

قد يبدو التعرف على الصور معقدًا في البداية. الشبكات العصبية، ومجموعات البيانات، وحلقات التدريب، ووحدات معالجة الرسومات - قد يبدو الأمر معقدًا حتى قبل كتابة سطر واحد من التعليمات البرمجية. لكن في الواقع، بناء نظام ذكاء اصطناعي للتعرف على الصور يعتمد على اتخاذ قرارات سليمة خطوة بخطوة، بدلًا من إتقان كل شيء دفعة واحدة.
جوهر تقنية التعرف على الصور هو تعليم النظام كيفية ملاحظة الأنماط في الصور وإصدار أحكام متسقة بناءً على ما يراه. قد يشمل ذلك تحديد الأشياء، وتصنيف المشاهد، واكتشاف العيوب، أو الإشارة إلى الحالات الشاذة. التكنولوجيا الكامنة وراء هذه التقنية قوية، لكن العملية نفسها بسيطة للغاية: تحديد المهمة، وإعداد البيانات، وتدريب النموذج، واختباره بموضوعية، ثم استخدامه حيثما يكون مفيدًا بالفعل.
تشرح هذه المقالة هذه العملية بطريقة عملية ومباشرة. لا مبالغة، ولا اختصارات، ولا افتراضات بأنك بصدد كتابة بحث علمي. إنما نظرة واضحة على كيفية بناء الذكاء الاصطناعي للتعرف على الصور اليوم، وما يهم حقًا في كل مرحلة، وأين يقع الناس عادةً في الأخطاء.

ابدأ بمشكلة يمكنك وصفها بوضوح
قبل التعامل مع البيانات أو النماذج، أنت بحاجة إلى مهمة محددة بدقة. ليس "التعرف على الصور"، بل شيء ملموس.
- هل تقوم بتصنيف صورة كاملة ضمن فئة واحدة؟
- هل تقوم بالعثور على الأشياء ورسم مربعات حولها؟
- هل تقوم بتحديد الأشكال أو الحدود بدقة على مستوى البكسل؟
كل واحدة من هذه المشاكل مختلفة ولها تكاليف ومخاطر مختلفة.
تفشل العديد من المشاريع لأنها تبدأ غامضة وتصبح معقدة في وقت متأخر جدًا. إذا لم تستطع شرح هدفك في جملة واحدة لشخص غير متخصص، فهو غير جاهز بعد.
أمثلة جيدة
- “"الكشف عن الأضرار الظاهرة على ألواح هيكل السيارة من خلال الصور."”
- “"عدّ جذوع الأشجار المكدسة في الصور الجوية."”
- “"تحديد ما إذا كانت منطقة المحاصيل تُظهر إجهادًا مبكرًا."”
أمثلة سيئة
- “"استخدم الذكاء الاصطناعي لتحليل الصور."”
- “"قم ببناء رؤية حاسوبية ذكية."”
الوضوح هنا يوفر الوقت والجهد بعد أشهر.
فهم كيف تتحول الصور إلى أرقام
لا يرى الحاسوب الأشياء، بل يرى مصفوفات من الأرقام.
تُحوّل كل صورة إلى وحدات بكسل، وتُصبح كل وحدة بكسل عبارة عن قيم تُمثل شدة الإضاءة أو اللون. الصورة الملونة ليست صورةً بالنسبة للنموذج، بل هي شبكة من الأرقام عبر قنوات متعددة.
تعتمد تقنية التعرف على الصور على تعلم الأنماط الموجودة داخل تلك الأرقام، كالحواف والأشكال والنسيج والتباينات. ليس لأن النموذج يفهم المعنى، بل لأنه يجد أنماطًا إحصائية منتظمة ترتبط بالتصنيفات.
هذا الأمر مهم لأنه يغير طريقة تفكيرك في جودة البيانات. إذا فشل النموذج، فغالباً ما يكون ذلك بسبب أن الأرقام التي يراها غير متسقة أو مشوشة أو مضللة.
