

قد يبدو التعرف على الصور باستخدام الذكاء الاصطناعي معقدًا، لكنه في جوهره يدور حول تعليم الآلات رؤية الأنماط كما يراها البشر، ولكن بشكل أسرع وعلى نطاق أوسع بكثير. كل صورة، أو صورة قمر صناعي، أو إطار فيديو، ما هي إلا بيانات إلى أن يتعلم نظام الذكاء الاصطناعي كيفية تفسيرها. عملية التعلم هذه هي التي تحول وحدات البكسل الخام إلى إشارات ذات معنى: أشياء، أشكال، نصوص، أو تغيرات مع مرور الوقت.
تُفصّل هذه المقالة آلية عمل تقنية التعرف على الصور بالذكاء الاصطناعي. ليس من منظور نظري مجرّد، بل من منظور عملي، كيف تتحول الصور إلى أرقام، وكيف تتعلم النماذج من الأمثلة، ولماذا تُعدّ جودة البيانات أهم من الخوارزميات البراقة. إذا تساءلت يومًا عما يحدث فعلاً بين تحميل الصورة والحصول على النتيجة تلقائيًا، فهذه هي البداية.
ما الذي يعنيه التعرف على الصور حقًا في الذكاء الاصطناعي
التعرف على الصور هو قدرة الآلة على تحديد الأنماط أو الأشياء أو النصوص أو السمات داخل الصورة وإضفاء معنى عليها. قد يكون هذا المعنى بسيطًا، مثل تحديد سيارة، أو معقدًا، مثل اكتشاف العلامات المبكرة لإجهاد المحاصيل في الصور الجوية.
على عكس البرامج التقليدية، لا تتبع أنظمة الذكاء الاصطناعي قواعد ثابتة مثل "إذا كان له أربع عجلات، فهو سيارة". بل تتعلم من الأمثلة. تُستخدم آلاف أو ملايين الصور المصنفة لتعليم النظام كيف يبدو الشيء في ظروف وزوايا وإضاءة وبيئات مختلفة.
في جوهرها، تُعدّ تقنية التعرّف على الصور شكلاً من أشكال التعرّف على الأنماط، مدفوعةً بالتعلم الآلي، وتحديداً بالتعلم العميق. لا يفهم النظام المفاهيم، بل يتعلّم العلاقات الإحصائية بين السمات المرئية والنتائج.
كيف نحول تقنية التعرف على الصور بالذكاء الاصطناعي إلى نتائج واقعية في فلاي بيكس
في فلاي بكس, نستخدم تقنية التعرف على الصور بالذكاء الاصطناعي كأداة عملية للتعامل مع صور الأقمار الصناعية والصور الجوية وصور الطائرات المسيّرة على نطاق واسع. هدفنا هو مساعدة الفرق على الانتقال من الصور الخام إلى رؤى واضحة دون الحاجة إلى أسابيع من العمل اليدوي أو الإعدادات المعقدة.
نعتمد على أنظمة الذكاء الاصطناعي القادرة على اكتشاف ومراقبة وفحص العناصر في مجموعات بيانات ضخمة وكثيفة. يقوم المستخدمون بتدريب نماذج ذكاء اصطناعي مخصصة باستخدام صورهم وتعليقاتهم الخاصة، دون الحاجة إلى مهارات برمجية. أنت تحدد ما يهمك في بياناتك، ويتعلم النظام التعرف عليه باستمرار.
تُعدّ السرعة عنصراً أساسياً في القيمة. فما كان يتطلب ساعات من التدوين اليدوي أصبح يُنجز الآن في ثوانٍ. بدءاً من تصنيف استخدامات الأراضي وفحص البنية التحتية، وصولاً إلى الزراعة والرصد البيئي، ينصبّ التركيز دائماً على اتخاذ قرارات أسرع وأكثر موثوقية.
صُممت تقنية FlyPix لتتكيف مع مختلف القطاعات وحالات الاستخدام، لا لفرضها ضمن سير عمل واحد. من خلال الحفاظ على مرونة وسهولة الوصول إلى تقنية التعرف على الصور بالذكاء الاصطناعي، نسهل على الفرق تطبيقها في العمليات اليومية، وليس فقط في المشاريع التجريبية.
