

O reconhecimento de imagens por IA parece complexo, mas, em essência, trata-se de ensinar máquinas a enxergar padrões da mesma forma que os humanos – só que mais rápido e em uma escala muito maior. Cada foto, imagem de satélite ou quadro de vídeo é apenas dado até que um sistema de IA aprenda a interpretá-lo. Esse processo de aprendizado é o que transforma pixels brutos em sinais significativos: objetos, formas, texto ou mudanças ao longo do tempo.
Este artigo explica como o reconhecimento de imagens por IA funciona nos bastidores. Não em termos teóricos abstratos, mas em termos práticos, como as imagens se transformam em números, como os modelos aprendem com exemplos e por que a qualidade dos dados importa mais do que algoritmos sofisticados. Se você já se perguntou o que realmente acontece entre o envio de uma imagem e a obtenção de um resultado automatizado, é aqui que tudo começa.
O que o reconhecimento de imagem realmente significa em IA
O reconhecimento de imagem é a capacidade de uma máquina identificar padrões, objetos, texto ou características dentro de uma imagem e atribuir-lhes significado. Esse significado pode ser simples, como identificar um carro, ou complexo, como detectar sinais precoces de estresse em plantações a partir de imagens aéreas.
Ao contrário do software tradicional, os sistemas de IA não seguem regras rígidas, como "se tem quatro rodas, é um carro". Em vez disso, aprendem com exemplos. Milhares ou milhões de imagens rotuladas são usadas para ensinar o sistema a reconhecer a aparência de algo em diferentes condições, ângulos, iluminação e ambientes.
Em sua essência, o reconhecimento de imagens é uma forma de reconhecimento de padrões impulsionada por aprendizado de máquina e, mais especificamente, por aprendizado profundo. O sistema não compreende conceitos. Ele aprende relações estatísticas entre características visuais e resultados.
Como transformamos o reconhecimento de imagem por IA em resultados reais na FlyPix
No FlyPix, Utilizamos reconhecimento de imagem por IA como uma ferramenta prática para trabalhar em grande escala com imagens de satélite, aéreas e de drones. Nosso objetivo é ajudar as equipes a transformar imagens brutas em insights claros sem semanas de trabalho manual ou configurações complexas.
Nossa estratégia se baseia em agentes de IA capazes de detectar, monitorar e inspecionar objetos em conjuntos de dados grandes e complexos. Os usuários treinam modelos de IA personalizados usando suas próprias imagens e anotações, sem a necessidade de conhecimentos de programação. Você define o que é importante em seus dados, e o sistema aprende a reconhecê-lo de forma consistente.
A velocidade é um fator crucial de valor. O que antes exigia horas de anotações manuais agora pode ser feito em segundos. Da classificação do uso da terra e inspeção de infraestrutura ao monitoramento agrícola e ambiental, o foco está sempre em decisões mais rápidas e confiáveis.
O FlyPix foi desenvolvido para se adaptar a diferentes setores e casos de uso, e não para forçá-los a um único fluxo de trabalho. Ao manter o reconhecimento de imagem por IA flexível e acessível, facilitamos a aplicação pelas equipes em operações diárias, e não apenas em projetos experimentais.
Tudo começa com pixels
Toda imagem digital é uma grade de pixels. Cada pixel contém valores numéricos que descrevem a cor e o brilho. Na maioria das imagens, isso significa três valores por pixel para vermelho, verde e azul.
Para um ser humano, a foto de uma rua é imediatamente reconhecível. Para um modelo de IA, essa mesma imagem é uma grande matriz de números. Não há um entendimento inato de ruas, prédios ou pessoas. O desafio do reconhecimento de imagens é ensinar um sistema a interpretar esses números de forma significativa.
Antes de qualquer aprendizado ocorrer, a imagem é convertida em um formato numérico que o modelo possa processar. Resolução, profundidade de cor e estrutura do arquivo afetam a quantidade de informações disponíveis e o volume de processamento necessário.
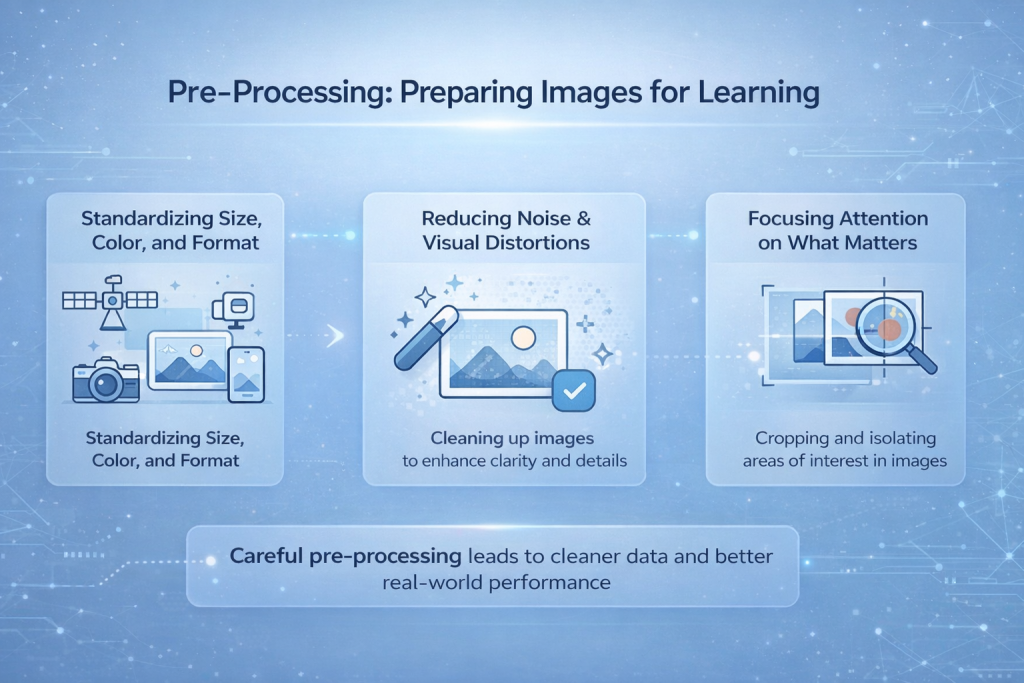
Pré-processamento: Preparando imagens para aprendizagem
As imagens coletadas por câmeras, drones, satélites ou celulares quase nunca são consistentes. Elas vêm em diferentes resoluções, condições de iluminação, ângulos e formatos de arquivo. Algumas são nítidas, outras ruidosas ou borradas. Alimentar um modelo com essa mistura bruta torna o aprendizado instável e imprevisível. O pré-processamento é a etapa em que esse caos visual é controlado.