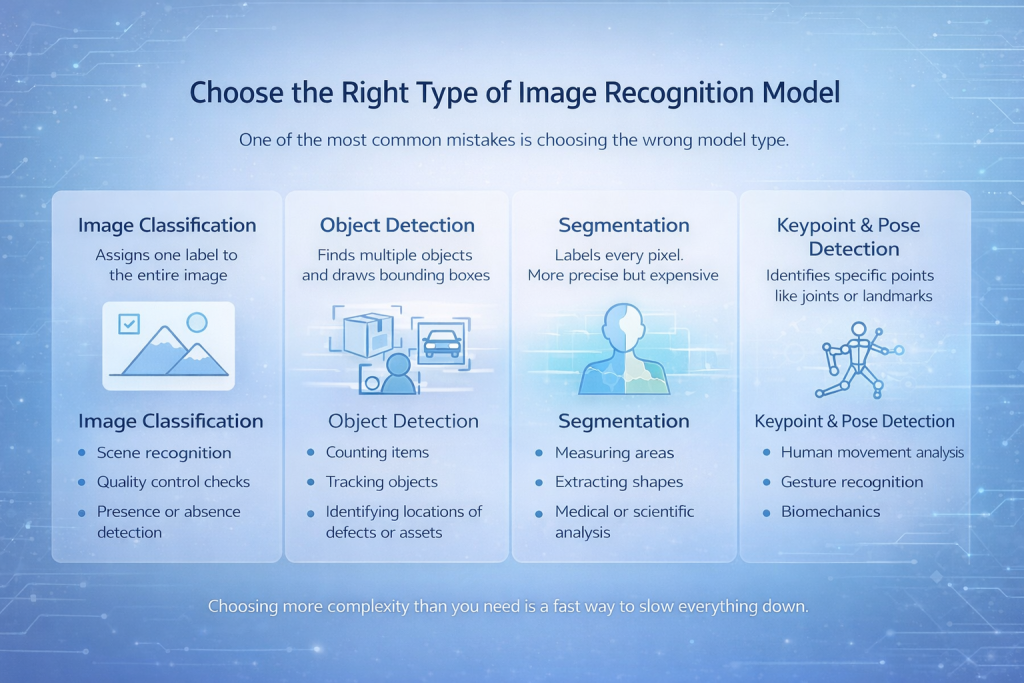
اختر النوع المناسب من نماذج التعرف على الصور
من أكثر الأخطاء شيوعاً اختيار نوع النموذج الخاطئ.
هناك عدة فئات أساسية:
تصنيف الصور
يُسند النموذج تصنيفًا واحدًا للصورة بأكملها. إنه بسيط وسريع وفعال عندما يكون العنصر محل الاهتمام هو العنصر المهيمن على الصورة.
الأفضل لـ:
- التعرف على المشهد
- فحوصات مراقبة الجودة
- الكشف عن الوجود أو الغياب
Object Detection
يجد النموذج عدة كائنات ويرسم مربعات محيطة بها.
الأفضل لـ:
- عدّ العناصر
- تتبع الكائنات
- تحديد مواقع العيوب أو الأصول
التجزئة
يتم وضع علامة على كل بكسل. هذا أكثر دقة وأكثر تكلفة.
الأفضل لـ:
- قياس المساحات
- استخراج الأشكال
- التحليل الطبي أو العلمي
اكتشاف النقاط الرئيسية والوضعيات
يحدد النموذج نقاطًا محددة مثل المفاصل أو المعالم.
الأفضل لـ:
- تحليل الحركة البشرية
- التعرف على الإيماءات
- الميكانيكا الحيوية
إن اختيار تعقيد أكثر مما تحتاج إليه هو طريقة سريعة لإبطاء كل شيء.
البيانات ليست مهمة فحسب، بل هي المشروع نفسه.