كل شيء يبدأ بالبكسلات
كل صورة رقمية عبارة عن شبكة من البكسلات. يحتوي كل بكسل على قيم عددية تصف اللون والسطوع. في معظم الصور، يعني هذا ثلاث قيم لكل بكسل للأحمر والأخضر والأزرق.
بالنسبة للإنسان، يمكن التعرف على صورة الشارع فوراً. أما بالنسبة لنموذج الذكاء الاصطناعي، فإن الصورة نفسها عبارة عن مصفوفة ضخمة من الأرقام. لا يوجد فهم مُدمج للطرق أو المباني أو الأشخاص. يكمن التحدي في التعرف على الصور في تعليم النظام كيفية تفسير هذه الأرقام بطريقة ذات معنى.
قبل بدء أي عملية تعلم، يتم تحويل الصورة إلى صيغة رقمية يمكن للنموذج معالجتها. وتؤثر الدقة وعمق الألوان وبنية الملف على كمية المعلومات المتاحة وعلى حجم العمليات الحسابية المطلوبة.
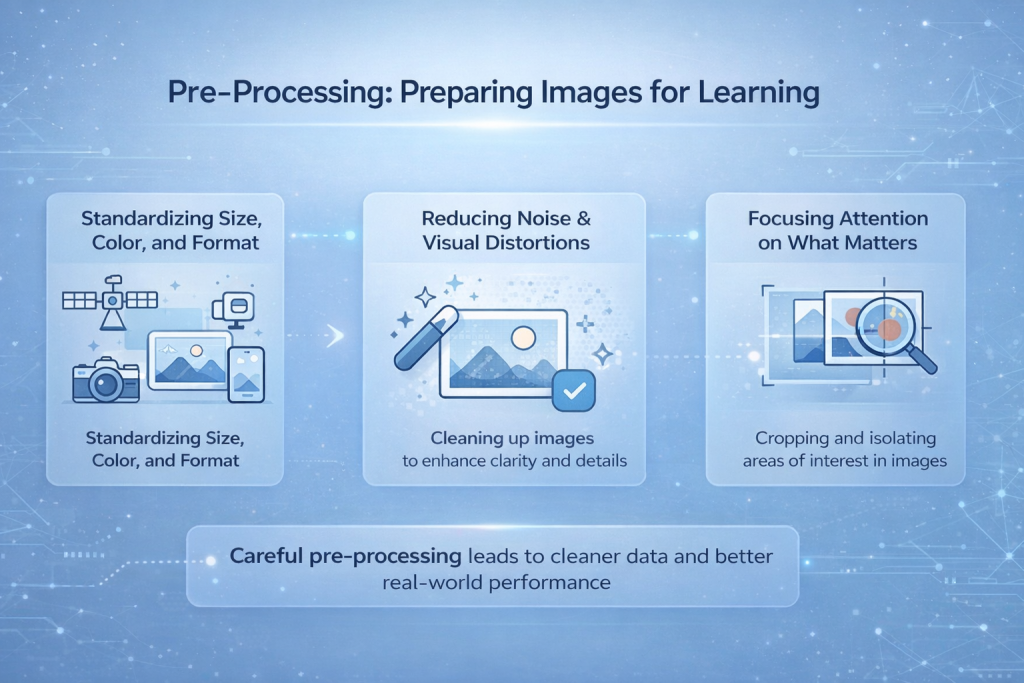
المعالجة المسبقة: تجهيز الصور للتعلم
الصور الملتقطة من الكاميرات أو الطائرات المسيّرة أو الأقمار الصناعية أو الهواتف لا تتسم بالاتساق في أغلب الأحيان. فهي تأتي بدقة وإضاءة وزوايا وتنسيقات ملفات مختلفة. بعضها واضح، والبعض الآخر مشوّش أو ضبابي. إدخال هذا المزيج الخام مباشرةً إلى النموذج يجعل عملية التعلّم غير مستقرة وغير قابلة للتنبؤ. المعالجة المسبقة هي الخطوة التي يتم فيها ضبط هذه الفوضى البصرية.
توحيد الحجم واللون والتنسيق
من أولى المهام توحيد الصور. تتوقع النماذج شكلاً ثابتاً للصور المدخلة، لذا يتم تغيير حجمها إلى دقة ثابتة. تُوحّد قيم الألوان بحيث لا تؤثر اختلافات السطوع والتباين سلباً على عملية التعلم. يساعد هذا النموذج على التركيز على البنية بدلاً من تشتيت انتباهه بتغيرات التعريض أو إعدادات الكاميرا.
