
इमेज रिकग्निशन पहली नज़र में काफी जटिल लग सकता है। न्यूरल नेटवर्क, डेटासेट, ट्रेनिंग लूप, जीपीयू – कोड की एक लाइन लिखने से पहले ही यह सब कुछ बहुत जटिल लग सकता है। लेकिन व्यवहार में, इमेज रिकग्निशन एआई बनाना एक ही बार में सब कुछ सीखने से कहीं ज़्यादा, चरण दर चरण सही निर्णय लेने के बारे में है।.
मूल रूप से, छवि पहचान का उद्देश्य किसी सिस्टम को छवियों में पैटर्न पहचानने और उनके आधार पर सटीक निर्णय लेने के लिए प्रशिक्षित करना है। इसका अर्थ वस्तुओं की पहचान करना, दृश्यों का वर्गीकरण करना, दोषों का पता लगाना या असामान्यताओं को चिह्नित करना हो सकता है। इसके पीछे की तकनीक शक्तिशाली है, लेकिन प्रक्रिया आश्चर्यजनक रूप से सरल है: कार्य को परिभाषित करें, डेटा तैयार करें, मॉडल को प्रशिक्षित करें, ईमानदारी से उसका परीक्षण करें और उसे वहीं तैनात करें जहां वह वास्तव में उपयोगी हो।.
यह लेख उस प्रक्रिया को व्यावहारिक और सरल तरीके से समझाता है। इसमें कोई बढ़ा-चढ़ाकर बात नहीं की गई है, कोई शॉर्टकट नहीं है, और यह मानकर नहीं चला गया है कि आप कोई शोध पत्र लिख रहे हैं। बस यह स्पष्ट रूप से बताया गया है कि आज इमेज रिकग्निशन एआई कैसे बनाया जाता है, हर चरण में वास्तव में क्या मायने रखता है, और लोग आमतौर पर कहाँ गलती करते हैं।.

एक ऐसी समस्या से शुरुआत करें जिसका आप स्पष्ट रूप से वर्णन कर सकें।
डेटा या मॉडल को छूने से पहले, आपको एक स्पष्ट रूप से परिभाषित कार्य की आवश्यकता है। "छवियों को पहचानना" नहीं, बल्कि कुछ ठोस कार्य।.
- क्या आप पूरी छवि को एक ही श्रेणी में वर्गीकृत कर रहे हैं?
- क्या आप वस्तुओं को ढूंढकर उनके चारों ओर बॉक्स बना रहे हैं?
- क्या आप पिक्सेल स्तर पर सटीक आकृतियों या सीमाओं की पहचान कर रहे हैं?
इनमें से प्रत्येक एक अलग समस्या है, जिसके अलग-अलग लागत और जोखिम हैं।.
कई परियोजनाएँ इसलिए असफल हो जाती हैं क्योंकि वे अस्पष्ट शुरुआत करती हैं और बहुत देर बाद जटिल हो जाती हैं। यदि आप किसी गैर-तकनीकी व्यक्ति को एक वाक्य में अपना लक्ष्य नहीं समझा सकते, तो वह परियोजना अभी तैयार नहीं है।.
अच्छे उदाहरण
- “"फोटो से कार के बॉडी पैनल पर दिखाई देने वाले नुकसान का पता लगाएं।"”
- “हवाई तस्वीरों में ढेर सारी लकड़ियों की गिनती करें।”
- “"पता लगाएं कि फसल क्षेत्र में प्रारंभिक तनाव के लक्षण दिखाई दे रहे हैं या नहीं।"”
बुरे उदाहरण
- “"छवियों का विश्लेषण करने के लिए एआई का उपयोग करें।"”
- “"स्मार्ट कंप्यूटर विज़न विकसित करें।"”
यहां स्पष्टता होने से महीनों बाद का समय बच जाता है।.
समझें कि छवियां संख्याओं में कैसे परिवर्तित होती हैं
कंप्यूटर वस्तुओं को नहीं देखता। यह संख्याओं के सरणियों को देखता है।.
प्रत्येक छवि को पिक्सेल में परिवर्तित किया जाता है, और प्रत्येक पिक्सेल तीव्रता या रंग को दर्शाने वाले मान बन जाते हैं। एक रंगीन छवि किसी मॉडल के लिए केवल एक चित्र नहीं होती। यह कई चैनलों में फैली संख्याओं का एक ग्रिड होता है।.