تحظى النماذج بالاهتمام، لكن البيانات هي التي تقوم بالعمل الحقيقي.
يعتمد نظام التعرف على الصور القوي بشكل أكبر على مجموعة البيانات أكثر من اعتماده على بنية النظام. حتى أكثر النماذج تطوراً ستفشل إذا كانت البيانات ضعيفة أو غير متسقة.
المبادئ الأساسية التي تهم فعلاً:
تنوع البيانات يتفوق على حجم البيانات
غالباً ما تكون عشرة آلاف صورة متشابهة أسوأ من ألفي صورة مختلفة. فالاختلاف في الزوايا، وظروف الإضاءة، والخلفيات، والدقة، وأنواع الأجهزة أهم من العدد الإجمالي للصور.
يجب أن تتطابق التصنيفات مع الواقع
إذا اختلف البشر حول التصنيفات، فسيتعلم النموذج الارتباك. لذا ينبغي دمج الفئات الغامضة أو إعادة تعريفها مبكراً.
التوازن مهم
إذا سيطرت فئة واحدة، تصبح الدقة مضللة. يمكن أن يكون النموذج "دقيقًا" من خلال تخمين الفئة الأكثر شيوعًا دائمًا.
تُحدد جودة المنتج أو تُفقد من خلال عملية التعليق.
غالبًا ما تتم عملية تصنيف الصور على عجل، وهذا يظهر لاحقًا. فالتصنيف الرديء يُسبب مشاكل يصعب اكتشافها أثناء التدريب، لكنها تصبح واضحة بشكل مؤلم عند الاستخدام الفعلي. تصبح النماذج غير مستقرة، وتبدو التنبؤات عشوائية، وتتراكم الحالات الشاذة. كل صورة مصنفة بشكل خاطئ تُفسد عملية التعلم تدريجيًا.
تبدأ عملية التوصيف الجيدة بقواعد تصنيف واضحة يلتزم بها الجميع. عندما يفسر الأشخاص المختلفون التصنيفات بشكل مختلف، يتعلم النموذج الارتباك بدلاً من الأنماط. يُعدّ الاتساق بنفس أهمية الدقة، ولهذا السبب تُعدّ عمليات الفحص العشوائي والتدقيق الصغيرة المنتظمة ضرورية. فهي تساعد على اكتشاف الانحراف مبكراً، قبل أن ينتشر في مجموعة البيانات.
يحتاج نظام التعليقات التوضيحية أيضًا إلى مساحة للتطور. فمع ظهور حالات استثنائية جديدة، ينبغي تحسين التصنيفات بدلًا من إجبارها على تعريفات لم تعد مناسبة. هذا النوع من التنظيف التكراري بطيء، ولكنه يؤتي ثماره في استقرار النموذج.
يمكن لأدوات تصنيف البيانات المدعومة بالذكاء الاصطناعي تسريع العمليات، خاصةً مع مجموعات البيانات الضخمة، لكنها لا تغني عن التقييم البشري. فهي ببساطة تُكرر المنطق المُعطى لها. وإذا كانت القواعد غير واضحة أو معيبة، فإن الأتمتة ستُفاقم الخطأ، ولن تُصلحه.
المعالجة المسبقة ليست تجميلية
لا تقتصر المعالجة المسبقة على جعل الصور تبدو أنيقة فحسب، بل تتعلق أيضاً بتقليل التباين غير المرغوب فيه وإبراز ما يهم.
خطوات شائعة تساعد بالفعل:
- تغيير حجم الصور للحصول على دقة ثابتة
- تطبيع قيم البكسل
- تصحيح الوضعية
- زراعة المناطق غير ذات الصلة
يستحقّ تحسين البيانات اهتماماً خاصاً. فالتحويلات البسيطة كالتدوير والقلب وتغيير السطوع أو إضافة التشويش يمكن أن تُحسّن التعميم بشكلٍ كبير. والهدف ليس خداع النموذج، بل إعداده للواقع.