تقليل الضوضاء والتشوهات البصرية
قد تُخفي التشويشات الناتجة عن أجهزة الاستشعار، وضبابية الحركة، وتشوهات الضغط، أو الظروف الجوية، تفاصيل مهمة. تُساعد تقنيات المعالجة المسبقة على تقليل هذه التأثيرات، مما يُسهّل على النموذج اكتشاف الحواف والأشكال. لا تُحسّن هذه الخطوة الصورة من الناحية البشرية، ولكنها تُحسّن من سهولة قراءة البيانات بالنسبة للشبكة.
تركيز الانتباه على ما يهم
في كثير من الحالات، لا يكون سوى جزء من الصورة ذا صلة. يساعد قصّ أو إخفاء أو عزل المناطق المهمة على إزالة العناصر المشتتة. من خلال الحدّ مما يراه النموذج، يصبح التعلّم أسرع وأكثر دقة، لا سيما في مهام مثل اكتشاف الأجسام أو التصوير الطبي.
لماذا تؤثر المعالجة المسبقة بشكل مباشر على الأداء في العالم الحقيقي
لا تجعل المعالجة المسبقة النموذج أكثر ذكاءً من تلقاء نفسها، بل تُهيئ ظروفًا أفضل للتعلم. عندما تُنفذ هذه الخطوة على عجل أو تُصمم بشكل سيئ، قد تُحقق النماذج أداءً جيدًا في الاختبارات المُحكمة، لكنها تفشل في المواقف الواقعية. غالبًا ما تكون المعالجة المسبقة الدقيقة هي الفرق بين نظام يعمل نظريًا ونظام يعمل عمليًا.
التعلم من خلال الميزات: كيف يكتشف الذكاء الاصطناعي الأنماط
يتعلم البشر التعرف على الأشياء من خلال ملاحظة خصائصها. تلعب الحواف والأشكال والملمس والنسب دورًا في ذلك. وتتعلم نماذج الذكاء الاصطناعي بطريقة مماثلة ولكنها أكثر رياضية.
تعتمد معظم أنظمة التعرف على الصور الحديثة على الشبكات العصبية الالتفافية، أو CNNs. صُممت هذه الشبكات لمسح الصور باستخدام مرشحات صغيرة تتحرك عبر الصورة وتكتشف الأنماط المحلية.
تميل الطبقات الأولى في الشبكة العصبية التلافيفية إلى اكتشاف ميزات بسيطة للغاية مثل الحواف والزوايا وتدرجات الألوان. أما الطبقات الوسطى فتجمع هذه الميزات لتكوين أشكال وقوام. وتقوم الطبقات الأعمق بتجميع هذه الأشكال في أنماط ذات مستوى أعلى تتوافق مع الكائنات أو المناطق ذات الأهمية.
الفكرة الأساسية هي التسلسل الهرمي. لا ينتقل النموذج مباشرة من البكسلات إلى "هذه شجرة". بل يبني هذا الفهم طبقة تلو الأخرى.
لماذا تُعدّ عملية الالتفاف مهمة؟
تتيح عملية الالتفاف تطبيق نفس كاشف الأنماط على كامل الصورة. فالحافة العمودية تظل حافة عمودية سواء ظهرت على الجانب الأيسر أو الأيمن من الصورة.
يجعل هذا النهج النماذج أكثر كفاءةً وقوة. فبدلاً من حفظ ترتيبات البكسلات بدقة، يتعلم النظام أنماطًا بصرية قابلة لإعادة الاستخدام. وهذا أحد أسباب نجاح الشبكات العصبية التلافيفية (CNNs) مع مختلف أحجام الصور وتنسيقاتها.
تُضاف طبقات التجميع عادةً لتقليل حجم البيانات مع الحفاظ على المعلومات المهمة. وهذا يساعد في التحكم في تكاليف الحساب ويمنع النموذج من أن يصبح شديد الحساسية للتغيرات الطفيفة.
