
El reconocimiento de imágenes por IA suena complejo, pero en esencia, se trata de enseñar a las máquinas a ver patrones como los humanos, solo que más rápido y a una escala mucho mayor. Cada foto, imagen satelital o fotograma de vídeo son solo datos hasta que un sistema de IA aprende a interpretarlos. Ese proceso de aprendizaje es lo que convierte los píxeles sin procesar en señales significativas: objetos, formas, texto o cambios a lo largo del tiempo.
Este artículo explica cómo funciona realmente el reconocimiento de imágenes con IA. No en teoría abstracta, sino en términos prácticos: cómo las imágenes se convierten en números, cómo los modelos aprenden de los ejemplos y por qué la calidad de los datos es más importante que los algoritmos sofisticados. Si alguna vez te has preguntado qué sucede realmente entre subir una imagen y obtener un resultado automatizado, aquí es donde empieza.
Qué significa realmente el reconocimiento de imágenes en IA
El reconocimiento de imágenes es la capacidad de una máquina para identificar patrones, objetos, texto o características dentro de una imagen y asignarles un significado. Este significado puede ser simple, como identificar un coche, o complejo, como detectar señales tempranas de estrés en los cultivos en imágenes aéreas.
A diferencia del software tradicional, los sistemas de IA no siguen reglas predefinidas como "si tiene cuatro ruedas, es un coche". En cambio, aprenden de ejemplos. Se utilizan miles o millones de imágenes etiquetadas para enseñar al sistema cómo se ve algo en diferentes condiciones, ángulos, iluminación y entornos.
En esencia, el reconocimiento de imágenes es una forma de reconocimiento de patrones impulsada por el aprendizaje automático y, más específicamente, el aprendizaje profundo. El sistema no comprende conceptos. Aprende relaciones estadísticas entre las características visuales y los resultados.
Cómo convertimos el reconocimiento de imágenes con IA en resultados reales en FlyPix
En FlyPix, Utilizamos el reconocimiento de imágenes con IA como herramienta práctica para trabajar con imágenes satelitales, aéreas y de drones a gran escala. Nuestro objetivo es ayudar a los equipos a pasar de imágenes sin procesar a información clara sin semanas de trabajo manual ni configuraciones complejas.
Nos basamos en agentes de IA capaces de detectar, monitorizar e inspeccionar objetos en conjuntos de datos grandes y densos. Los usuarios entrenan modelos de IA personalizados con sus propias imágenes y anotaciones, sin necesidad de conocimientos de programación. Usted decide qué es importante en sus datos y el sistema aprende a reconocerlo de forma consistente.
La velocidad es una parte importante del valor. Lo que antes requería horas de anotación manual ahora se puede hacer en segundos. Desde la clasificación del uso del suelo y la inspección de infraestructura hasta la agricultura y el monitoreo ambiental, la prioridad es siempre tomar decisiones más rápidas y confiables.
FlyPix está diseñado para adaptarse a diferentes industrias y casos de uso, sin imponerlos a un único flujo de trabajo. Al mantener el reconocimiento de imágenes por IA flexible y accesible, facilitamos que los equipos lo apliquen en sus operaciones diarias, no solo en proyectos experimentales.
Todo comienza con píxeles
Cada imagen digital es una cuadrícula de píxeles. Cada píxel contiene valores numéricos que describen el color y el brillo. En la mayoría de las imágenes, esto significa tres valores por píxel para rojo, verde y azul.
Para un humano, la foto de una calle es inmediatamente reconocible. Para un modelo de IA, esa misma imagen es una gran matriz de números. No existe una comprensión integrada de carreteras, edificios ni personas. El reto del reconocimiento de imágenes reside en enseñar a un sistema a interpretar estos números de forma coherente.
Antes de que se produzca cualquier aprendizaje, la imagen se convierte a un formato numérico que el modelo pueda procesar. La resolución, la profundidad de color y la estructura del archivo influyen en la cantidad de información disponible y en el volumen de procesamiento.