छवि पहचान उन संख्याओं के भीतर मौजूद पैटर्न को सीखकर काम करती है। किनारे, आकार, बनावट, विरोधाभास। ऐसा इसलिए नहीं कि मॉडल अर्थ समझता है, बल्कि इसलिए कि यह लेबल के साथ सहसंबंधित सांख्यिकीय नियमितताओं को ढूंढता है।.
यह महत्वपूर्ण है क्योंकि इससे डेटा की गुणवत्ता के बारे में आपकी सोच बदल जाती है। यदि मॉडल विफल हो जाता है, तो अक्सर इसका कारण यह होता है कि उसे मिलने वाले आंकड़े असंगत, त्रुटिपूर्ण या भ्रामक होते हैं।.
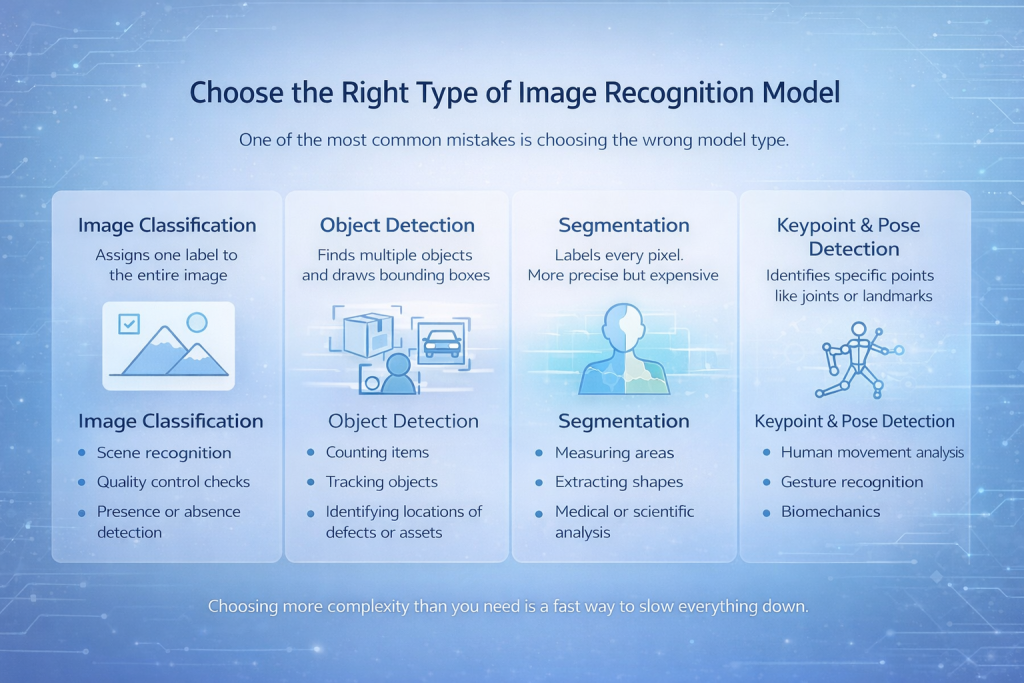
सही प्रकार का इमेज रिकग्निशन मॉडल चुनें
सबसे आम गलतियों में से एक गलत मॉडल प्रकार का चयन करना है।.
कई मुख्य श्रेणियां हैं:
छवि वर्गीकरण
यह मॉडल पूरी छवि को एक ही लेबल प्रदान करता है। यह सरल, तेज़ और प्रभावी है, खासकर तब जब छवि में मुख्य वस्तु हावी हो।.
सर्वश्रेष्ठ के लिए:
- दृश्य पहचान
- गुणवत्ता नियंत्रण जांच
- उपस्थिति या अनुपस्थिति का पता लगाना
ऑब्जेक्ट डिटेक्शन
यह मॉडल कई वस्तुओं का पता लगाता है और उनके चारों ओर सीमा बॉक्स बनाता है।.
सर्वश्रेष्ठ के लिए:
- वस्तुओं की गिनती
- ट्रैकिंग ऑब्जेक्ट
- दोषों या संपत्तियों के स्थानों की पहचान करना
विभाजन
प्रत्येक पिक्सेल को एक लेबल मिलता है। यह अधिक सटीक और अधिक महंगा है।.