تدريب النموذج: التعلم من الأمثلة
التدريب هو المرحلة التي يتم فيها التعرف على الصور فعلياً. يتم عرض مجموعة كبيرة من الصور المصنفة على النموذج. كل صورة تقترن بالإجابة الصحيحة، مثل "محصول سليم" أو "طريق متضرر" أو "شخص موجود".“
أثناء التدريب، تتبع العملية حلقة متكررة:
- يقوم النموذج بتحليل صورة مُدخلة ويُنتج تنبؤًا
- تتم مقارنة التوقع بالتصنيف الصحيح
- يُقاس الفرق بين الاثنين كخطأ
- يقوم النموذج بتعديل معاييره الداخلية لتقليل هذا الخطأ
- تتكرر العملية نفسها عبر آلاف أو ملايين الأمثلة
هذا التعديل التدريجي هو ما يسمح للنظام بالتحسن بمرور الوقت.
تُعدّ آلية الانتشار العكسي هي الآلية التي تجعل هذا التعلّم ممكناً. فهي تتعقب الأخطاء عكسياً عبر الشبكة وتُحدّث أوزان كل طبقة بحيث تصبح التنبؤات المستقبلية أكثر دقة.
تعتمد جودة التدريب بشكل كبير على البيانات المستخدمة. فإذا كانت مجموعة البيانات صغيرة جدًا، أو ذات تصنيف ضعيف، أو منحازة نحو ظروف معينة، فسيرث النموذج هذه العيوب. ولا يمكن لأي قدر من الضبط أن يعوض تمامًا عن جودة بيانات التدريب المنخفضة أو غير المتوازنة.
دور البيانات المصنفة
تُعدّ البيانات المصنفة أساس التعرف على الصور الخاضع للإشراف. كل تصنيف يُخبر النموذج بما يجب أن يتعلمه من الصورة.
غالباً ما يكون إنشاء هذه التصنيفات الجزء الأكثر تكلفةً واستهلاكاً للوقت في العملية. يجب على المصنفين البشريين تحديد الأشياء بدقة، ورسم مربعات محيطة، وتقسيم المناطق، أو تصنيف الصور.
تؤدي التعليقات التوضيحية عالية الجودة إلى نماذج أفضل، بينما تؤدي التعليقات التوضيحية الرديئة إلى الارتباك ونتائج غير موثوقة. ولهذا السبب، يمكن إرجاع العديد من حالات فشل التعرف على الصور إلى مجموعة البيانات وليس إلى الخوارزمية.
التعلم بالنقل والاستدلال: من نموذج مُدرَّب مسبقًا إلى تنبؤات حقيقية
يتطلب تدريب شبكة عصبية عميقة من الصفر كمية كبيرة من البيانات المصنفة وقدرة حاسوبية هائلة، ولهذا السبب لا تبدأ العديد من الفرق من الصفر. بدلاً من ذلك، يستخدمون التعلم بالنقل.
كيف يعمل التعلم الانتقالي
يبدأ التعلم بالنقل بنموذج سبق له أن تعلم السمات البصرية العامة من مجموعة بيانات كبيرة. يفهم هذا النموذج المدرب مسبقًا الأنماط الشائعة مثل الحواف والنسيج والأشكال. ومن ثم، يتم ضبطه بدقة لمهمة محددة باستخدام مجموعة بيانات أصغر تركز على المهمة.
عمليًا، تبقى الطبقات الأولى عادةً كما هي، بينما تُعاد تدريب الطبقات اللاحقة لتتوافق مع المهمة الجديدة. على سبيل المثال، يمكن تكييف نموذج مُدرَّب على صور عامة للتعرف على العيوب في المكونات الصناعية أو الأنماط في الفحوصات الطبية. يُسرِّع هذا النهج عملية التطوير ويُحسِّن الدقة غالبًا، خاصةً عندما تكون مجموعة البيانات محدودة.
من التدريب إلى الاستدلال
بمجرد تدريب النموذج أو ضبطه بدقة، ينتقل إلى وضع الاستدلال. في هذه المرحلة، يقوم بمعالجة صور جديدة لم يسبق رؤيتها من قبل، وينتج تنبؤات.
تُحاكي عملية الاستدلال عملية التدريب:
- تتم معالجة الصور مسبقًا
- يتم تمريرها عبر الشبكة
- يتم إرجاع المخرجات على شكل تصنيفات أو احتمالات أو كائنات مكتشفة أو مناطق مجزأة
عند هذه النقطة، تتغير الأولويات. لم يعد الهدف هو التعلم، بل الأداء المتسق. في الأنظمة الحقيقية، غالباً ما يتطلب الاستدلال العمل في الوقت الفعلي أو شبه الفعلي، لذا فإن السرعة والموثوقية لا تقل أهمية عن الدقة المطلقة.
