
कृत्रिम बुद्धिमत्ता से छवि पहचानना जटिल लगता है, लेकिन मूल रूप से यह मशीनों को मनुष्यों की तरह पैटर्न पहचानने का प्रशिक्षण देने के बारे में है – बस यह काम मशीनों द्वारा तेज़ी से और कहीं अधिक बड़े पैमाने पर किया जा सकता है। प्रत्येक फ़ोटो, उपग्रह छवि या वीडियो फ़्रेम तब तक केवल डेटा होता है जब तक कि कोई कृत्रिम बुद्धिमत्ता प्रणाली उसे समझना नहीं सीख लेती। यही सीखने की प्रक्रिया कच्चे पिक्सेल को सार्थक संकेतों में बदल देती है: वस्तुएं, आकृतियाँ, पाठ या समय के साथ होने वाले परिवर्तन।.
यह लेख बताता है कि एआई इमेज रिकग्निशन असल में पर्दे के पीछे कैसे काम करता है। अमूर्त सिद्धांतों में नहीं, बल्कि व्यावहारिक रूप से, कैसे छवियां संख्याओं में बदलती हैं, कैसे मॉडल उदाहरणों से सीखते हैं, और आकर्षक एल्गोरिदम की तुलना में डेटा की गुणवत्ता क्यों अधिक मायने रखती है। यदि आपने कभी सोचा है कि किसी छवि को अपलोड करने और स्वचालित परिणाम प्राप्त करने के बीच वास्तव में क्या होता है, तो यहीं से इसकी शुरुआत होती है।.
कृत्रिम बुद्धिमत्ता में छवि पहचान का वास्तव में क्या अर्थ है?
छवि पहचान किसी मशीन की वह क्षमता है जिसके द्वारा वह किसी छवि के भीतर मौजूद पैटर्न, वस्तुओं, पाठ या विशेषताओं को पहचानकर उन्हें अर्थ प्रदान करती है। यह अर्थ सरल हो सकता है, जैसे किसी कार की पहचान करना, या जटिल हो सकता है, जैसे हवाई तस्वीरों में फसल पर तनाव के शुरुआती संकेतों का पता लगाना।.
परंपरागत सॉफ़्टवेयर के विपरीत, एआई सिस्टम "अगर इसमें चार पहिए हैं, तो यह कार है" जैसे कठोर नियमों का पालन नहीं करते हैं। इसके बजाय, वे उदाहरणों से सीखते हैं। सिस्टम को यह सिखाने के लिए कि कोई चीज़ अलग-अलग स्थितियों, कोणों, प्रकाश और वातावरण में कैसी दिखती है, हजारों या लाखों लेबल वाली छवियों का उपयोग किया जाता है।.
मूल रूप से, छवि पहचान मशीन लर्निंग और विशेष रूप से डीप लर्निंग द्वारा संचालित पैटर्न पहचान का एक रूप है। यह प्रणाली अवधारणाओं को नहीं समझती है। यह दृश्य विशेषताओं और परिणामों के बीच सांख्यिकीय संबंधों को सीखती है।.
FlyPix में हम AI इमेज रिकग्निशन को वास्तविक दुनिया के परिणामों में कैसे बदलते हैं
पर फ्लाईपिक्स, हम बड़े पैमाने पर उपग्रह, हवाई और ड्रोन छवियों के साथ काम करने के लिए एक व्यावहारिक उपकरण के रूप में एआई छवि पहचान का उपयोग करते हैं। हमारा लक्ष्य टीमों को हफ्तों के मैन्युअल काम या जटिल सेटअप के बिना कच्ची छवियों से स्पष्ट जानकारी प्राप्त करने में मदद करना है।.
हम ऐसे एआई एजेंटों पर निर्भर हैं जो विशाल और सघन डेटासेट में वस्तुओं का पता लगा सकते हैं, उनकी निगरानी कर सकते हैं और उनका निरीक्षण कर सकते हैं। उपयोगकर्ता प्रोग्रामिंग कौशल की आवश्यकता के बिना, अपनी स्वयं की छवियों और टिप्पणियों का उपयोग करके कस्टम एआई मॉडल को प्रशिक्षित करते हैं। आप तय करते हैं कि आपके डेटा में क्या महत्वपूर्ण है, और सिस्टम उसे लगातार पहचानना सीखता है।.
गति इसकी अहमियत का एक बड़ा हिस्सा है। जो काम पहले घंटों के मैन्युअल विश्लेषण से होता था, अब वह सेकंडों में हो जाता है। भूमि उपयोग वर्गीकरण और बुनियादी ढांचे के निरीक्षण से लेकर कृषि और पर्यावरण निगरानी तक, हमारा ध्यान हमेशा तेज़ और अधिक विश्वसनीय निर्णय लेने पर रहता है।.