إذا بدت بياناتك مثالية للغاية، فسوف يصاب نموذجك بالذعر في العالم الحقيقي.
هندسة النماذج أقل أهمية مما تعتقد
هناك إغراء قوي لاتباع أحدث طراز أو أكثرها رواجاً. قد تبدو المحولات والشبكات الضخمة وخطوط الأنابيب المعقدة مثيرة للإعجاب على الورق، لكنها لا تضمن نتائج أفضل.
في الواقع، تعتمد العديد من أنظمة التعرف على الصور الموثوقة على بنى راسخة. ولا تزال الشبكات العصبية الالتفافية تهيمن على هذا المجال لسبب وجيه، فهي مستقرة وفعالة، ويسهل فهمها عند حدوث أي خلل. وغالبًا ما تكون هذه الموثوقية أهم من مجرد تحسين الأداء بنسبة ضئيلة في اختبارات الأداء.
يُعدّ التعلّم بالنقل عادةً نقطة البداية الأمثل. فاستخدام نموذج سبق له التعلّم من مجموعات بيانات كبيرة ومتنوعة يمنحك أساسًا متينًا، خاصةً عندما تكون بياناتك محدودة. ويُحقق الضبط الدقيق أفضل النتائج عندما تكون المهمة الجديدة قريبة نسبيًا مما رآه النموذج سابقًا، وعندما يتم التحكم بفعالية في فرط التخصيص، وعندما تتم إعادة التدريب بعناية لا بشكل مفرط. فالتعديلات الصغيرة والمدروسة عادةً ما تتفوق على إعادة التدريب العشوائية.
النماذج الأكبر ليست بالضرورة أفضل. فهي تتطلب تكلفة تدريب أعلى، ويصعب تصحيح أخطائها، وغالباً ما تفشل بطرق خفية يصعب تتبعها.
التدريب عبارة عن حوار متكرر مع بياناتك
التدريب ليس عملية تتم بنقرة واحدة، بل هو عملية مستمرة.
تقوم بالتدريب، ومراقبة النتائج، وتحديد أنماط الفشل، وتعديل البيانات أو المعايير، ثم تكرر العملية.
ممارسات التدريب الرئيسية:
- استخدم مجموعات تدريب وتحقق واختبار منفصلة
- راقب منحنيات الخسارة، وليس فقط الدقة. ...
- توقف عن التدريب عندما يتوقف التحسن
- اضبط معدل التعلم وحجم الدفعة بعناية
لا يُعدّ تسريع معالجة الرسومات (GPU) خيارًا ثانويًا في المشاريع الجادة. صحيح أن التدريب على وحدات المعالجة المركزية (CPU) مناسب للتعلم، لكنه غير عملي للمشاريع الحقيقية. تُقلّل وحدات معالجة الرسومات من وقت التكرار، مما يُحسّن جودة النموذج بشكل مباشر من خلال تمكين التجريب.
يجب أن يتجاوز التقييم مجرد الدقة
تُعدّ الدقة من أسهل المقاييس حساباً، ومن أسهلها أيضاً سوء فهماً. فقد يبدو النموذج دقيقاً للغاية، ولكنه مع ذلك يكون عديم الفائدة في ظروف العالم الحقيقي.
التقييم الجيد يتطلب بحثًا معمقًا. تساعد مصفوفات الارتباك في الكشف عن مواطن الخطأ المتكررة في النموذج. وتُعدّ دقة الاستدعاء والاستدعاء أكثر دلالةً عند عدم توازن الفئات أو عندما تكون بعض الأخطاء أكثر تكلفة من غيرها. غالبًا ما يكشف الاختبار على صور جديدة تمامًا من العالم الحقيقي عن مشكلات لا تظهر أبدًا في بيانات التحقق النظيفة.