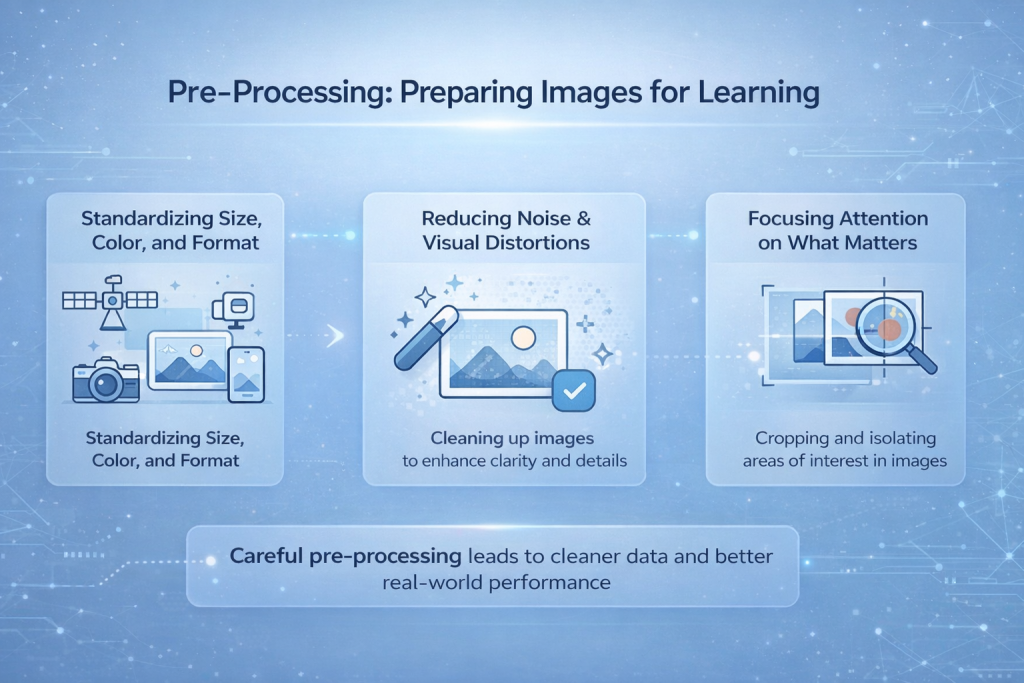
Preprocesamiento: preparación de imágenes para el aprendizaje
Las imágenes obtenidas con cámaras, drones, satélites o teléfonos casi nunca son consistentes. Vienen en diferentes resoluciones, condiciones de iluminación, ángulos y formatos de archivo. Algunas son nítidas, otras con ruido o borrosas. Introducir esta mezcla sin procesar directamente en un modelo hace que el aprendizaje sea inestable e impredecible. El preprocesamiento es el paso donde se controla este caos visual.
Estandarización de tamaño, color y formato
Una de las primeras tareas es uniformizar las imágenes. Los modelos esperan una forma de entrada consistente, por lo que las imágenes se redimensionan a una resolución fija. Los valores de color se normalizan para que las diferencias de brillo y contraste no obstaculicen el proceso de aprendizaje. Esto ayuda al modelo a centrarse en la estructura en lugar de distraerse con los cambios de exposición o la configuración de la cámara.
Reducción del ruido y las distorsiones visuales
El ruido de los sensores, el desenfoque de movimiento, los artefactos de compresión o las condiciones climáticas pueden ocultar detalles importantes. Las técnicas de preprocesamiento ayudan a reducir estos efectos, facilitando la detección de bordes y formas por parte del modelo. Este paso no mejora la imagen en sentido humano, pero sí la legibilidad de los datos para la red.
Centrar la atención en lo que importa
En muchos casos, solo una parte de la imagen es relevante. Recortar, enmascarar o aislar regiones de interés ayuda a eliminar distracciones. Al limitar lo que ve el modelo, el aprendizaje se vuelve más rápido y preciso, especialmente en tareas como la detección de objetos o la obtención de imágenes médicas.