सर्वश्रेष्ठ के लिए:
- क्षेत्रों को मापना
- आकृतियों को निकालना
- चिकित्सा या वैज्ञानिक विश्लेषण
कीपॉइंट और पोज़ डिटेक्शन
यह मॉडल जोड़ों या विशिष्ट स्थलों जैसे विशेष बिंदुओं की पहचान करता है।.
सर्वश्रेष्ठ के लिए:
- मानव गति विश्लेषण
- संकेत पहचान
- जैवयांत्रिकी
आवश्यकता से अधिक जटिलता का चयन करना हर चीज को धीमा करने का एक त्वरित तरीका है।.
डेटा सिर्फ महत्वपूर्ण नहीं है, बल्कि यह परियोजना का मूल आधार है।
मॉडल ध्यान आकर्षित करते हैं। असली काम तो डेटा ही करता है।.
एक सशक्त छवि पहचान प्रणाली आर्किटेक्चर की तुलना में डेटासेट पर कहीं अधिक निर्भर करती है। यदि डेटा कमजोर या असंगत है तो सबसे उन्नत मॉडल भी विफल हो जाएगा।.
वे प्रमुख सिद्धांत जो वास्तव में मायने रखते हैं:
डेटा की विविधता, डेटा की मात्रा से बेहतर है।
दस हजार एक जैसी तस्वीरें अक्सर दो हजार अलग-अलग तरह की तस्वीरों से खराब होती हैं। अलग-अलग कोण, प्रकाश की स्थिति, पृष्ठभूमि, रिज़ॉल्यूशन और डिवाइस के प्रकार, तस्वीरों की संख्या से कहीं अधिक मायने रखते हैं।.
लेबल वास्तविकता से मेल खाने चाहिए
यदि मनुष्य लेबल को लेकर बहस करते हैं, तो मॉडल में भ्रम की स्थिति पैदा हो जाएगी। अस्पष्ट श्रेणियों को या तो विलय कर देना चाहिए या उन्हें शुरुआत में ही पुनर्परिभाषित कर देना चाहिए।.
संतुलन मायने रखता है
यदि कोई एक वर्ग हावी हो जाता है, तो सटीकता भ्रामक हो जाती है। कोई मॉडल बहुसंख्यक वर्ग का हमेशा सही अनुमान लगाकर भी "सटीक" हो सकता है।.
एनोटेशन ही वह जगह है जहां गुणवत्ता हासिल होती है या खो जाती है।
लेबलिंग अक्सर जल्दबाजी में की जाती है, जिसका असर बाद में दिखाई देता है। गलत लेबलिंग से ऐसी समस्याएं पैदा होती हैं जिन्हें ट्रेनिंग के दौरान पहचानना मुश्किल होता है, लेकिन वास्तविक उपयोग में वे बेहद स्पष्ट हो जाती हैं। मॉडल अस्थिर हो जाते हैं, अनुमान बेतरतीब लगते हैं, और कई तरह की समस्याएं उत्पन्न हो जाती हैं। हर गलत लेबल वाली छवि सीखने की प्रक्रिया को धीरे-धीरे खराब कर देती है।.
अच्छे एनोटेशन की शुरुआत स्पष्ट लेबलिंग नियमों से होती है जिनका पालन सभी लोग एक समान तरीके से करें। जब अलग-अलग लोग लेबलों की अलग-अलग व्याख्या करते हैं, तो मॉडल पैटर्न के बजाय भ्रम सीखता है। सटीकता के साथ-साथ निरंतरता भी उतनी ही महत्वपूर्ण है, इसीलिए नियमित जांच और छोटे ऑडिट आवश्यक हैं। ये डेटासेट में फैलने से पहले ही शुरुआती चरण में ही विचलन को पकड़ने में मदद करते हैं।.
एनोटेशन में विकास की गुंजाइश भी होनी चाहिए। जैसे-जैसे नए अपवाद सामने आते हैं, लेबल को उन परिभाषाओं में ढालने के बजाय परिष्कृत किया जाना चाहिए जो अब उपयुक्त नहीं हैं। इस तरह की क्रमिक सफाई धीमी होती है, लेकिन इससे मॉडल की स्थिरता में लाभ मिलता है।.
