

Resumen rápido: Amazon Rekognition es el servicio de visión artificial totalmente administrado de AWS que utiliza aprendizaje profundo para analizar imágenes y videos sin necesidad de conocimientos especializados en aprendizaje automático. Ofrece API preentrenadas para detección facial, reconocimiento de objetos, extracción de texto, moderación de contenido y entrenamiento de etiquetas personalizadas. El servicio se escala automáticamente y cobra según el volumen, a partir de 1 TP4T0.00001 por imagen para el primer millón procesado.
Amazon Rekognition se lanzó en 2016 como la respuesta de AWS a la creciente necesidad de tecnología de visión artificial accesible. Está diseñado para resolver un problema específico: la mayoría de los desarrolladores necesitan capacidades de análisis de imágenes y vídeo, pero no tienen el tiempo, el presupuesto ni la experiencia necesarios para crear modelos de aprendizaje automático desde cero.
El servicio funciona completamente en la nube. Envías imágenes o vídeos mediante llamadas a la API, y Rekognition devuelve datos estructurados sobre lo que ha detectado: rostros, objetos, texto, contenido inapropiado, o cualquier otra cosa que estés buscando.
Sin embargo, hay algo importante: Rekognition no es una herramienta monolítica. En realidad, es un conjunto de API especializadas, cada una de las cuales maneja diferentes tareas de visión artificial.
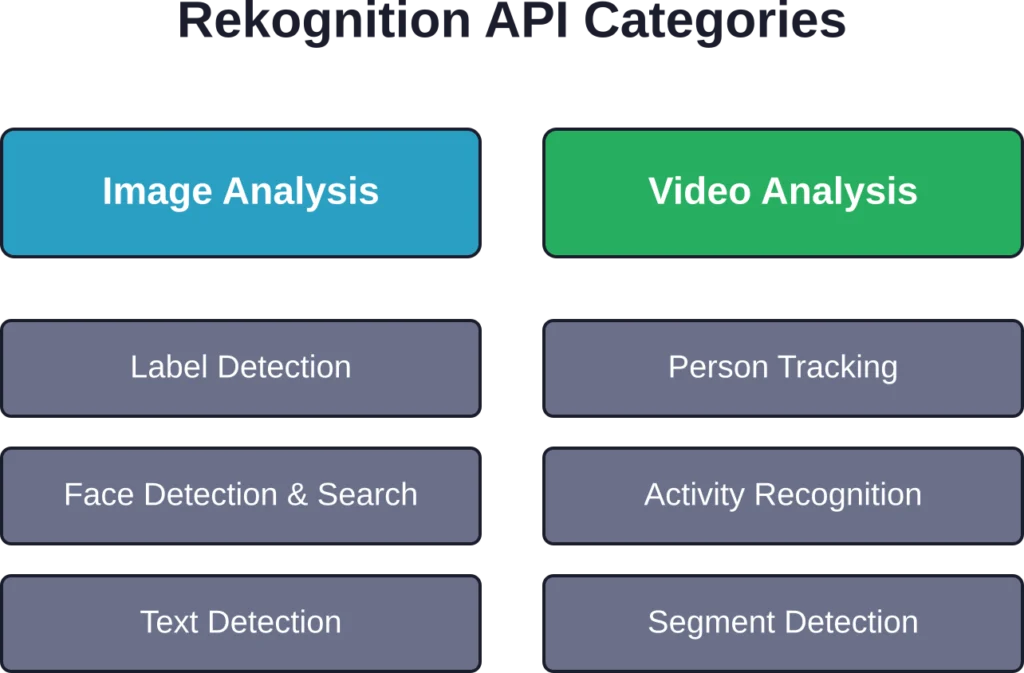
Capacidades principales y categorías de API
Rekognition divide sus funciones en dos categorías principales: análisis de imágenes y análisis de vídeo. Cada categoría contiene varias API especializadas.