FlyPix को विभिन्न उद्योगों और उपयोग के मामलों के अनुकूल बनाया गया है, न कि उन्हें किसी एक कार्यप्रणाली में बांधने के लिए। AI इमेज रिकग्निशन को लचीला और सुलभ बनाए रखकर, हम टीमों के लिए इसे प्रायोगिक परियोजनाओं तक ही सीमित न रखकर, दैनिक कार्यों में लागू करना आसान बनाते हैं।.
सब कुछ पिक्सल से शुरू होता है
प्रत्येक डिजिटल छवि पिक्सेल का एक ग्रिड होती है। प्रत्येक पिक्सेल में संख्यात्मक मान होते हैं जो रंग और चमक का वर्णन करते हैं। अधिकांश छवियों में, इसका अर्थ है कि प्रत्येक पिक्सेल में लाल, हरे और नीले रंग के लिए तीन मान होते हैं।.
मनुष्य के लिए, सड़क की तस्वीर तुरंत पहचानी जा सकती है। लेकिन एआई मॉडल के लिए, वही छवि संख्याओं का एक विशाल मैट्रिक्स है। इसमें सड़कों, इमारतों या लोगों की कोई अंतर्निहित समझ नहीं होती। छवि पहचान की चुनौती यह है कि सिस्टम को इन संख्याओं को सार्थक तरीके से व्याख्या करना सिखाया जाए।.
किसी भी प्रकार की लर्निंग प्रक्रिया शुरू होने से पहले, इमेज को एक ऐसे न्यूमेरिकल फॉर्मेट में परिवर्तित किया जाता है जिसे मॉडल प्रोसेस कर सके। रिज़ॉल्यूशन, कलर डेप्थ और फ़ाइल स्ट्रक्चर, ये सभी कारक उपलब्ध जानकारी की मात्रा और गणना की तीव्रता को प्रभावित करते हैं।.
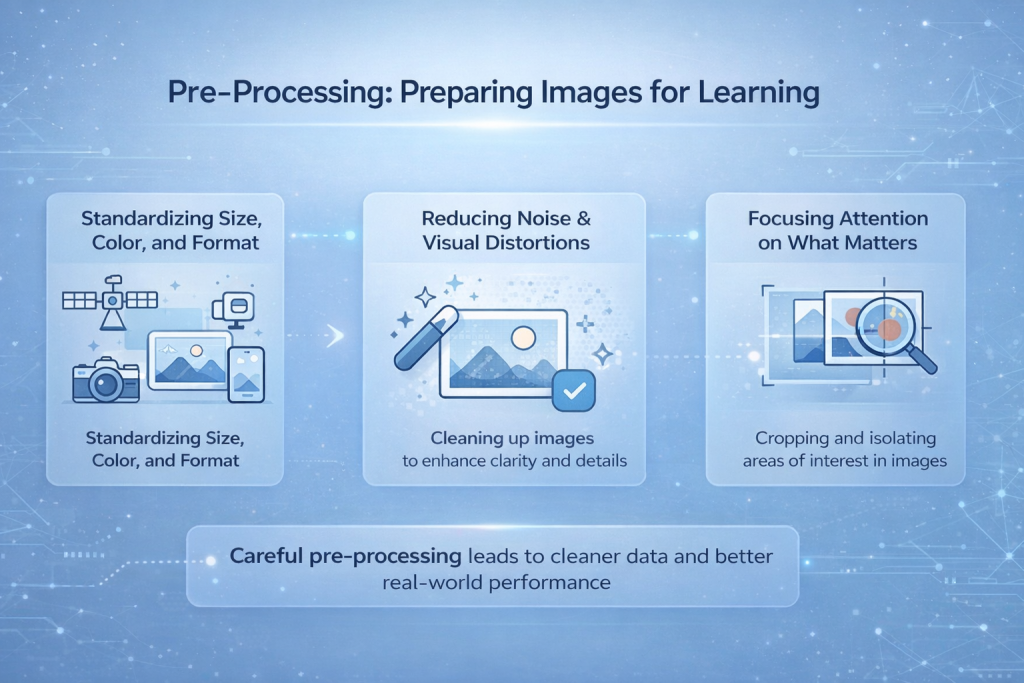
पूर्व-प्रसंस्करण: सीखने के लिए छवियों को तैयार करना
कैमरों, ड्रोनों, उपग्रहों या फोनों से ली गई तस्वीरें लगभग कभी भी एक जैसी नहीं होतीं। वे अलग-अलग रिज़ॉल्यूशन, प्रकाश स्थितियों, कोणों और फ़ाइल स्वरूपों में होती हैं। कुछ स्पष्ट होती हैं, तो कुछ धुंधली या अस्पष्ट। इस कच्चे मिश्रण को सीधे मॉडल में डालने से सीखना अस्थिर और अप्रत्याशित हो जाता है। प्री-प्रोसेसिंग वह चरण है जहाँ इस दृश्य अव्यवस्था को नियंत्रित किया जाता है।.