कृत्रिम बुद्धिमत्ता (AI) की सहायता से लेबलिंग करने वाले उपकरण, विशेष रूप से बड़े डेटासेट पर, प्रक्रिया को गति दे सकते हैं, लेकिन वे मानवीय निर्णय का स्थान नहीं ले सकते। वे केवल वही तर्क दोहराते हैं जो उन्हें दिया जाता है। यदि नियम अस्पष्ट या त्रुटिपूर्ण हैं, तो स्वचालन गलती को ठीक करने के बजाय उसे और बढ़ा देगा।.
प्रीप्रोसेसिंग केवल दिखावटी नहीं है।
प्रीप्रोसेसिंग का मतलब सिर्फ तस्वीरों को साफ-सुथरा दिखाना नहीं है। इसका मतलब है अवांछित भिन्नता को कम करना और महत्वपूर्ण चीजों को उजागर करना।.
कुछ सामान्य तरीके जो वास्तव में मददगार होते हैं:
- छवियों का आकार एकसमान रिज़ॉल्यूशन में बदलें
- पिक्सेल मानों को सामान्य करना
- दिशा सुधारना
- अप्रासंगिक क्षेत्रों को क्रॉप करना
डेटा संवर्धन पर विशेष ध्यान देने की आवश्यकता है। रोटेशन, फ्लिपिंग, ब्राइटनेस शिफ्ट या नॉइज़ इंजेक्शन जैसे सरल रूपांतरण जनरलाइज़ेशन को काफी हद तक बेहतर बना सकते हैं। लक्ष्य मॉडल को धोखा देना नहीं, बल्कि उसे वास्तविकता के लिए तैयार करना है।.
यदि आपका डेटा बहुत ही सटीक दिखता है, तो वास्तविक दुनिया में आपका मॉडल घबरा जाएगा।.
मॉडल आर्किटेक्चर उतना मायने नहीं रखता जितना आप सोचते हैं।
सबसे नए या सबसे चर्चित मॉडल को अपनाने का प्रबल प्रलोभन होता है। ट्रांसफॉर्मर, विशाल बैकबोन और जटिल पाइपलाइनें देखने में तो प्रभावशाली लग सकती हैं, लेकिन वे बेहतर परिणामों की गारंटी नहीं देतीं।.
व्यवहार में, कई विश्वसनीय छवि पहचान प्रणालियाँ सुस्थापित आर्किटेक्चर पर आधारित होती हैं। कनवोल्यूशनल न्यूरल नेटवर्क अभी भी इस क्षेत्र में अग्रणी हैं, और इसका एक कारण है। वे स्थिर, कुशल हैं और गड़बड़ी होने पर उन्हें समझना आसान होता है। यह विश्वसनीयता अक्सर बेंचमार्क परीक्षणों में कुछ अतिरिक्त प्रतिशत अंक प्राप्त करने से कहीं अधिक महत्वपूर्ण होती है।.
ट्रांसफर लर्निंग आमतौर पर सबसे अच्छा शुरुआती बिंदु होता है। बड़े और विविध डेटासेट से पहले से सीखे हुए मॉडल का उपयोग करने से आपको एक मजबूत आधार मिलता है, खासकर जब आपका अपना डेटा सीमित हो। फाइन-ट्यूनिंग तब सबसे अच्छा काम करती है जब नया कार्य मॉडल द्वारा पहले देखे गए कार्यों के काफी करीब हो, जब ओवरफिटिंग को सक्रिय रूप से नियंत्रित किया जाए, और जब री-ट्रेनिंग आक्रामक तरीके से करने के बजाय सावधानीपूर्वक की जाए। छोटे, सोचे-समझे समायोजन अक्सर जबरदस्ती री-ट्रेनिंग से बेहतर परिणाम देते हैं।.
बड़े मॉडल हमेशा बेहतर मॉडल नहीं होते। उन्हें प्रशिक्षित करने में अधिक लागत आती है, उनमें मौजूद त्रुटियों को ठीक करना कठिन होता है, और वे अक्सर सूक्ष्म तरीकों से विफल हो जाते हैं जिनका पता लगाना मुश्किल होता है।.
प्रशिक्षण आपके डेटा के साथ एक निरंतर चलने वाली बातचीत है।
प्रशिक्षण एक क्लिक का ऑपरेशन नहीं है। यह एक चक्र है।.