تظل المراجعة اليدوية أهم خطوة تقييمية. فالنظر مباشرةً إلى التنبؤات الفاشلة والتساؤل عن أسبابها يُتيح رؤىً لا يمكن لأي مقياس أن يُغطيها بالكامل. وتُظهر النماذج شفافيةً مُدهشةً بشأن نقاط ضعفها إذا ما خصصت وقتًا لدراسة أخطائها بدلًا من الاعتماد على الأرقام الإجمالية.
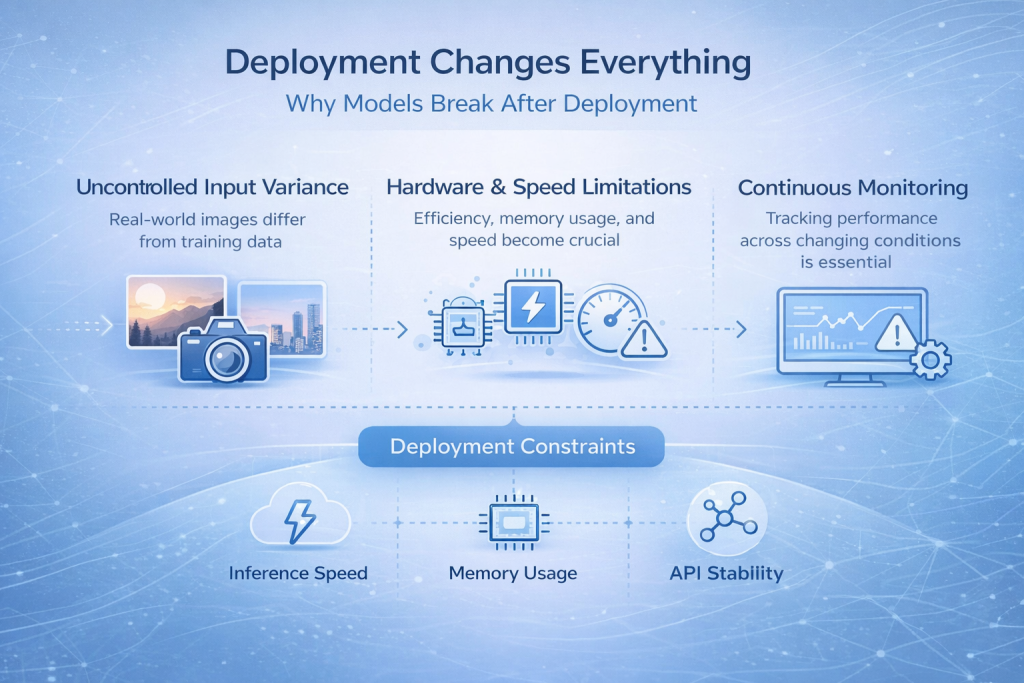
يُغيّر الانتشار كل شيء
لماذا تتعطل النماذج بعد النشر؟
تُحقق العديد من نماذج التعرف على الصور أداءً جيدًا أثناء التطوير، ثم تنهار تمامًا بعد نشرها. تُعد هذه إحدى أكثر اللحظات شيوعًا وإحباطًا في العملية برمتها.
السبب بسيط. نادرًا ما تتشابه مدخلات العالم الحقيقي مع بيانات التدريب. فالصور تأتي من كاميرات مختلفة، وتتغير ظروف الإضاءة على مدار اليوم، وتظهر تشوهات ناتجة عن الضغط، ولا يتبع المستخدمون أنماط استخدام مثالية. حتى التغييرات الطفيفة في كيفية التقاط الصور قد تدفع النموذج إلى خارج النطاق الذي تعلم العمل فيه.
ما بدا مستقراً في بيئة خاضعة للرقابة يصبح فجأة غير موثوق به.
القيود التي لا يمكنك تجاهلها
يُجبرك النشر على التفكير بما يتجاوز دقة النموذج. تصبح سرعة الاستدلال بالغة الأهمية عند الحاجة إلى التنبؤات في الوقت الفعلي. كما أن استخدام الذاكرة مهم عند تشغيل النموذج على أجهزة طرفية أو أجهزة محمولة. وتفرض قيود الأجهزة أنواع البنى الممكنة، ويصبح استقرار واجهة برمجة التطبيقات (API) ضروريًا عندما تعتمد أنظمة أخرى على تنبؤاتك.