आकार, रंग और प्रारूप का मानकीकरण
सबसे पहले किए जाने वाले कार्यों में से एक है छवियों को एकसमान बनाना। मॉडल एक समान इनपुट आकार की अपेक्षा करते हैं, इसलिए छवियों का आकार एक निश्चित रिज़ॉल्यूशन में बदला जाता है। रंग मानों को सामान्यीकृत किया जाता है ताकि चमक और कंट्रास्ट में अंतर सीखने की प्रक्रिया को प्रभावित न करें। इससे मॉडल को एक्सपोज़र में बदलाव या कैमरा सेटिंग्स से विचलित होने के बजाय संरचना पर ध्यान केंद्रित करने में मदद मिलती है।.
शोर और दृश्य विकृतियों को कम करना
सेंसर से उत्पन्न शोर, गति धुंधलापन, संपीड़न संबंधी त्रुटियाँ या मौसम की स्थिति महत्वपूर्ण विवरणों को छिपा सकती हैं। प्री-प्रोसेसिंग तकनीकें इन प्रभावों को कम करने में मदद करती हैं, जिससे मॉडल के लिए किनारों और आकृतियों का पता लगाना आसान हो जाता है। यह चरण मानवीय दृष्टि से छवि को बेहतर नहीं बनाता है, लेकिन यह नेटवर्क के लिए डेटा की पठनीयता को बेहतर बनाता है।.
महत्वपूर्ण बातों पर ध्यान केंद्रित करना
कई मामलों में, छवि का केवल एक हिस्सा ही प्रासंगिक होता है। क्रॉपिंग, मास्किंग या रुचि के क्षेत्रों को अलग करने से ध्यान भटकाने वाली चीज़ों को दूर करने में मदद मिलती है। मॉडल द्वारा देखे जाने वाले हिस्से को सीमित करके, सीखना तेज़ और अधिक सटीक हो जाता है, खासकर ऑब्जेक्ट डिटेक्शन या मेडिकल इमेजिंग जैसे कार्यों में।.
प्री-प्रोसेसिंग वास्तविक दुनिया के प्रदर्शन को सीधे तौर पर क्यों प्रभावित करती है?
प्री-प्रोसेसिंग से मॉडल अपने आप में अधिक स्मार्ट नहीं हो जाता। यह सीखने के लिए बेहतर परिस्थितियाँ बनाता है। जब यह चरण जल्दबाजी में या खराब तरीके से किया जाता है, तो मॉडल नियंत्रित परीक्षणों में तो अच्छा प्रदर्शन कर सकते हैं, लेकिन वास्तविक परिस्थितियों में विफल हो जाते हैं। सावधानीपूर्वक की गई प्री-प्रोसेसिंग ही अक्सर एक ऐसे सिस्टम के बीच का अंतर होती है जो सैद्धांतिक रूप से काम करता है और एक ऐसा सिस्टम जो व्यावहारिक रूप से काम करता है।.
फ़ीचर लर्निंग: एआई पैटर्न कैसे खोजता है
मनुष्य वस्तुओं को उनकी विशेषताओं को देखकर पहचानना सीखते हैं। किनारे, आकार, बनावट और अनुपात सभी इसमें भूमिका निभाते हैं। कृत्रिम बुद्धिमत्ता (एआई) मॉडल भी इसी तरह, लेकिन अधिक गणितीय तरीके से सीखते हैं।.
अधिकांश आधुनिक छवि पहचान प्रणालियाँ कनवोल्यूशनल न्यूरल नेटवर्क (सीएनएन) पर निर्भर करती हैं। ये नेटवर्क छवियों को स्कैन करने के लिए डिज़ाइन किए गए हैं, जिसमें छोटे फ़िल्टर छवि पर घूमते हैं और स्थानीय पैटर्न का पता लगाते हैं।.
सीएनएन की शुरुआती परतें किनारों, कोनों और रंग प्रवणता जैसी बहुत ही सरल विशेषताओं का पता लगाती हैं। मध्य परतें इन्हें मिलाकर आकृतियाँ और बनावट बनाती हैं। निचली परतें इन आकृतियों को उच्च-स्तरीय पैटर्न में संयोजित करती हैं जो वस्तुओं या रुचि के क्षेत्रों से मेल खाते हैं।.