आप प्रशिक्षण लेते हैं, परिणामों का अवलोकन करते हैं, विफलता के पैटर्न की पहचान करते हैं, डेटा या मापदंडों को समायोजित करते हैं और प्रक्रिया दोहराते हैं।.
प्रमुख प्रशिक्षण पद्धतियाँ:
- प्रशिक्षण, सत्यापन और परीक्षण के लिए अलग-अलग सेटों का उपयोग करें।
- सटीकता के साथ-साथ हानि वक्रों पर भी ध्यान दें।
- जब सुधार रुक जाए तो प्रशिक्षण बंद कर दें।
- लर्निंग रेट और बैच साइज को ध्यानपूर्वक समायोजित करें।
गंभीर कार्यों के लिए GPU एक्सेलरेशन अनिवार्य है। CPU पर प्रशिक्षण सीखने के लिए तो ठीक है, लेकिन वास्तविक परियोजनाओं के लिए अव्यावहारिक है। GPU पुनरावृति समय को कम करते हैं, जिससे प्रयोगों को सक्षम बनाकर मॉडल की गुणवत्ता में सीधे सुधार होता है।.
मूल्यांकन सटीकता से परे होना चाहिए
सटीकता की गणना करना सबसे आसान मापदंडों में से एक है, लेकिन इसे समझना भी उतना ही आसान है। एक मॉडल देखने में अत्यधिक सटीक लग सकता है, लेकिन वास्तविक परिस्थितियों में वह बेकार साबित हो सकता है।.
बेहतर मूल्यांकन में गहराई से पड़ताल की जाती है। कन्फ्यूजन मैट्रिक्स से यह पता चलता है कि मॉडल लगातार कहाँ गलतियाँ कर रहा है। प्रेसिजन और रिकॉल तब कहीं अधिक उपयोगी होते हैं जब क्लास असंतुलित हों या कुछ गलतियाँ दूसरों की तुलना में अधिक नुकसानदायक हों। पूरी तरह से नई, वास्तविक दुनिया की छवियों पर परीक्षण करने से अक्सर ऐसी समस्याएँ सामने आती हैं जो स्वच्छ सत्यापन डेटा में कभी दिखाई नहीं देतीं।.
मूल्यांकन का सबसे महत्वपूर्ण चरण अभी भी मैन्युअल समीक्षा है। असफल भविष्यवाणियों को सीधे देखना और यह पूछना कि वे क्यों हुईं, ऐसी अंतर्दृष्टि प्रदान करता है जिसे कोई भी मीट्रिक पूरी तरह से नहीं दर्शा सकता। यदि आप सारांशित संख्याओं पर भरोसा करने के बजाय उनकी गलतियों की जांच करने के लिए समय निकालते हैं, तो मॉडल अपनी कमजोरियों के बारे में आश्चर्यजनक रूप से ईमानदार होते हैं।.
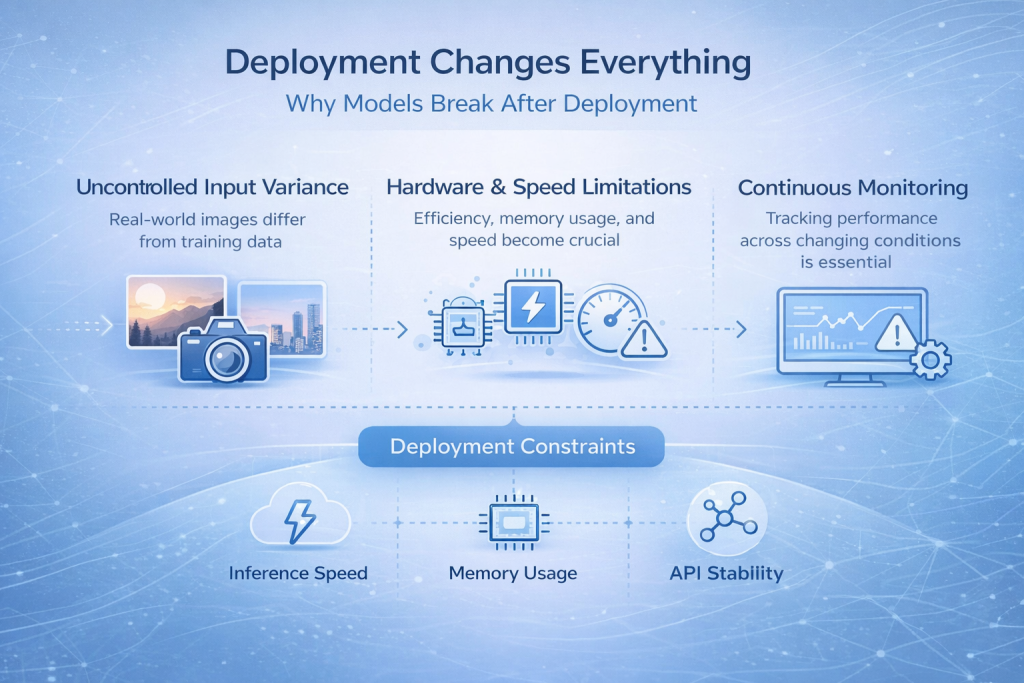
तैनाती से सब कुछ बदल जाता है
तैनाती के बाद मॉडल क्यों टूट जाते हैं?