Por qué el preprocesamiento afecta directamente el rendimiento en el mundo real
El preprocesamiento no hace que un modelo sea más inteligente por sí solo. Lo que hace es crear condiciones más limpias para el aprendizaje. Cuando este paso se realiza de forma apresurada o está mal diseñado, los modelos pueden funcionar bien en pruebas controladas, pero fallar en situaciones reales. Un preprocesamiento cuidadoso suele ser la diferencia entre un sistema que funciona en teoría y uno que funciona en la práctica.
Aprendizaje de características: cómo la IA encuentra patrones
Los humanos aprenden a reconocer objetos observando sus características. Los bordes, las formas, las texturas y las proporciones influyen. Los modelos de IA aprenden de forma similar, pero más matemática.
La mayoría de los sistemas modernos de reconocimiento de imágenes se basan en redes neuronales convolucionales (CNN). Estas redes están diseñadas para escanear imágenes mediante pequeños filtros que se desplazan por la imagen y detectan patrones locales.
Las primeras capas de una CNN suelen detectar características muy simples, como bordes, esquinas y gradientes de color. Las capas intermedias las combinan para formar formas y texturas. Las capas más profundas ensamblan estas formas en patrones de mayor nivel que corresponden a objetos o regiones de interés.
La idea clave es la jerarquía. El modelo no pasa directamente de los píxeles a "esto es un árbol". Construye esa comprensión capa por capa.
Por qué es importante la convolución
La convolución permite aplicar el mismo detector de patrones a toda la imagen. Un borde vertical sigue siendo un borde vertical, independientemente de si aparece en el lado izquierdo o derecho de la imagen.
Este enfoque hace que los modelos sean más eficientes y robustos. En lugar de memorizar la disposición exacta de los píxeles, el sistema aprende patrones visuales reutilizables. Esta es una de las razones por las que las CNN funcionan tan bien con diferentes tamaños y diseños de imagen.
Se suelen añadir capas de agrupación para reducir el tamaño de los datos y conservar la información importante. Esto ayuda a controlar los costes de cálculo y evita que el modelo se vuelva demasiado sensible a variaciones minúsculas.
Entrenando el modelo: aprendiendo de los ejemplos
El entrenamiento es donde realmente se produce el reconocimiento de imágenes. Se muestra al modelo un amplio conjunto de imágenes etiquetadas. Cada imagen se asocia con la respuesta correcta, como "cultivo sano", "carretera dañada" o "persona presente".“
Durante el entrenamiento, el proceso sigue un bucle repetitivo:
- El modelo analiza una imagen de entrada y genera una predicción
- La predicción se compara con la etiqueta correcta.
- La diferencia entre ambos se mide como un error.
- El modelo ajusta sus parámetros internos para reducir ese error
- El mismo proceso se repite en miles o millones de ejemplos.
Este ajuste gradual es lo que permite que el sistema mejore con el tiempo.
La retropropagación es el mecanismo que posibilita este aprendizaje. Rastrea los errores hacia atrás a través de la red y actualiza los pesos de cada capa para que las predicciones futuras sean más precisas.
La calidad del entrenamiento depende en gran medida de los datos utilizados. Si el conjunto de datos es demasiado pequeño, está mal etiquetado o presenta sesgo hacia ciertas condiciones, el modelo heredará esas debilidades. Ningún ajuste puede compensar por completo la baja calidad o el desequilibrio de los datos de entrenamiento.
El papel de los datos etiquetados
Los datos etiquetados son la base del reconocimiento supervisado de imágenes. Cada etiqueta indica al modelo qué debe aprender de una imagen.
Crear estas etiquetas suele ser la parte más costosa y lenta del proceso. Los anotadores humanos deben marcar cuidadosamente los objetos, dibujar cuadros delimitadores, segmentar regiones o clasificar imágenes.
Una anotación de alta calidad genera mejores modelos. Una anotación deficiente genera confusión y resultados poco fiables. Por ello, muchos fallos en el reconocimiento de imágenes se deben al conjunto de datos y no al algoritmo.