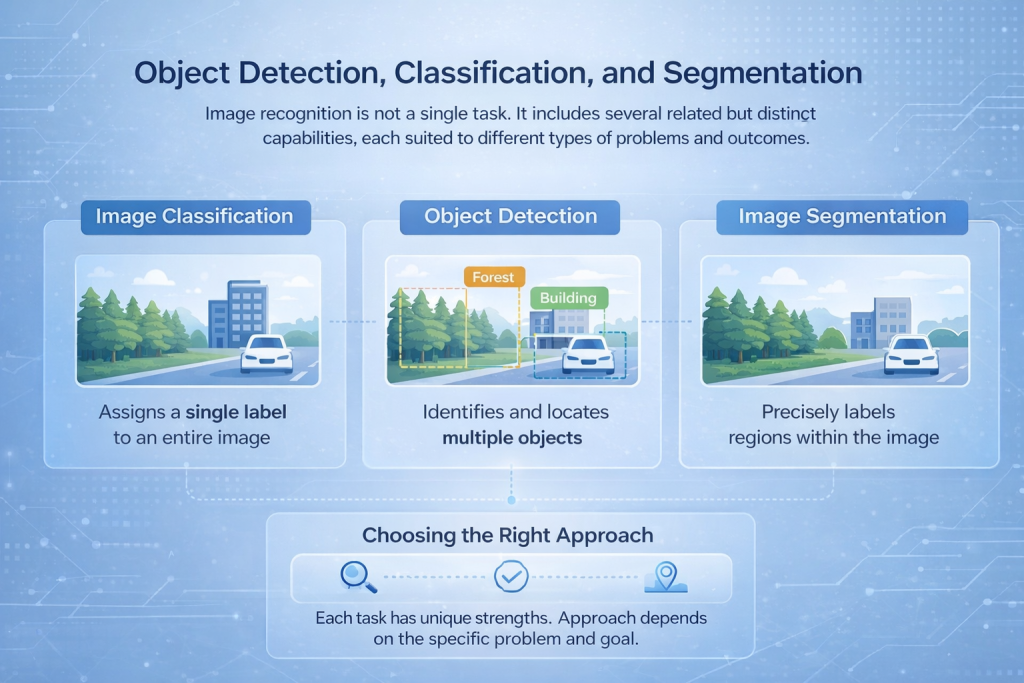
الكشف عن الأجسام وتصنيفها وتجزئتها
إن التعرف على الصور ليس مهمة واحدة. فهو يشمل العديد من القدرات المترابطة ولكنها متميزة، كل منها مناسب لأنواع مختلفة من المشكلات والنتائج.
تصنيف الصور
يُخصص تصنيف الصور تصنيفًا واحدًا للصورة بأكملها. ينظر النموذج إلى المشهد كاملًا ويحدد الوصف الأنسب له، كأن يُحدد ما إذا كانت الصورة تحتوي على غابة أو مبنى أو مركبة. يُعد هذا الأسلوب فعالًا عندما يكون المحتوى العام أهم من الموقع الدقيق.
Object Detection
تتجاوز تقنية الكشف عن الأجسام مجرد تحديد مواقع الأجسام المتعددة داخل الصورة نفسها. فبدلاً من تصنيفها بشكل منفرد، يقوم النموذج برسم مربعات حول العناصر المهمة وتصنيف كل منها على حدة. ويُستخدم هذا الأسلوب بشكل شائع في تطبيقات مثل مراقبة حركة المرور، وأنظمة الأمن، والتفتيش الصناعي.
تجزئة الصور
يُوفر التجزئة أعلى مستوى من التحليل، حيث يقوم بتصنيف وحدات البكسل أو المناطق الفردية داخل الصورة، مما يسمح للنظام بفصل الأجسام بدقة عالية. وهذا أمر بالغ الأهمية في تطبيقات مثل التصوير الطبي، ورسم خرائط استخدام الأراضي، وتحليل الأسطح، حيث تُعدّ الحدود الدقيقة أساسية.
