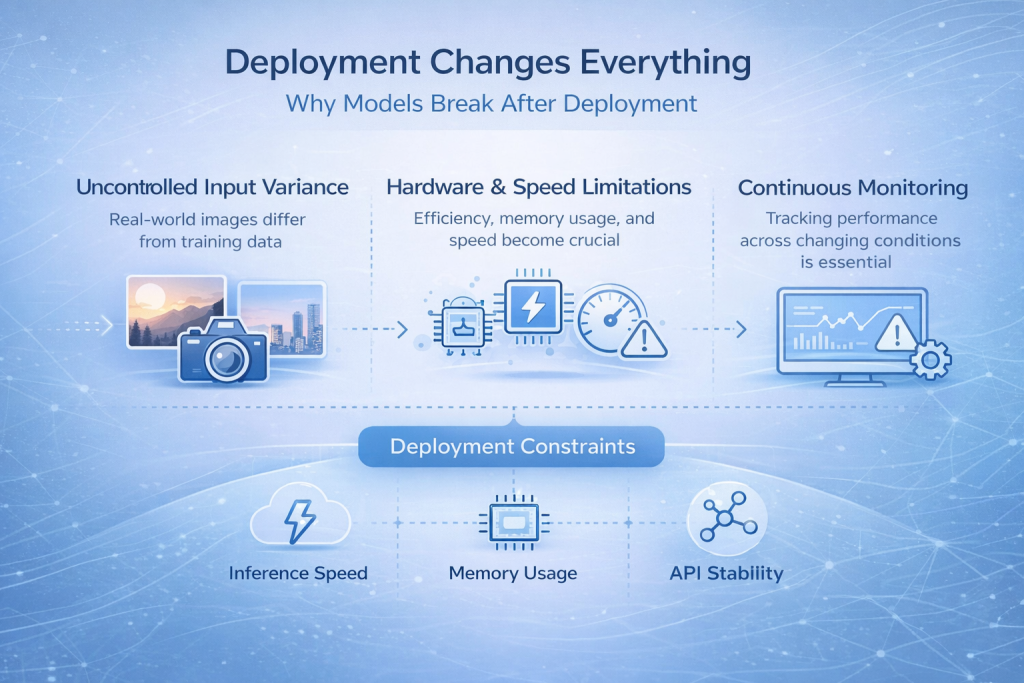
Le déploiement change tout
Pourquoi les modèles dysfonctionnent-ils après leur déploiement ?
De nombreux modèles de reconnaissance d'images fonctionnent bien pendant la phase de développement, puis tombent en panne subitement une fois déployés. C'est l'un des moments les plus fréquents et les plus frustrants de tout le processus.
La raison est simple : les données réelles ressemblent rarement aux données d’entraînement. Les images proviennent de différents appareils photo, les conditions d’éclairage varient au cours de la journée, des artefacts de compression apparaissent et les utilisateurs n’adoptent pas des comportements d’utilisation idéaux. Même de légères variations dans la manière dont les images sont capturées peuvent faire sortir un modèle de son domaine d’apprentissage.
Ce qui paraissait stable dans un environnement contrôlé devient soudainement peu fiable.
Les contraintes que vous ne pouvez ignorer
Le déploiement vous oblige à repenser la précision du modèle. La vitesse d'inférence devient cruciale lorsque des prédictions en temps réel sont nécessaires. L'utilisation de la mémoire est importante lorsque le modèle s'exécute sur des périphériques ou du matériel mobile. Les contraintes matérielles déterminent les architectures envisageables, et la stabilité de l'API devient essentielle dès lors que d'autres systèmes dépendent de vos prédictions.
La surveillance passe également d'un atout appréciable à une nécessité. Sans visibilité sur le comportement du modèle après sa mise en production, les défaillances peuvent passer inaperçues jusqu'à ce que la confiance soit rompue.
Rendre le modèle utilisable
L'exportation d'un modèle vers des formats tels que TensorFlow Lite ou ONNX n'est pas qu'une simple étape technique en fin de processus. Elle fait partie intégrante de la transformation d'un modèle entraîné en un outil utilisable en production. Ces formats permettent d'adapter le modèle à différents environnements, de réduire la surcharge et d'améliorer la compatibilité avec les cibles de déploiement.
Un modèle performant en test mais incapable de résister au déploiement n'est pas abouti. Le véritable succès n'est atteint que lorsque le système fonctionne de manière fiable là où il est censé être utilisé.
Reconnaissance d'images dans le monde réel : comment nous la développons chez FlyPix AI
À FlyPix AI, Nous n'envisageons pas la reconnaissance d'images comme un simple exercice de laboratoire. Nous travaillons quotidiennement avec des images satellites, aériennes et de drones, où les scènes sont denses, les objets se chevauchent et les conditions jamais idéales. Cette réalité influence la façon dont nous concevons et utilisons l'IA.