Aprendizaje por transferencia e inferencia: de un modelo preentrenado a predicciones reales
Entrenar una red neuronal profunda desde cero requiere una gran cantidad de datos etiquetados y una gran capacidad de procesamiento, por lo que muchos equipos no empiezan desde cero. En su lugar, utilizan el aprendizaje por transferencia.
Cómo funciona el aprendizaje por transferencia
El aprendizaje por transferencia comienza con un modelo que ya ha aprendido características visuales generales de un gran conjunto de datos. Este modelo, previamente entrenado, ya comprende patrones comunes como bordes, texturas y formas. A partir de ahí, se perfecciona para una tarea específica utilizando un conjunto de datos más pequeño y centrado en tareas.
En la práctica, las capas iniciales suelen permanecer prácticamente iguales, mientras que las capas posteriores se reentrenan para adaptarse a la nueva tarea. Por ejemplo, un modelo entrenado con imágenes generales puede adaptarse para reconocer defectos en componentes industriales o patrones en escáneres médicos. Este enfoque acelera el desarrollo y, a menudo, mejora la precisión, especialmente cuando el conjunto de datos es limitado.
Del entrenamiento a la inferencia
Una vez entrenado o ajustado el modelo, pasa al modo de inferencia. En esta etapa, procesa imágenes nuevas e inéditas y genera predicciones.
La canalización de inferencia refleja la canalización de entrenamiento:
- Las imágenes están preprocesadas
- Se pasan a través de la red.
- La salida se devuelve como etiquetas, probabilidades, objetos detectados o regiones segmentadas.
En este punto, la prioridad cambia. El objetivo ya no es el aprendizaje, sino un rendimiento constante. En sistemas reales, la inferencia suele tener que ejecutarse en tiempo real o casi real, por lo que la velocidad y la fiabilidad son tan importantes como la precisión bruta.
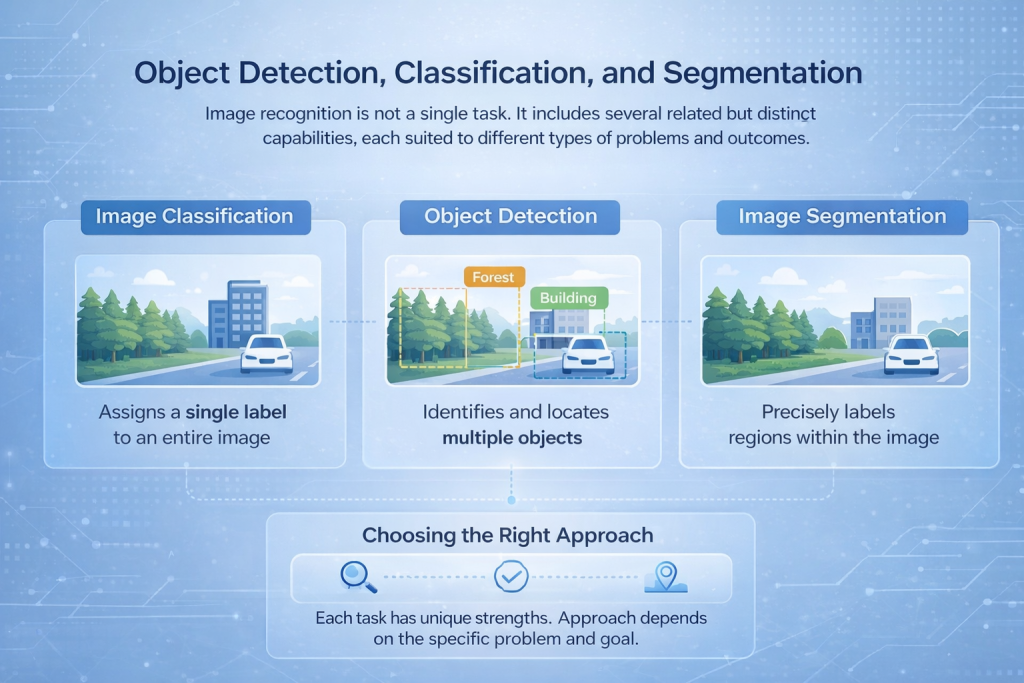
Detección, clasificación y segmentación de objetos
El reconocimiento de imágenes no es una tarea única. Incluye varias capacidades relacionadas, pero distintas, cada una adaptada a distintos tipos de problemas y resultados.