कई इमेज रिकग्निशन मॉडल विकास के दौरान तो अच्छा प्रदर्शन करते हैं, लेकिन तैनाती के बाद धीरे-धीरे विफल हो जाते हैं। यह पूरी प्रक्रिया में सबसे आम और निराशाजनक क्षणों में से एक है।.
कारण सीधा-सादा है। वास्तविक दुनिया के इनपुट शायद ही कभी प्रशिक्षण डेटा जैसे दिखते हैं। छवियां अलग-अलग कैमरों से आती हैं, दिन भर प्रकाश की स्थिति बदलती रहती है, संपीड़न संबंधी त्रुटियां दिखाई देती हैं, और उपयोगकर्ता आदर्श उपयोग पैटर्न का पालन नहीं करते हैं। छवियों को कैप्चर करने के तरीके में छोटे-छोटे बदलाव भी मॉडल को उस दायरे से बाहर धकेल सकते हैं जिसमें उसने काम करना सीखा है।.
नियंत्रित वातावरण में जो चीज स्थिर प्रतीत होती थी, वह अचानक अविश्वसनीय हो जाती है।.
वे बाधाएँ जिन्हें आप अनदेखा नहीं कर सकते
परिनियोजन आपको मॉडल की सटीकता से परे सोचने के लिए मजबूर करता है। वास्तविक समय में पूर्वानुमान की आवश्यकता होने पर अनुमान की गति महत्वपूर्ण हो जाती है। एज डिवाइस या मोबाइल हार्डवेयर पर मॉडल चलने पर मेमोरी का उपयोग मायने रखता है। हार्डवेयर की सीमाएँ यह निर्धारित करती हैं कि किस प्रकार के आर्किटेक्चर संभव हैं, और जब अन्य सिस्टम आपके पूर्वानुमानों पर निर्भर करते हैं तो API की स्थिरता आवश्यक हो जाती है।.
मॉनिटरिंग भी अब एक ऐसी चीज़ नहीं रह गई है जिसे रखना अच्छा माना जाता हो, बल्कि यह एक आवश्यकता बन गई है। रिलीज़ के बाद मॉडल कैसा व्यवहार करता है, इसकी जानकारी के बिना, विफलताएँ तब तक अनदेखी रह सकती हैं जब तक कि विश्वास न टूट जाए।.
मॉडल को प्रयोगयोग्य बनाना
किसी मॉडल को TensorFlow Lite या ONNX जैसे फॉर्मेट में एक्सपोर्ट करना सिर्फ एक तकनीकी प्रक्रिया नहीं है। यह प्रशिक्षित मॉडल को उत्पादन में उपयोग करने योग्य बनाने की प्रक्रिया का एक महत्वपूर्ण हिस्सा है। ये फॉर्मेट मॉडल को विभिन्न वातावरणों के अनुकूल बनाने, अनावश्यक लागत को कम करने और परिनियोजन लक्ष्यों के साथ अनुकूलता में सुधार करने में मदद करते हैं।.