Notre objectif a toujours été simple : supprimer le goulot d’étranglement de l’analyse visuelle manuelle. Les équipes passaient des centaines d’heures à annoter des images, à vérifier les résultats, et à les revérifier à chaque changement de situation. Nous avons créé FlyPix pour automatiser ce travail grâce à des agents d’IA capables de détecter, de surveiller et d’inspecter des objets à grande échelle, sans compromettre la précision.
Ce qui compte avant tout pour nous, c'est la praticité. Vous ne devriez pas avoir besoin de connaissances approfondies en IA ni d'une équipe d'ingénieurs en apprentissage automatique pour entraîner un modèle adapté à votre cas d'usage. Avec FlyPix, les équipes peuvent créer des modèles de reconnaissance d'images personnalisés à partir de leurs propres annotations, en se concentrant sur les objets essentiels à leur secteur. Chantiers, ports, terres agricoles, infrastructures, zones forestières : les images diffèrent, mais le défi reste le même.
Nous concevons également tous nos systèmes en tenant compte du déploiement. Les données géospatiales réelles évoluent constamment ; les modèles doivent donc gérer ces variations dès le départ. Cela implique de concevoir des systèmes fiables, même en dehors des environnements de test, capables de traiter rapidement de grands volumes d'images et de fournir des résultats exploitables immédiatement par les équipes. Pour nous, la reconnaissance d'images n'est réussie que si elle se montre fiable au quotidien, et non pas seulement lors des tests.
Les boucles de rétroaction maintiennent le modèle en vie
Une IA de reconnaissance d'images n'est pas statique. Les données changent. Les environnements changent. Les attentes changent.
Les systèmes durables sont conçus en tenant compte des retours d'information :
- Collecter de nouvelles images après le déploiement
- Cas de défaillance de suivi
- Se former périodiquement
- Adapter les étiquettes lorsque la réalité change
Négliger l'apprentissage post-déploiement est l'un des moyens les plus rapides de perdre confiance dans le système.
Conclusion
Concevoir une IA de reconnaissance d'images réellement efficace repose moins sur la recherche des modèles les plus récents que sur la maîtrise des fondamentaux. Une définition claire du problème, un traitement rigoureux des données, une évaluation approfondie et une planification réaliste du déploiement sont bien plus importants que le choix d'un algorithme en particulier.
Les systèmes les plus fiables ne sont pas les plus complexes. Ce sont ceux qui reposent sur une compréhension précise de l'évolution des images dans le monde réel et de la façon dont les modèles réagissent à ces changements. Ils sont entraînés sur des données réalistes, évalués à l'aide de métriques qui révèlent leurs faiblesses et déployés en tenant compte des contraintes dès leur conception.
S'il y a une leçon à retenir, c'est celle-ci : la reconnaissance d'images est un processus d'ingénierie, et non une expérience ponctuelle. En l'abordant ainsi, en itérant avec soin et en restant ancrée dans des cas d'utilisation réels, les résultats se confirment généralement bien après la fin de la démonstration.
FAQ
L'intelligence artificielle de reconnaissance d'images est un type de système de vision par ordinateur qui apprend à identifier des motifs, des objets ou des caractéristiques dans les images. Elle fonctionne en analysant les données des pixels et en utilisant des modèles entraînés pour associer des motifs visuels à des étiquettes ou à des résultats.
Pas toujours. Si les grands ensembles de données sont utiles, la diversité et la qualité priment sur la quantité brute. Grâce à l'apprentissage par transfert et à une augmentation appropriée des données, il est possible d'entraîner des modèles performants sur des ensembles de données relativement petits, mais de grande qualité.
Pour la plupart des projets, partir d'un réseau neuronal convolutif éprouvé et appliquer l'apprentissage par transfert constitue une approche sûre et efficace. Les modèles plus complexes ne devraient être utilisés que lorsqu'il existe une raison claire et des données suffisantes pour les justifier.
La précision seule ne suffit pas. Il convient d'examiner les matrices de confusion, la précision et le rappel, et de tester le modèle sur des images réelles n'ayant jamais servi à l'entraînement. L'analyse manuelle des erreurs est souvent l'étape la plus révélatrice.
Cela se produit généralement car les images de production diffèrent des données d'entraînement. Les variations d'éclairage, la qualité de l'appareil photo, la compression d'image ou le comportement de l'utilisateur peuvent toutes affecter les performances. Cet écart est fréquent et doit être pris en compte lors du développement.
Oui. Le déploiement n'est pas une étape finale que l'on peut ignorer jusqu'au bout. Les limites matérielles, la vitesse d'inférence, l'utilisation de la mémoire et les exigences d'intégration influencent toutes la manière dont le modèle doit être construit et entraîné.