मुख्य विचार पदानुक्रम का है। यह मॉडल सीधे पिक्सेल से "यह एक वृक्ष है" तक नहीं पहुंचता। यह परत दर परत उस समझ का निर्माण करता है।.
कनवोल्यूशन क्यों महत्वपूर्ण है?
कनवोल्यूशन विधि से एक ही पैटर्न डिटेक्टर को पूरी छवि पर लागू किया जा सकता है। एक ऊर्ध्वाधर किनारा, चाहे वह छवि के बाईं ओर हो या दाईं ओर, एक ऊर्ध्वाधर किनारा ही रहता है।.
यह दृष्टिकोण मॉडलों को अधिक कुशल और अधिक मजबूत बनाता है। सटीक पिक्सेल व्यवस्थाओं को याद रखने के बजाय, सिस्टम पुन: उपयोग योग्य दृश्य पैटर्न सीखता है। यही कारण है कि सीएनएन विभिन्न छवि आकारों और लेआउट में इतनी अच्छी तरह से काम करते हैं।.
महत्वपूर्ण जानकारी को बरकरार रखते हुए डेटा का आकार कम करने के लिए अक्सर पूलिंग लेयर्स जोड़ी जाती हैं। इससे गणना लागत को नियंत्रित करने में मदद मिलती है और मॉडल को छोटे-छोटे बदलावों के प्रति अत्यधिक संवेदनशील होने से रोका जा सकता है।.
मॉडल को प्रशिक्षित करना: उदाहरणों से सीखना
प्रशिक्षण वह चरण है जहाँ छवि पहचान वास्तव में होती है। मॉडल को लेबल की गई छवियों का एक बड़ा सेट दिखाया जाता है। प्रत्येक छवि को सही उत्तर के साथ जोड़ा जाता है, जैसे "स्वस्थ फसल", "क्षतिग्रस्त सड़क" या "व्यक्ति उपस्थित"।“
प्रशिक्षण के दौरान, यह प्रक्रिया एक दोहराव वाले चक्र का अनुसरण करती है:
- यह मॉडल इनपुट छवि का विश्लेषण करता है और एक पूर्वानुमान उत्पन्न करता है।
- भविष्यवाणी की तुलना सही लेबल से की जाती है।
- इन दोनों के बीच के अंतर को त्रुटि के रूप में मापा जाता है।
- यह मॉडल उस त्रुटि को कम करने के लिए अपने आंतरिक मापदंडों को समायोजित करता है।
- हजारों या लाखों उदाहरणों में यही प्रक्रिया दोहराई जाती है।
यह क्रमिक समायोजन ही है जो प्रणाली को समय के साथ बेहतर होने में सक्षम बनाता है।.
बैकप्रोपैगेशन वह तंत्र है जो इस सीखने को संभव बनाता है। यह नेटवर्क में त्रुटियों का पता लगाता है और प्रत्येक परत के भार को अपडेट करता है ताकि भविष्यवाणियां अधिक सटीक हो सकें।.
प्रशिक्षण की गुणवत्ता काफी हद तक उपयोग किए गए डेटा पर निर्भर करती है। यदि डेटासेट बहुत छोटा है, ठीक से लेबल नहीं किया गया है, या कुछ विशेष स्थितियों की ओर झुकाव रखता है, तो मॉडल में भी ये कमियां आ जाएंगी। किसी भी प्रकार का ट्यूनिंग निम्न-गुणवत्ता वाले या असंतुलित प्रशिक्षण डेटा की भरपाई पूरी तरह से नहीं कर सकता।.
लेबल किए गए डेटा की भूमिका
लेबल किया गया डेटा पर्यवेक्षित छवि पहचान का आधार है। प्रत्येक लेबल मॉडल को बताता है कि उसे छवि से क्या सीखना चाहिए।.
इन लेबलों को बनाना अक्सर प्रक्रिया का सबसे महंगा और समय लेने वाला हिस्सा होता है। मानव एनोटेटर्स को वस्तुओं को सावधानीपूर्वक चिह्नित करना, सीमा बॉक्स बनाना, क्षेत्रों को विभाजित करना या छवियों को वर्गीकृत करना होता है।.
उच्च गुणवत्ता वाली एनोटेशन से बेहतर मॉडल बनते हैं। खराब एनोटेशन से भ्रम और अविश्वसनीय परिणाम उत्पन्न होते हैं। यही कारण है कि छवि पहचान में होने वाली कई विफलताओं का कारण एल्गोरिदम के बजाय डेटासेट होता है।.