كما أن المراقبة تتحول من ميزة إضافية إلى ضرورة حتمية. فبدون رؤية واضحة لكيفية عمل النموذج بعد إصداره، قد تمر الأعطال دون أن يلاحظها أحد حتى ينهار نظام الثقة.
جعل النموذج قابلاً للاستخدام
إن تصدير النموذج إلى صيغ مثل TensorFlow Lite أو ONNX ليس مجرد خطوة تقنية في نهاية مسار المعالجة، بل هو جزء أساسي من تحويل النموذج المدرب إلى نموذج قابل للاستخدام الفعلي في بيئة الإنتاج. تساعد هذه الصيغ على تكييف النموذج مع بيئات مختلفة، وتقليل النفقات العامة، وتحسين التوافق مع أهداف النشر.
النموذج الذي يعمل بكفاءة على جهاز كمبيوتر محمول ولكنه لا يصمد أمام النشر لا يُعتبر نموذجاً مكتملاً. لا يتحقق النجاح الحقيقي إلا عندما يعمل النظام باستمرار في المكان المُصمم لاستخدامه فيه.
التعرف على الصور في العالم الحقيقي: كيف نبنيه في شركة FlyPix AI
في فلاي بيكس الذكاء الاصطناعي, لا نتعامل مع تقنية التعرف على الصور كتمرين معملي. فنحن نعمل يومياً مع صور الأقمار الصناعية والصور الجوية وصور الطائرات المسيّرة، حيث تكون المشاهد كثيفة، والأجسام متداخلة، والظروف غير مثالية أبداً. هذا الواقع هو ما يُحدد كيفية بناء واستخدام الذكاء الاصطناعي.
لطالما كان هدفنا بسيطًا: إزالة عائق التحليل البصري اليدوي. كانت الفرق تقضي مئات الساعات في إضافة التعليقات التوضيحية إلى الصور، والتحقق من النتائج، وإعادة التحقق منها كلما تغيرت الظروف. لقد طورنا FlyPix لأتمتة هذا العمل باستخدام وكلاء الذكاء الاصطناعي القادرين على اكتشاف الأجسام ومراقبتها وفحصها على نطاق واسع، دون المساس بالدقة.
الأهم بالنسبة لنا هو التطبيق العملي. لا ينبغي أن تحتاج إلى معرفة متعمقة بالذكاء الاصطناعي أو فريق من مهندسي تعلم الآلة لتدريب نموذج يناسب احتياجاتك. مع FlyPix، يمكن للفرق إنشاء نماذج مخصصة للتعرف على الصور باستخدام بياناتهم الخاصة، مع التركيز على العناصر المهمة في مجال عملهم. مواقع البناء، والموانئ، والأراضي الزراعية، وأصول البنية التحتية، والمناطق الحرجية - تختلف الصور، لكن التحدي واحد.
نصمم كل شيء مع مراعاة سهولة النشر. تتغير البيانات الجغرافية المكانية في العالم الحقيقي باستمرار، لذا يجب أن تتعامل النماذج مع هذا التغير منذ البداية. وهذا يعني بناء أنظمة تعمل بكفاءة عالية خارج بيئات العرض التجريبية، وتعالج كميات كبيرة من الصور بسرعة، وتقدم نتائج يمكن للفرق العمل الاستفادة منها فورًا. بالنسبة لنا، لا ينجح التعرف على الصور إلا إذا أثبت فعاليته في العمليات اليومية، وليس فقط أثناء الاختبار.
حلقات التغذية الراجعة تحافظ على استمرارية النموذج
إن الذكاء الاصطناعي للتعرف على الصور ليس ثابتاً. تتغير البيانات. وتتغير البيئات. وتتغير التوقعات.