Clasificación de imágenes
La clasificación de imágenes asigna una etiqueta a toda la imagen. El modelo analiza la escena completa y decide qué la describe mejor, como identificar si una imagen contiene un bosque, un edificio o un vehículo. Este enfoque es eficaz cuando el contenido general es más importante que la ubicación exacta.
Object Detection
La detección de objetos va un paso más allá al identificar y localizar múltiples objetos dentro de la misma imagen. En lugar de una sola etiqueta, el modelo dibuja cuadros delimitadores alrededor de los elementos de interés y clasifica cada uno. Esto se utiliza comúnmente en aplicaciones como la monitorización del tráfico, los sistemas de seguridad y la inspección industrial.
Segmentación de imágenes
La segmentación proporciona el nivel de análisis más detallado. Etiqueta píxeles o regiones individuales dentro de una imagen, lo que permite al sistema separar objetos con alta precisión. Esto es esencial en casos de uso como imágenes médicas, mapeo del uso del suelo o análisis de superficies, donde la precisión de los límites es crucial.
Elegir el enfoque adecuado
Cada una de estas tareas requiere diferentes arquitecturas de red y estrategias de entrenamiento. La elección correcta depende del problema a resolver, ya sea contar vehículos, leer texto o mapear el uso del suelo con gran detalle.
Medición del rendimiento
Los modelos de reconocimiento de imágenes se evalúan utilizando métricas como precisión, exactitud, recuperación e intersección sobre unión.
La precisión por sí sola suele ser engañosa. Un modelo que rara vez detecta un objeto puede parecer preciso simplemente porque el objeto es raro. La precisión y la recuperación proporcionan una imagen más clara de la fiabilidad del modelo.
Las pruebas siempre deben realizarse con datos que el modelo nunca ha visto. Esto ayuda a determinar si el sistema ha aprendido patrones generales o simplemente memorizado el conjunto de entrenamiento.
Complejidad, sesgo y límites prácticos del mundo real
El reconocimiento de imágenes con IA funciona mejor en entornos controlados, pero rara vez se controlan los entornos reales. Una vez que los modelos salen del laboratorio y se enfrentan a condiciones reales, las limitaciones se hacen mucho más visibles.
Por qué las condiciones del mundo real son difíciles de modelar
La iluminación cambia a lo largo del día. Los objetos se superponen o desaparecen parcialmente de la vista. El clima interfiere con la visibilidad. Las cámaras se mueven, fallan o capturan datos imperfectos. Todo esto introduce ruido que los modelos deben aprender a gestionar.
Un sistema que funciona bien en las pruebas puede tener dificultades cuando estas variables se acumulan. Por eso, las pruebas, la monitorización y el reentrenamiento continuos son partes esenciales de cualquier sistema de producción, no mejoras opcionales.
El papel de la supervisión humana
El reconocimiento de imágenes por IA es potente, pero no infalible. En aplicaciones críticas para la seguridad o de alto impacto, la revisión humana sigue siendo necesaria. Los humanos aportan contexto, criterio y responsabilidad en situaciones donde las decisiones automatizadas por sí solas no son suficientes.
Cómo el sesgo entra en los sistemas de reconocimiento de imágenes
Los modelos aprenden directamente de los datos con los que se entrenan, incluyendo sus deficiencias y desequilibrios. Si ciertos entornos, poblaciones o condiciones están subrepresentados, el rendimiento se verá afectado.
El sesgo se vuelve especialmente problemático en áreas como la vigilancia, el control de acceso o la seguridad pública, donde los errores pueden tener consecuencias reales. Estos problemas rara vez son causados únicamente por algoritmos.