स्थानांतरण अधिगम और अनुमान: पूर्व-प्रशिक्षित मॉडल से वास्तविक भविष्यवाणियों तक
किसी डीप न्यूरल नेटवर्क को बिल्कुल शुरुआत से प्रशिक्षित करने के लिए बहुत सारे लेबल किए गए डेटा और पर्याप्त कंप्यूटिंग शक्ति की आवश्यकता होती है, यही कारण है कि कई टीमें शून्य से शुरुआत नहीं करती हैं। इसके बजाय, वे ट्रांसफर लर्निंग का उपयोग करती हैं।.
ट्रांसफर लर्निंग कैसे काम करती है
ट्रांसफर लर्निंग की शुरुआत एक ऐसे मॉडल से होती है जिसने पहले से ही एक बड़े डेटासेट से सामान्य दृश्य विशेषताओं को सीख लिया होता है। वह पूर्व-प्रशिक्षित मॉडल किनारों, बनावटों और आकृतियों जैसे सामान्य पैटर्न को पहले से ही समझता है। इसके बाद, इसे एक छोटे, कार्य-केंद्रित डेटासेट का उपयोग करके एक विशिष्ट कार्य के लिए परिष्कृत किया जाता है।.
व्यवहार में, शुरुआती परतें आमतौर पर लगभग अपरिवर्तित रहती हैं, जबकि बाद की परतों को नए कार्य के अनुरूप प्रशिक्षित किया जाता है। उदाहरण के लिए, सामान्य छवियों पर प्रशिक्षित मॉडल को औद्योगिक घटकों में दोषों या मेडिकल स्कैन में पैटर्न को पहचानने के लिए अनुकूलित किया जा सकता है। यह दृष्टिकोण विकास को गति देता है और अक्सर सटीकता में सुधार करता है, विशेष रूप से जब आपका डेटासेट सीमित हो।.
प्रशिक्षण से निष्कर्ष तक
मॉडल के प्रशिक्षित या परिष्कृत हो जाने के बाद, यह अनुमान लगाने के चरण में चला जाता है। यह वह चरण है जहां यह नई, अनदेखी छवियों को संसाधित करता है और भविष्यवाणियां उत्पन्न करता है।.
इन्फरेंस पाइपलाइन, ट्रेनिंग पाइपलाइन के समान ही होती है:
- छवियों को पूर्व-संसाधित किया जाता है
- वे नेटवर्क के माध्यम से भेजे जाते हैं
- आउटपुट लेबल, संभावनाओं, पहचाने गए ऑब्जेक्ट या खंडित क्षेत्रों के रूप में लौटाया जाता है।
इस बिंदु पर, प्राथमिकता बदल जाती है। लक्ष्य अब सीखना नहीं, बल्कि निरंतर प्रदर्शन करना है। वास्तविक प्रणालियों में, अनुमान प्रक्रिया को अक्सर वास्तविक समय या लगभग वास्तविक समय में चलाने की आवश्यकता होती है, इसलिए गति और विश्वसनीयता उतनी ही महत्वपूर्ण हैं जितनी कि सटीक जानकारी।.
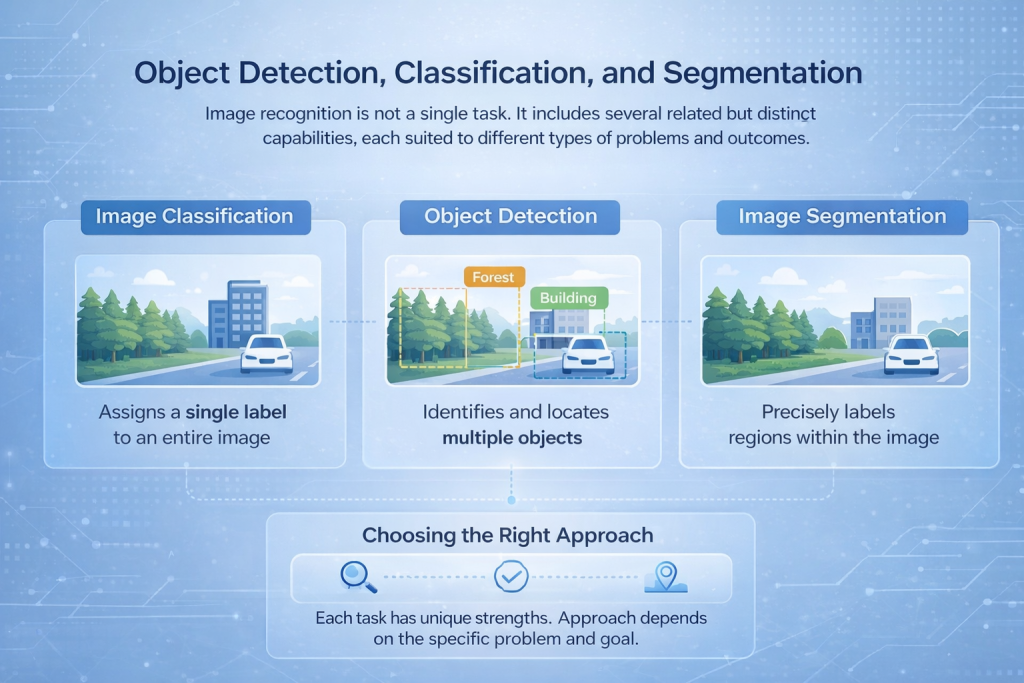
ऑब्जेक्ट डिटेक्शन, क्लासिफिकेशन और सेगमेंटेशन
छवि पहचान एक एकल कार्य नहीं है। इसमें कई संबंधित लेकिन अलग-अलग क्षमताएं शामिल हैं, जिनमें से प्रत्येक विभिन्न प्रकार की समस्याओं और परिणामों के लिए उपयुक्त है।.