एक ऐसा मॉडल जो लैपटॉप पर तो अच्छा प्रदर्शन करता है लेकिन व्यावहारिक उपयोग में विफल हो जाता है, वह अधूरा है। वास्तविक सफलता तभी मिलती है जब सिस्टम उस स्थान पर लगातार काम करता है जहां उसे उपयोग के लिए बनाया गया है।.
वास्तविक दुनिया में छवि पहचान: FlyPix AI में हम इसे कैसे विकसित करते हैं
पर फ्लाईपिक्स एआई, हम इमेज रिकग्निशन को प्रयोगशाला अभ्यास के रूप में नहीं देखते। हम प्रतिदिन सैटेलाइट, हवाई और ड्रोन छवियों के साथ काम करते हैं, जहाँ दृश्य सघन होते हैं, वस्तुएँ एक-दूसरे पर चढ़ी होती हैं और परिस्थितियाँ कभी भी परिपूर्ण नहीं होतीं। यही वास्तविकता हमारे एआई के निर्माण और उपयोग को आकार देती है।.
हमारा लक्ष्य हमेशा से सीधा रहा है: मैन्युअल दृश्य विश्लेषण की बाधा को दूर करना। टीमें छवियों पर टिप्पणी करने, परिणामों की जाँच करने और परिस्थितियों में बदलाव होने पर उन्हें दोबारा जाँचने में सैकड़ों घंटे खर्च करती थीं। हमने FlyPix को AI एजेंटों का उपयोग करके इस काम को स्वचालित करने के लिए बनाया है, जो सटीकता से समझौता किए बिना बड़े पैमाने पर वस्तुओं का पता लगा सकते हैं, उनकी निगरानी कर सकते हैं और उनका निरीक्षण कर सकते हैं।.
हमारे लिए सबसे महत्वपूर्ण है व्यावहारिकता। आपको अपने उपयोग के लिए उपयुक्त मॉडल को प्रशिक्षित करने के लिए गहन एआई ज्ञान या मशीन लर्निंग इंजीनियरों की टीम की आवश्यकता नहीं होनी चाहिए। FlyPix के साथ, टीमें अपने स्वयं के एनोटेशन का उपयोग करके कस्टम इमेज रिकग्निशन मॉडल बना सकती हैं, जो उनके उद्योग में वास्तव में महत्वपूर्ण वस्तुओं पर केंद्रित होते हैं। निर्माण स्थल, बंदरगाह, कृषि भूमि, अवसंरचना संपत्तियां, वन क्षेत्र - इमेजरी अलग-अलग हो सकती है, लेकिन चुनौती एक ही है।.
हम हर चीज़ को तैनाती को ध्यान में रखकर डिज़ाइन करते हैं। वास्तविक दुनिया का भू-स्थानिक डेटा लगातार बदलता रहता है, इसलिए मॉडल को पहले दिन से ही बदलावों को संभालना आना चाहिए। इसका मतलब है ऐसे सिस्टम बनाना जो साफ-सुथरे डेमो के बाहर भी भरोसेमंद तरीके से काम करें, बड़ी मात्रा में छवियों को तेज़ी से प्रोसेस करें और ऐसे परिणाम दें जिन पर टीमें तुरंत कार्रवाई कर सकें। हमारे लिए, छवि पहचान तभी सफल होती है जब वह दैनिक कार्यों में भी कारगर साबित हो, न कि केवल परीक्षण के दौरान।.
फीडबैक लूप मॉडल को जीवंत बनाए रखते हैं
इमेज रिकग्निशन एआई स्थिर नहीं होता। डेटा बदलता है। वातावरण बदलता है। अपेक्षाएं बदलती हैं।.
टिकाऊ प्रणालियाँ ऐसी बनाई जाती हैं जिनमें ग्राहकों की प्रतिक्रिया को ध्यान में रखा जाता है:
- तैनाती के बाद नई छवियां एकत्र करें
- विफलता के मामलों पर नज़र रखें
- समय-समय पर पुनः प्रशिक्षण दें
- वास्तविकता में बदलाव आने पर लेबल को समायोजित करें।
तैनाती के बाद मिलने वाले अनुभवों को नजरअंदाज करना, सिस्टम पर भरोसा खोने का सबसे तेज तरीका है।.