Por qué el sesgo no es un problema puramente técnico
No existe una única solución técnica para el sesgo. Mejorar la imparcialidad y la fiabilidad requiere:
- Conjuntos de datos más diversos y representativos
- Evaluación cuidadosa en diferentes escenarios
- Revisión continua de cómo se utilizan y actualizan los modelos
El sesgo es, en última instancia, un desafío de datos y procesos. Abordarlo requiere decisiones deliberadas, no solo mejores modelos.

Consideraciones éticas y de privacidad
El reconocimiento de imágenes suele implicar datos confidenciales. Se pueden inferir rostros, ubicaciones y comportamientos a partir de las imágenes, a veces sin que el sujeto sea plenamente consciente de ello.
El uso responsable no se limita a la precisión técnica. Requiere normas claras y límites conscientes, entre ellos:
- Políticas transparentes de recopilación y uso de datos
- Consentimiento explícito cuando se trate de datos personales
- Almacenamiento seguro y acceso controlado a datos de imágenes
- Cumplimiento de las regulaciones de privacidad locales e internacionales
- Rendición de cuentas clara sobre cómo se utilizan las decisiones tomadas por el sistema
Las consideraciones éticas no son una cuestión de último momento. Determinan la confianza pública, la aceptación legal y la viabilidad de los sistemas de reconocimiento de imágenes a largo plazo.
Por qué es importante el reconocimiento de imágenes
A pesar de sus desafíos, el reconocimiento de imágenes por IA se ha convertido en una herramienta crucial en diversas industrias. Permite la automatización donde la inspección humana sería lenta, costosa o inconsistente.
Desde el diagnóstico sanitario hasta la agricultura, el monitoreo de infraestructura hasta el comercio minorista, la capacidad de extraer información de los datos visuales cambia la forma en que se toman las decisiones.
El verdadero valor no reside en reemplazar el juicio humano, sino en potenciarlo. La IA gestiona la escala y la velocidad. Los humanos gestionan el contexto y la responsabilidad.
Conclusión: De los píxeles a las decisiones
El reconocimiento de imágenes con IA funciona porque descompone una compleja capacidad humana en pasos manejables. Los píxeles se convierten en números. Los números en patrones. Los patrones en predicciones. No existe un momento mágico en el que una máquina comprenda de repente una imagen. Solo hay aprendizaje, iteración y perfeccionamiento.
Comprender cómo funciona este proceso ayuda a establecer expectativas realistas. También ayuda a los equipos a desarrollar mejores sistemas, formular mejores preguntas y utilizar la tecnología de forma más responsable. En definitiva, el reconocimiento de imágenes no se trata de que las máquinas vean como los humanos. Se trata de que las máquinas vean de forma diferente y aprovechen esa diferencia para tomar decisiones más rápidas y coherentes cuando es necesario.
Preguntas frecuentes
El reconocimiento de imágenes por IA consiste en enseñar a una computadora a identificar patrones en imágenes. En lugar de comprender las imágenes como lo hacen los humanos, el sistema aprende de ejemplos y utiliza números y probabilidades para decidir qué está observando.
No. La IA no comprende las imágenes conceptualmente. Procesa los valores de los píxeles y aprende patrones basándose en relaciones estadísticas. Los resultados pueden parecer similares a la percepción humana, pero el proceso es completamente diferente.
La mayoría de los sistemas modernos de reconocimiento de imágenes utilizan aprendizaje profundo, en particular redes neuronales convolucionales. Estos modelos están diseñados para aprender características visuales como bordes, formas y texturas a través de múltiples capas.
Eso depende de la tarea. Los problemas de clasificación sencillos pueden funcionar con miles de imágenes, mientras que las tareas complejas de detección o segmentación suelen requerir decenas o cientos de miles de ejemplos etiquetados. La calidad de los datos es tan importante como la cantidad.
La anotación indica al modelo qué debe aprender de cada imagen. Un etiquetado deficiente conlleva predicciones deficientes. La anotación de alta calidad suele ser la parte más laboriosa del desarrollo de un sistema de reconocimiento de imágenes, pero afecta directamente la precisión y la fiabilidad.