छवि वर्गीकरण
इमेज क्लासिफिकेशन पूरी इमेज को एक लेबल प्रदान करता है। मॉडल पूरे दृश्य को देखता है और यह तय करता है कि उसका सबसे अच्छा वर्णन क्या है, जैसे कि यह पहचानना कि इमेज में जंगल है, इमारत है या वाहन है। यह तरीका तब बेहतर काम करता है जब सटीक स्थान की तुलना में समग्र विषयवस्तु अधिक महत्वपूर्ण हो।.
ऑब्जेक्ट डिटेक्शन
ऑब्जेक्ट डिटेक्शन एक कदम आगे बढ़कर एक ही इमेज में कई ऑब्जेक्ट्स की पहचान और लोकेशन निर्धारित करता है। सिंगल लेबल के बजाय, मॉडल रुचि के आइटम्स के चारों ओर बाउंडिंग बॉक्स बनाता है और प्रत्येक को वर्गीकृत करता है। इसका उपयोग आमतौर पर ट्रैफिक मॉनिटरिंग, सुरक्षा प्रणालियों और औद्योगिक निरीक्षण जैसे अनुप्रयोगों में किया जाता है।.
छवि विभाजन
सेगमेंटेशन विश्लेषण का सबसे विस्तृत स्तर प्रदान करता है। यह छवि के भीतर अलग-अलग पिक्सेल या क्षेत्रों को लेबल करता है, जिससे सिस्टम वस्तुओं को उच्च परिशुद्धता के साथ अलग कर सकता है। यह चिकित्सा इमेजिंग, भूमि उपयोग मानचित्रण या सतह विश्लेषण जैसे उपयोग मामलों में आवश्यक है, जहां सटीक सीमाएं मायने रखती हैं।.
सही दृष्टिकोण का चयन करना
इनमें से प्रत्येक कार्य के लिए अलग-अलग नेटवर्क आर्किटेक्चर और प्रशिक्षण रणनीतियों की आवश्यकता होती है। सही विकल्प समस्या के समाधान पर निर्भर करता है, चाहे लक्ष्य वाहनों की गिनती करना हो, पाठ पढ़ना हो या भूमि उपयोग का सूक्ष्म स्तर पर मानचित्रण करना हो।.
प्रदर्शन का मापन
इमेज रिकग्निशन मॉडल का मूल्यांकन एक्यूरेसी, प्रिसिजन, रिकॉल और इंटरसेक्शन ओवर यूनियन जैसे मापदंडों का उपयोग करके किया जाता है।.
केवल सटीकता ही अक्सर भ्रामक होती है। एक मॉडल जो किसी वस्तु का पता बहुत कम लगाता है, वह केवल इसलिए सटीक प्रतीत हो सकता है क्योंकि वह वस्तु दुर्लभ है। परिशुद्धता और रिकॉल मॉडल की विश्वसनीयता की अधिक स्पष्ट तस्वीर प्रदान करते हैं।.
परीक्षण हमेशा ऐसे डेटा पर किया जाना चाहिए जिसे मॉडल ने पहले कभी नहीं देखा हो। इससे यह पता लगाने में मदद मिलती है कि सिस्टम ने सामान्य पैटर्न सीखे हैं या केवल प्रशिक्षण सेट को याद किया है।.
वास्तविक दुनिया की जटिलता, पूर्वाग्रह और व्यावहारिक सीमाएँ
कृत्रिम बुद्धिमत्ता से छवि पहचानना नियंत्रित परिस्थितियों में सबसे अच्छा काम करता है, लेकिन वास्तविक वातावरण शायद ही कभी नियंत्रित होते हैं। एक बार जब मॉडल प्रयोगशाला से बाहर निकलकर वास्तविक दुनिया की परिस्थितियों का सामना करते हैं, तो उनकी सीमाएँ कहीं अधिक स्पष्ट हो जाती हैं।.