Características de análisis de imágenes
El módulo de análisis de imágenes procesa imágenes estáticas. Según la documentación oficial, para una detección fiable, los objetos y rostros deben tener al menos 51 TP3T de la dimensión más corta de la imagen. Para una imagen de 1600 × 900 píxeles, esto equivale a un mínimo de 45 píxeles.
La detección de etiquetas identifica objetos, escenas, actividades y conceptos dentro de las imágenes. Devuelve puntuaciones de confianza para cada detección, que suelen oscilar entre 0 y 100. La moderación de contenido analiza si hay contenido inapropiado o no deseado en múltiples categorías.
La detección y el análisis facial pueden identificar rostros en imágenes y extraer atributos como el rango de edad estimado, el género percibido, las emociones y si la persona parece llevar gafas. La comparación facial mide la similitud entre dos rostros, mientras que la búsqueda facial compara los rostros detectados con una colección almacenada.
La detección de texto extrae texto impreso y manuscrito de imágenes, lo que resulta útil para el procesamiento de documentos, el reconocimiento de señales de tráfico y aplicaciones similares.
Características de análisis de vídeo
El análisis de vídeo funciona de forma diferente. Se pueden procesar vídeos almacenados de forma asíncrona o analizar vídeos en tiempo real. El sistema detecta personas, rastrea sus movimientos, reconoce objetos y actividades, e identifica los cambios de escena.
Para la detección de segmentos, puede filtrar los resultados por umbral de confianza. Un filtro de confianza mínima 70% se usa comúnmente para equilibrar la precisión y la cobertura.
Pero un momento. A partir del 30 de abril de 2026, Amazon dejó de ofrecer el Análisis de vídeo en streaming y la Moderación de contenido de imágenes por lotes a los nuevos clientes. Los usuarios actuales que hayan accedido a estas funciones en los últimos 12 meses conservarán el acceso, pero las nuevas cuentas no podrán activarlas.
Detección de vitalidad facial
Face Liveness es la solución de Rekognition para combatir los ataques de suplantación de identidad. Esta función analiza vídeos cortos grabados con una selfie para determinar si se trata de una persona real o si alguien está utilizando una foto, un vídeo pregrabado, una máscara 3D o un deepfake.
Detecta ataques de presentación (fotos impresas, pantallas digitales, máscaras de papel mostradas a la cámara) y ataques de evasión (vídeos pregrabados o sintéticos insertados en la secuencia de vídeo). El sistema devuelve una puntuación de confianza configurable de 0 a 100.
Esta funcionalidad se integra con aplicaciones web React, aplicaciones nativas de iOS y aplicaciones nativas de Android. No requiere gestión de infraestructura, ya que AWS se encarga de todo.
Etiquetas personalizadas para reconocimiento especializado
Los modelos preentrenados funcionan bien para casos de uso general. Pero ¿qué ocurre en escenarios especializados, como la detección de modelos de vehículos específicos, la identificación de defectos de fabricación o el reconocimiento de productos patentados?
Aquí es donde entran en juego las etiquetas personalizadas. Usted proporciona imágenes de entrenamiento etiquetadas con sus categorías personalizadas, y Rekognition crea un modelo adaptado a sus necesidades específicas de reconocimiento. Las mejoras recientes permiten crear modelos de calidad con menos datos de entrenamiento que antes.
Ahora, siete nuevas API permiten la creación programática de modelos, la gestión de conjuntos de datos y la automatización del flujo de trabajo de entrenamiento.
Aplique análisis de imágenes geoespaciales con FlyPix AI.
Amazon Rekognition se utiliza para el análisis de imágenes y vídeos en tareas generales de visión artificial. FlyPix AI Trabaja en un área más específica, ayudando a los equipos a analizar imágenes satelitales, de drones y aéreas para detectar objetos, segmentar ubicaciones y monitorear cambios visibles en sitios del mundo real.
FlyPix AI puede admitir tareas de análisis de imágenes basadas en la ubicación, tales como:
- Detección de objetos visibles, carreteras, edificios, vehículos, vegetación o infraestructura.
- Segmentación de áreas cartografiadas como tierra, agua, campos y zonas edificadas.