الأنظمة التي تدوم طويلاً تُصمم مع مراعاة التغذية الراجعة:
- قم بجمع صور جديدة بعد النشر
- حالات فشل المسار
- أعد التدريب بشكل دوري
- قم بتعديل التسميات عندما يتغير الواقع
إن تجاهل التعلم بعد النشر هو أحد أسرع الطرق لفقدان الثقة في النظام.
استنتاج
إن بناء نظام ذكاء اصطناعي فعال للتعرف على الصور لا يعتمد على ملاحقة أحدث النماذج بقدر ما يعتمد على إتقان الأساسيات. فالتحديد الواضح للمشكلة، والعمل المنظم على البيانات، والتقييم المدروس، والتخطيط الواقعي للتطبيق، كلها أمورٌ أهم بكثير من اختيار أي خوارزمية منفردة.
ليست الأنظمة الأكثر موثوقية هي الأكثر تعقيداً، بل هي تلك التي تُبنى على فهم دقيق لكيفية تغير الصور في العالم الحقيقي وكيفية تفاعل النماذج مع هذه التغيرات. تُدرَّب هذه الأنظمة على بيانات تعكس الواقع، وتُقيَّم بمقاييس تكشف نقاط الضعف، وتُطبَّق مع مراعاة القيود منذ البداية.
إذا كان هناك درسٌ واحدٌ يجب استخلاصه، فهو التالي: إنّ التعرّف على الصور عمليةٌ هندسيةٌ، وليست تجربةً لمرةٍ واحدة. عندما تتعامل معها بهذه الطريقة، وتُجري عليها تحسيناتٍ دقيقة، وتلتزم بالاستخدام الفعلي، فإنّ النتائج تميل إلى أن تبقى فعّالةً لفترةٍ طويلةٍ بعد انتهاء العرض التوضيحي.
التعليمات
يُعدّ الذكاء الاصطناعي للتعرف على الصور نوعًا من أنظمة رؤية الحاسوب التي تتعلم تحديد الأنماط أو الأشياء أو السمات في الصور. ويعمل هذا النظام من خلال تحليل بيانات البكسل واستخدام نماذج مُدرّبة لربط الأنماط المرئية بالتصنيفات أو النتائج.
ليس دائمًا. فبينما تُساعد مجموعات البيانات الكبيرة، إلا أن التنوع والجودة أهم من الحجم الخام. وباستخدام التعلم بالنقل والتوسيع المناسب للبيانات، يُمكن تدريب نماذج مفيدة على مجموعات بيانات صغيرة نسبيًا ولكنها مُنسقة جيدًا.
في معظم المشاريع، يُعد البدء بشبكة عصبية التفافية مُثبتة وتطبيق التعلم بالنقل نهجًا آمنًا وفعالًا. ولا ينبغي استخدام نماذج أكثر تعقيدًا إلا عند وجود سبب واضح وبيانات كافية تدعمها.
الدقة وحدها لا تكفي. ينبغي النظر إلى مصفوفات الارتباك، والدقة، والاستدعاء، واختبار النموذج على صور من العالم الحقيقي لم تُستخدم في التدريب. غالبًا ما تكون المراجعة اليدوية للأخطاء هي الخطوة الأكثر كشفًا.
يحدث هذا عادةً لأن صور الإنتاج تختلف عن بيانات التدريب. فالتغيرات في الإضاءة، وجودة الكاميرا، وضغط الصور، أو سلوك المستخدم، كلها عوامل قد تؤثر على الأداء. هذا التباين شائع ويجب مراعاته أثناء عملية التطوير.
نعم. النشر ليس خطوة نهائية يمكن تجاهلها حتى النهاية. فمحدودية الأجهزة، وسرعة الاستدلال، واستخدام الذاكرة، ومتطلبات التكامل، كلها تؤثر على كيفية بناء النموذج وتدريبه.