वास्तविक दुनिया की स्थितियों का मॉडल बनाना क्यों मुश्किल है?
दिनभर में प्रकाश की स्थिति बदलती रहती है। वस्तुएँ एक-दूसरे पर चढ़ जाती हैं या आंशिक रूप से दृष्टि से ओझल हो जाती हैं। मौसम के कारण दृश्यता प्रभावित होती है। कैमरे हिलते हैं, खराब हो जाते हैं या अपूर्ण डेटा कैप्चर करते हैं। इन सभी कारणों से शोर उत्पन्न होता है जिसे मॉडल को संभालना सीखना पड़ता है।.
परीक्षण में अच्छा प्रदर्शन करने वाला सिस्टम इन कारकों के जमा होने पर विफल हो सकता है। यही कारण है कि निरंतर परीक्षण, निगरानी और पुनः प्रशिक्षण किसी भी उत्पादन प्रणाली के अनिवार्य अंग हैं, न कि वैकल्पिक सुधार।.
मानव पर्यवेक्षण की भूमिका
कृत्रिम बुद्धिमत्ता से छवि पहचानना शक्तिशाली है, लेकिन यह अचूक नहीं है। सुरक्षा की दृष्टि से महत्वपूर्ण या उच्च प्रभाव वाले अनुप्रयोगों में, मानवीय समीक्षा आवश्यक बनी रहती है। मनुष्य उन स्थितियों में संदर्भ, निर्णय और जवाबदेही प्रदान करते हैं जहां स्वचालित निर्णय अकेले पर्याप्त नहीं होते।.
छवि पहचान प्रणालियों में पूर्वाग्रह कैसे प्रवेश करता है
मॉडल सीधे उस डेटा से सीखते हैं जिस पर उन्हें प्रशिक्षित किया जाता है, जिसमें डेटा की कमियां और असंतुलन भी शामिल हैं। यदि कुछ विशेष वातावरण, जनसंख्या या परिस्थितियां अपर्याप्त रूप से प्रस्तुत की जाती हैं, तो ऐसे मामलों में प्रदर्शन प्रभावित होगा।.
निगरानी, पहुंच नियंत्रण या सार्वजनिक सुरक्षा जैसे क्षेत्रों में पूर्वाग्रह विशेष रूप से समस्याग्रस्त हो जाता है, जहां त्रुटियों के गंभीर परिणाम हो सकते हैं। ये समस्याएं शायद ही कभी केवल एल्गोरिदम के कारण होती हैं।.
पूर्वाग्रह विशुद्ध रूप से तकनीकी समस्या क्यों नहीं है?
पक्षपात को दूर करने का कोई एक तकनीकी समाधान नहीं है। निष्पक्षता और विश्वसनीयता में सुधार के लिए निम्नलिखित की आवश्यकता है:
- अधिक विविध और प्रतिनिधि डेटासेट
- विभिन्न परिदृश्यों में सावधानीपूर्वक मूल्यांकन
- मॉडलों के उपयोग और अद्यतन करने के तरीकों की निरंतर समीक्षा की जा रही है।
पूर्वाग्रह अंततः डेटा और प्रक्रिया से जुड़ी एक चुनौती है। इसे दूर करने के लिए बेहतर मॉडल ही काफी नहीं हैं, बल्कि सोच-समझकर निर्णय लेने की आवश्यकता है।.

गोपनीयता और नैतिक विचार
छवि पहचान में अक्सर संवेदनशील डेटा शामिल होता है। चेहरों, स्थानों और व्यवहारों का अनुमान छवियों से लगाया जा सकता है, कभी-कभी विषय को इसकी पूरी जानकारी भी नहीं होती है।.
जिम्मेदार उपयोग केवल तकनीकी सटीकता पर निर्भर नहीं करता। इसके लिए स्पष्ट नियम और सचेत सीमाएं आवश्यक हैं, जिनमें शामिल हैं:
- पारदर्शी डेटा संग्रहण और उपयोग नीतियां
- जहां व्यक्तिगत डेटा शामिल हो, वहां स्पष्ट सहमति आवश्यक है।
- छवि डेटा का सुरक्षित भंडारण और नियंत्रित पहुंच
- स्थानीय और अंतर्राष्ट्रीय गोपनीयता नियमों का अनुपालन
- सिस्टम द्वारा लिए गए निर्णयों के उपयोग के लिए स्पष्ट जवाबदेही।
नैतिक पहलू कोई गौण विषय नहीं हैं। वे जनविश्वास, कानूनी स्वीकृति और इस बात को प्रभावित करते हैं कि क्या छवि पहचान प्रणालियाँ दीर्घकालिक रूप से व्यवहार्य बनी रहेंगी।.