निष्कर्ष
एक कारगर इमेज रिकग्निशन एआई बनाना नवीनतम मॉडलों के पीछे भागने से कहीं अधिक बुनियादी बातों को सही ढंग से समझने पर निर्भर करता है। समस्या की स्पष्ट परिभाषा, व्यवस्थित डेटा विश्लेषण, सोच-समझकर मूल्यांकन और व्यावहारिक तैनाती योजना किसी भी एक एल्गोरिदम के चुनाव से कहीं अधिक महत्वपूर्ण हैं।.
सबसे विश्वसनीय प्रणालियाँ सबसे जटिल नहीं होतीं। वे ऐसी प्रणालियाँ होती हैं जो वास्तविक दुनिया में छवियों के परिवर्तन और उन परिवर्तनों पर मॉडलों की प्रतिक्रिया को ईमानदारी से समझकर बनाई जाती हैं। उन्हें वास्तविकता को प्रतिबिंबित करने वाले डेटा पर प्रशिक्षित किया जाता है, कमजोरियों को उजागर करने वाले मापदंडों के साथ उनका मूल्यांकन किया जाता है, और पहले दिन से ही सीमाओं को ध्यान में रखते हुए उन्हें तैनात किया जाता है।.
अगर इससे कोई एक बात स्पष्ट हो सकती है, तो वह यह है: इमेज रिकग्निशन एक इंजीनियरिंग प्रक्रिया है, न कि एक बार का प्रयोग। जब आप इसे इसी तरह से लेते हैं, सावधानीपूर्वक सुधार करते हैं, और वास्तविक उपयोग पर ध्यान केंद्रित करते हैं, तो डेमो समाप्त होने के काफी समय बाद भी परिणाम बेहतर बने रहते हैं।.
सामान्य प्रश्न
इमेज रिकग्निशन एआई एक प्रकार का कंप्यूटर विज़न सिस्टम है जो छवियों में पैटर्न, वस्तुओं या विशेषताओं को पहचानना सीखता है। यह पिक्सेल डेटा का विश्लेषण करके और प्रशिक्षित मॉडलों का उपयोग करके दृश्य पैटर्न को लेबल या परिणामों से जोड़कर काम करता है।.
हमेशा नहीं। बड़े डेटासेट मददगार होते हैं, लेकिन उनकी मात्रा से ज़्यादा विविधता और गुणवत्ता मायने रखती है। ट्रांसफर लर्निंग और उचित ऑग्मेंटेशन की मदद से, अपेक्षाकृत छोटे लेकिन सुव्यवस्थित डेटासेट पर भी उपयोगी मॉडल प्रशिक्षित किए जा सकते हैं।.
अधिकांश परियोजनाओं के लिए, सिद्ध कनवोल्यूशनल न्यूरल नेटवर्क से शुरुआत करना और ट्रांसफर लर्निंग लागू करना एक सुरक्षित और प्रभावी तरीका है। अधिक जटिल मॉडलों का उपयोग तभी किया जाना चाहिए जब इसके लिए स्पष्ट कारण और पर्याप्त डेटा उपलब्ध हो।.
केवल सटीकता ही पर्याप्त नहीं है। आपको कन्फ्यूजन मैट्रिक्स, प्रिसिजन और रिकॉल को देखना चाहिए और मॉडल को वास्तविक दुनिया की उन छवियों पर टेस्ट करना चाहिए जो ट्रेनिंग का हिस्सा नहीं थीं। विफलताओं की मैन्युअल समीक्षा अक्सर सबसे उपयोगी साबित होती है।.
ऐसा आमतौर पर इसलिए होता है क्योंकि प्रोडक्शन इमेज ट्रेनिंग डेटा से अलग होती हैं। लाइटिंग, कैमरा क्वालिटी, इमेज कंप्रेशन या यूजर बिहेवियर में बदलाव से परफॉर्मेंस प्रभावित हो सकती है। यह अंतर आम बात है और डेवलपमेंट के दौरान इसका ध्यान रखना जरूरी है।.
जी हाँ। परिनियोजन कोई अंतिम चरण नहीं है जिसे अंत तक अनदेखा किया जा सके। हार्डवेयर की सीमाएँ, अनुमान की गति, मेमोरी का उपयोग और एकीकरण की आवश्यकताएँ, ये सभी कारक इस बात को प्रभावित करते हैं कि मॉडल का निर्माण और प्रशिक्षण कैसे किया जाना चाहिए।.