- Revisión de los cambios en las imágenes satelitales, de drones o aéreas a lo largo del tiempo.
- Creación de modelos de IA personalizados para tareas de detección geoespacial
Contacta con FlyPix AI para analizar cómo el análisis de imágenes geoespaciales puede respaldar su flujo de trabajo de revisión visual basado en la ubicación.
Estructura de precios y gestión de costes
Rekognition utiliza precios escalonados basados en el volumen mensual. La estructura cambió significativamente: AWS simplificó los niveles y redujo los precios hasta en 38% para usuarios de alto volumen.
| Nivel de precios | Volumen (imágenes/mes) | Precio por imagen de las API del Grupo 1 |
|---|---|---|
| Nivel 1 | El primer millón | $0.00001 |
| Nivel 2 | Próximos 4 millones | $0.00008 |
| Nivel 3 | Los próximos 30 millones | $0.00006 |
| Nivel 4 | Más de 35 millones | $0.00004 |
Las API del Grupo 1 incluyen las funciones más comunes: AssociateFaces, CompareFaces, DisassociateFaces, IndexFaces, SearchFacesbyImage, SearchFaces, SearchUsersByImage y SearchUsers. Las API del Grupo 2 incluyen DetectFaces, DetectModerationLabels, DetectLabels, DetectText y RecognizeCelebrities, con estructuras de precios independientes.
El almacenamiento de vectores faciales cuesta $0.00001 por metadatos faciales al mes. El análisis de vídeo utiliza precios por minuto en lugar de por imagen.
¿La respuesta corta? Para un uso moderado, los costos se mantienen bastante manejables.
Umbrales de confianza y precisión
Cada detección que realiza Rekognition incluye una puntuación de confianza. Comprender cómo establecer umbrales adecuados es fundamental para las aplicaciones prácticas.
Para aplicaciones fotográficas informales que identifican a miembros de la familia, un umbral de alrededor de 80% suele funcionar bien. Los escenarios de seguridad de alto riesgo requieren estándares más estrictos, a menudo 99% o superiores, para minimizar las coincidencias falsas.
Las investigaciones sobre la tecnología de reconocimiento facial demuestran que su rendimiento varía significativamente según la calidad de la imagen, la iluminación, el ángulo y los factores demográficos. El rendimiento en situaciones reales depende de estas condiciones.
Los informes de investigación indican que la identificación errónea mediante reconocimiento facial ha contribuido a detenciones injustas en casos documentados, lo que subraya la importancia de utilizar estas herramientas como ayudas para la investigación y no como prueba definitiva.
Integración y control de acceso
Rekognition se integra con AWS Identity and Access Management (IAM) para el control de acceso. Las políticas definen qué usuarios y aplicaciones pueden llamar a qué API, lo que garantiza que solo los sistemas autorizados accedan a las capacidades de análisis visual.
El servicio funciona mediante los SDK estándar de AWS disponibles para Python, JavaScript, Java, .NET y otros lenguajes. También se ofrece acceso a la API REST para integraciones personalizadas.
Usted conserva la propiedad total del contenido enviado a Rekognition. AWS utiliza sus datos únicamente con su consentimiento explícito y de acuerdo con su configuración.
Casos de uso comunes
En realidad, la adopción de Rekognition abarca diversos sectores. Las empresas de medios la utilizan para catalogar automáticamente sus archivos de vídeo. Las aplicaciones de seguridad emplean el reconocimiento facial para la verificación de identidad. Las plataformas de comercio electrónico detectan productos en las imágenes subidas por los usuarios.
Las plataformas de redes sociales utilizan la moderación de contenido para filtrar imágenes inapropiadas a gran escala. Las operaciones de fabricación utilizan etiquetas personalizadas para detectar defectos en las líneas de montaje. Los flujos de trabajo de procesamiento de documentos extraen texto de formularios y recibos escaneados.
El condado de Washington, en Oregón, adoptó Rekognition para las búsquedas faciales policiales. Según el Washington Post, en 2019 el condado pagaba alrededor de 1047 dólares al mes por todas sus búsquedas. En 2018, la agencia registró más de 1000 búsquedas faciales.