छवि पहचान क्यों महत्वपूर्ण है?
चुनौतियों के बावजूद, एआई इमेज रिकग्निशन विभिन्न उद्योगों में एक महत्वपूर्ण उपकरण बन गया है। यह उन क्षेत्रों में स्वचालन को सक्षम बनाता है जहां मानवीय निरीक्षण धीमा, महंगा या असंगत हो सकता है।.
स्वास्थ्य सेवा निदान से लेकर कृषि तक, बुनियादी ढांचे की निगरानी से लेकर खुदरा क्षेत्र तक, दृश्य डेटा से अंतर्दृष्टि निकालने की क्षमता निर्णय लेने के तरीके को बदल देती है।.
असली मूल्य मानवीय निर्णय को प्रतिस्थापित करने में नहीं, बल्कि उसे बढ़ाने में निहित है। एआई बड़े पैमाने और गति को संभालता है। मनुष्य संदर्भ और जिम्मेदारी को संभालते हैं।.
निष्कर्ष: पिक्सेल से लेकर निर्णयों तक
कृत्रिम बुद्धिमत्ता से छवि पहचान इसलिए काम करती है क्योंकि यह एक जटिल मानवीय क्षमता को सरल चरणों में तोड़ देती है। पिक्सेल संख्या बन जाते हैं। संख्याएँ पैटर्न बन जाती हैं। पैटर्न पूर्वानुमान बन जाते हैं। ऐसा कोई जादुई क्षण नहीं होता जब कोई मशीन अचानक किसी छवि को समझ जाए। इसमें केवल सीखना, अभ्यास करना और सुधार करना शामिल है।.
इस प्रक्रिया को समझना यथार्थवादी अपेक्षाएँ निर्धारित करने में सहायक होता है। इससे टीमों को बेहतर सिस्टम बनाने, बेहतर प्रश्न पूछने और प्रौद्योगिकी का अधिक जिम्मेदारी से उपयोग करने में भी मदद मिलती है। अंततः, छवि पहचान का अर्थ मशीनों का मनुष्यों की तरह देखना नहीं है। इसका अर्थ है मशीनों का अलग तरह से देखना और उस अंतर का उपयोग करके महत्वपूर्ण समय पर तेज़ और अधिक सुसंगत निर्णय लेना।.
अक्सर पूछे जाने वाले प्रश्नों
कृत्रिम बुद्धिमत्ता (AI) छवि पहचान एक ऐसी प्रक्रिया है जिसमें कंप्यूटर को छवियों में पैटर्न पहचानने का प्रशिक्षण दिया जाता है। मनुष्यों की तरह चित्रों को समझने के बजाय, सिस्टम उदाहरणों से सीखता है और संख्याओं और संभावनाओं का उपयोग करके यह तय करता है कि वह क्या देख रहा है।.
नहीं। कृत्रिम बुद्धिमत्ता छवियों को अवधारणात्मक रूप से नहीं समझती। यह पिक्सेल मानों को संसाधित करती है और सांख्यिकीय संबंधों के आधार पर पैटर्न सीखती है। परिणाम देखने में मानवीय धारणा के समान लग सकते हैं, लेकिन प्रक्रिया पूरी तरह से अलग है।.
अधिकांश आधुनिक छवि पहचान प्रणालियाँ डीप लर्निंग, विशेष रूप से कनवोल्यूशनल न्यूरल नेटवर्क का उपयोग करती हैं। ये मॉडल कई परतों के माध्यम से किनारों, आकृतियों और बनावट जैसी दृश्य विशेषताओं को सीखने के लिए डिज़ाइन किए गए हैं।.
यह कार्य पर निर्भर करता है। सरल वर्गीकरण समस्याओं में हजारों छवियों का उपयोग किया जा सकता है, जबकि जटिल पहचान या विभाजन कार्यों के लिए अक्सर दसियों या सैकड़ों हजारों लेबल किए गए उदाहरणों की आवश्यकता होती है। डेटा की गुणवत्ता मात्रा जितनी ही महत्वपूर्ण है।.
एनोटेशन मॉडल को बताता है कि उसे प्रत्येक छवि से क्या सीखना चाहिए। खराब लेबलिंग से गलत अनुमान लगते हैं। उच्च-गुणवत्ता वाला एनोटेशन अक्सर छवि पहचान प्रणाली के निर्माण का सबसे अधिक समय लेने वाला हिस्सा होता है, लेकिन यह सटीकता और विश्वसनीयता को सीधे प्रभावित करता है।.