اختيار النهج الصحيح
تتطلب كل مهمة من هذه المهام بنية شبكية واستراتيجيات تدريب مختلفة. ويعتمد الاختيار الأمثل على المشكلة المراد حلها، سواء كان الهدف هو عدّ المركبات، أو قراءة النصوص، أو رسم خرائط استخدام الأراضي بمستوى عالٍ من التفصيل.
قياس الأداء
يتم تقييم نماذج التعرف على الصور باستخدام مقاييس مثل الدقة، والضبط، والاستدعاء، ونسبة التقاطع إلى الاتحاد.
غالباً ما تكون الدقة وحدها مضللة. فقد يبدو نموذج نادراً ما يرصد جسماً ما دقيقاً لمجرد ندرة هذا الجسم. بينما توفر الدقة والاستدعاء صورة أوضح لمدى موثوقية النموذج.
ينبغي دائمًا إجراء الاختبار على بيانات لم يسبق للنموذج رؤيتها من قبل. يساعد هذا في الكشف عما إذا كان النظام قد تعلم أنماطًا عامة أم أنه حفظ مجموعة التدريب فقط.
التعقيد والتحيز والقيود العملية في العالم الحقيقي
يعمل نظام التعرف على الصور بالذكاء الاصطناعي بأفضل شكل في البيئات الخاضعة للتحكم، لكن البيئات الحقيقية نادراً ما تكون كذلك. وبمجرد خروج النماذج من المختبر ومواجهتها لظروف العالم الحقيقي، تصبح القيود أكثر وضوحاً.
لماذا يصعب نمذجة ظروف العالم الحقيقي
تتغير الإضاءة على مدار اليوم. تتداخل الأجسام أو تختفي جزئيًا عن الأنظار. يؤثر الطقس على الرؤية. تتحرك الكاميرات أو تتعطل أو تلتقط بيانات غير دقيقة. كل هذا يُدخل تشويشًا يجب على النماذج تعلم كيفية التعامل معه.
قد يواجه النظام الذي يحقق أداءً جيدًا في الاختبارات صعوباتٍ عند تراكم هذه المتغيرات. ولهذا السبب، يُعدّ الاختبار المستمر والمراقبة وإعادة التدريب عناصر أساسية في أي نظام إنتاجي، وليست تحسينات اختيارية.
دور الرقابة البشرية
يُعدّ التعرّف على الصور باستخدام الذكاء الاصطناعي تقنيةً قوية، لكنها ليست معصومة من الخطأ. في التطبيقات الحساسة للسلامة أو ذات التأثير الكبير، تبقى المراجعة البشرية ضرورية. يُقدّم البشر السياق والحكم والمساءلة في المواقف التي لا تكفي فيها القرارات الآلية وحدها.
كيف يتسلل التحيز إلى أنظمة التعرف على الصور
تتعلم النماذج مباشرةً من البيانات التي تُدرَّب عليها، بما في ذلك ثغراتها واختلالاتها. وإذا كانت بعض البيئات أو المجموعات السكانية أو الظروف ممثلة تمثيلاً ناقصاً، فسيتأثر الأداء سلباً في تلك الحالات.
يُصبح التحيز مشكلةً بالغة الخطورة في مجالاتٍ مثل المراقبة، والتحكم في الدخول، والسلامة العامة، حيث يمكن أن تُؤدي الأخطاء إلى عواقب وخيمة. ونادراً ما تكون هذه المشكلات ناتجةً عن الخوارزميات وحدها.
لماذا لا يُعدّ التحيز مشكلة تقنية بحتة؟
لا يوجد حل تقني واحد للتحيز. يتطلب تحسين العدالة والموثوقية ما يلي:
- مجموعات بيانات أكثر تنوعًا وتمثيلًا
- تقييم دقيق عبر سيناريوهات مختلفة
- مراجعة مستمرة لكيفية استخدام النماذج وتحديثها
إن التحيز في نهاية المطاف يمثل تحدياً يتعلق بالبيانات والعمليات. ويتطلب معالجته خيارات مدروسة، وليس مجرد نماذج أفضل.

اعتبارات الخصوصية والأخلاقية
غالباً ما تتضمن عملية التعرف على الصور بيانات حساسة. يمكن استنتاج الوجوه والمواقع والسلوكيات من الصور، أحياناً دون أن يكون الشخص المعني على دراية كاملة بذلك.