Consideraciones técnicas
El rendimiento se adapta automáticamente: analizar millones de imágenes o secuencias de vídeo en segundos se convierte en algo rutinario. No se requiere aprovisionamiento de infraestructura; AWS se encarga de la gestión de la capacidad.
La latencia varía según la operación. La detección simple de etiquetas suele completarse en menos de un segundo. El análisis de vídeo del contenido almacenado se procesa de forma asíncrona, y los resultados están disponibles mediante devolución de llamada o sondeo.
El sistema funciona mejor con imágenes nítidas y bien iluminadas, donde los sujetos ocupen una porción razonable del encuadre. Los ángulos extremos, la mala iluminación o las imágenes muy comprimidas reducen la precisión.
Documentación y recursos para desarrolladores
AWS proporciona documentación completa que abarca descripciones generales de conceptos, referencias de API y guías de implementación. Existen guías para desarrolladores independientes para las funciones estándar de Rekognition y las etiquetas personalizadas.
Para empezar, normalmente se requiere crear una cuenta de AWS, configurar los permisos de IAM, instalar un SDK y realizar la primera llamada a la API con una imagen de ejemplo. La documentación incluye código de ejemplo para escenarios comunes.
Preguntas frecuentes
Amazon Rekognition analiza imágenes y vídeos para detectar objetos, rostros, texto, contenido inapropiado y categorías personalizadas. Entre sus aplicaciones se incluyen sistemas de seguridad, catalogación de medios, moderación de contenido, procesamiento de documentos y reconocimiento de productos.
El precio inicial es de $0.00001 por imagen para el primer millón de imágenes procesadas mensualmente con las API del Grupo 1. Los costos disminuyen a $0.00004 por imagen para volúmenes superiores a 35 millones mensuales.
No. Rekognition ofrece API preentrenadas que funcionan sin necesidad de conocimientos de aprendizaje automático. Se envían imágenes o vídeos mediante llamadas a la API y se reciben resultados de detección estructurados. Las etiquetas personalizadas requieren datos de entrenamiento etiquetados, pero la creación del modelo se realiza automáticamente.
La precisión depende de la configuración del umbral de confianza y de la calidad de la imagen. Para aplicaciones fotográficas, un nivel de confianza de 80% es suficiente para la identificación de familiares. Las aplicaciones de seguridad de alto riesgo suelen requerir un nivel de confianza de 99%. El rendimiento varía según la iluminación, el ángulo y los factores demográficos.
Para una detección fiable, los objetos y rostros deben tener al menos 51 × 3 × 10 píxeles de la dimensión más corta de la imagen. En una imagen de 1600 × 900 píxeles, esto significa un mínimo de 45 píxeles. Los sujetos más pequeños podrían no detectarse de forma consistente.
La función de detección de rostros reales identifica específicamente los intentos de suplantación de identidad, incluyendo fotos impresas, pantallas digitales, máscaras 3D, videos pregrabados y deepfakes. Analiza videos cortos tipo selfie y devuelve puntuaciones de confianza que indican si hay una persona real presente.
Sí, para los clientes actuales, pero el análisis de vídeo en streaming ya no estará disponible para las nuevas cuentas a partir del 30 de abril de 2026. El análisis de vídeo almacenado seguirá estando totalmente disponible para todos los usuarios, procesando vídeos de forma asíncrona y detectando objetos, personas, actividades y cambios de escena.
Amazon Rekognition satisface una clara necesidad de capacidades de visión artificial accesibles. La combinación de modelos preentrenados, precios flexibles e infraestructura gestionada elimina las barreras tradicionales para la implementación del análisis de imágenes y vídeo.
Para los equipos que evalúan soluciones de visión artificial, Rekognition ofrece un punto de entrada de bajo riesgo: pague solo por lo que usa, comience con modelos predefinidos y escale según sus necesidades. Consulte la documentación oficial de AWS para conocer la disponibilidad actual de funciones y obtener una guía de implementación detallada adaptada a su caso de uso específico.