لا يقتصر الاستخدام المسؤول على الدقة التقنية فحسب، بل يتطلب قواعد واضحة وحدوداً واعية، بما في ذلك:
- سياسات شفافة لجمع البيانات واستخدامها
- الموافقة الصريحة عند التعامل مع البيانات الشخصية
- تخزين آمن وتحكم في الوصول إلى بيانات الصور
- الامتثال للوائح الخصوصية المحلية والدولية
- المساءلة الواضحة عن كيفية استخدام القرارات التي يتخذها النظام
إن الاعتبارات الأخلاقية ليست مجرد فكرة ثانوية. فهي تشكل ثقة الجمهور، والقبول القانوني، وما إذا كانت أنظمة التعرف على الصور ستظل قابلة للتطبيق على المدى الطويل.
لماذا يُعدّ التعرّف على الصور أمراً بالغ الأهمية؟
على الرغم من التحديات التي تواجهها، أصبحت تقنية التعرف على الصور بالذكاء الاصطناعي أداة بالغة الأهمية في مختلف القطاعات. فهي تُمكّن من أتمتة العمليات التي يكون فيها الفحص البشري بطيئًا أو مكلفًا أو غير متسق.
من التشخيصات الصحية إلى الزراعة، ومن مراقبة البنية التحتية إلى تجارة التجزئة، فإن القدرة على استخلاص رؤى من البيانات المرئية تغير طريقة اتخاذ القرارات.
لا تكمن القيمة الحقيقية في استبدال الحكم البشري، بل في تعزيزه. يتولى الذكاء الاصطناعي التعامل مع الحجم والسرعة، بينما يتولى البشر التعامل مع السياق والمسؤولية.
الخلاصة: من البكسلات إلى القرارات
يعمل نظام التعرف على الصور بالذكاء الاصطناعي لأنه يقسم القدرة البشرية المعقدة إلى خطوات يمكن التحكم بها. تتحول البكسلات إلى أرقام، والأرقام إلى أنماط، والأنماط إلى تنبؤات. لا توجد لحظة سحرية يفهم فيها الجهاز الصورة فجأة، بل عملية تعلم وتكرار وتحسين مستمرة.
يساعد فهم كيفية عمل هذه العملية على وضع توقعات واقعية. كما يساعد الفرق على بناء أنظمة أفضل، وطرح أسئلة أكثر دقة، واستخدام التكنولوجيا بمسؤولية أكبر. في النهاية، لا يتعلق التعرف على الصور بأن ترى الآلات كما يرى البشر، بل يتعلق بأن ترى الآلات بطريقة مختلفة، وأن تستخدم هذا الاختلاف لاتخاذ قرارات أسرع وأكثر اتساقًا في الأوقات الحاسمة.
الأسئلة الشائعة
التعرف على الصور باستخدام الذكاء الاصطناعي هو عملية تعليم الحاسوب كيفية تحديد الأنماط في الصور. وبدلاً من فهم الصور بالطريقة التي يفهمها بها البشر، يتعلم النظام من الأمثلة ويستخدم الأرقام والاحتمالات لتحديد ما ينظر إليه.
لا، لا يفهم الذكاء الاصطناعي الصور من الناحية المفاهيمية. فهو يعالج قيم البكسل ويتعلم الأنماط بناءً على العلاقات الإحصائية. قد تبدو النتائج مشابهة للإدراك البشري، لكن العملية مختلفة تمامًا.
تستخدم معظم أنظمة التعرف على الصور الحديثة التعلم العميق، وخاصة الشبكات العصبية الالتفافية. صُممت هذه النماذج لتعلم السمات البصرية مثل الحواف والأشكال والنسيج من خلال طبقات متعددة.
يعتمد ذلك على المهمة. قد تُناسب مسائل التصنيف البسيطة آلاف الصور، بينما تتطلب مهام الكشف أو التجزئة المعقدة عادةً عشرات أو مئات الآلاف من الأمثلة المصنفة. جودة البيانات لا تقل أهمية عن كميتها.
تُحدد التعليقات التوضيحية ما يجب أن يتعلمه النموذج من كل صورة. ويؤدي ضعف تصنيف الصور إلى تنبؤات ضعيفة. غالبًا ما يكون تصنيف الصور عالي الجودة هو الجزء الأكثر استهلاكًا للوقت في بناء نظام التعرف على الصور، ولكنه يؤثر بشكل مباشر على الدقة والموثوقية.