Padronização de tamanho, cor e formato.
Uma das primeiras tarefas é uniformizar as imagens. Os modelos esperam um formato de entrada consistente, então as imagens são redimensionadas para uma resolução fixa. Os valores de cor são normalizados para que as diferenças de brilho e contraste não sobrecarreguem o processo de aprendizado. Isso ajuda o modelo a se concentrar na estrutura, em vez de se distrair com mudanças de exposição ou configurações da câmera.
Reduzindo ruídos e distorções visuais
Ruídos de sensores, desfoque de movimento, artefatos de compressão ou condições climáticas podem ocultar detalhes importantes. Técnicas de pré-processamento ajudam a reduzir esses efeitos, facilitando a detecção de bordas e formas pelo modelo. Essa etapa não melhora a imagem em um sentido humano, mas melhora a legibilidade dos dados para a rede neural.
Concentrar a atenção no que importa
Em muitos casos, apenas parte de uma imagem é relevante. Recortar, mascarar ou isolar regiões de interesse ajuda a eliminar distrações. Ao limitar o que o modelo vê, o aprendizado se torna mais rápido e preciso, especialmente em tarefas como detecção de objetos ou imagens médicas.
Por que o pré-processamento afeta diretamente o desempenho no mundo real?
O pré-processamento, por si só, não torna um modelo mais inteligente. O que ele faz é criar condições mais adequadas para o aprendizado. Quando essa etapa é feita às pressas ou mal planejada, os modelos podem ter um bom desempenho em testes controlados, mas falhar em situações reais. Um pré-processamento cuidadoso costuma ser o diferencial entre um sistema que funciona na teoria e um que funciona na prática.
Aprendizado de Características: Como a IA Encontra Padrões
Os humanos aprendem a reconhecer objetos observando suas características. Bordas, formas, texturas e proporções desempenham um papel importante. Os modelos de IA aprendem de maneira semelhante, porém mais matemática.
A maioria dos sistemas modernos de reconhecimento de imagens utiliza redes neurais convolucionais, ou CNNs. Essas redes são projetadas para analisar imagens usando pequenos filtros que se movem pela imagem e detectam padrões locais.
As primeiras camadas de uma CNN tendem a detectar características muito simples, como bordas, cantos e gradientes de cor. As camadas intermediárias combinam esses elementos em formas e texturas. As camadas mais profundas agrupam essas formas em padrões de nível superior que correspondem a objetos ou regiões de interesse.
A ideia central é a hierarquia. O modelo não parte diretamente dos pixels para "isto é uma árvore". Ele constrói esse entendimento camada por camada.
Por que a convolução é importante
A convolução permite que o mesmo detector de padrões seja aplicado a toda a imagem. Uma borda vertical continua sendo uma borda vertical, independentemente de estar no lado esquerdo ou direito da imagem.
Essa abordagem torna os modelos mais eficientes e robustos. Em vez de memorizar arranjos exatos de pixels, o sistema aprende padrões visuais reutilizáveis. Essa é uma das razões pelas quais as CNNs funcionam tão bem em diferentes tamanhos e formatos de imagem.
As camadas de pooling são frequentemente adicionadas para reduzir o tamanho dos dados, mantendo informações importantes. Isso ajuda a controlar os custos computacionais e impede que o modelo se torne muito sensível a pequenas variações.
Treinando o Modelo: Aprendendo com Exemplos
O treinamento é onde o reconhecimento de imagem realmente acontece. O modelo recebe um grande conjunto de imagens rotuladas. Cada imagem é associada à resposta correta, como "plantação saudável", "estrada danificada" ou "pessoa presente".“
Durante o treinamento, o processo segue um ciclo repetitivo:
- O modelo analisa uma imagem de entrada e gera uma previsão.
- A previsão é comparada ao rótulo correto.
- A diferença entre os dois é medida como um erro.
- O modelo ajusta seus parâmetros internos para reduzir esse erro.
- O mesmo processo se repete em milhares ou milhões de exemplos.
Esse ajuste gradual é o que permite que o sistema melhore com o tempo.
A retropropagação é o mecanismo que torna esse aprendizado possível. Ela rastreia os erros de trás para frente na rede e atualiza os pesos de cada camada para que as previsões futuras se tornem mais precisas.
A qualidade do treinamento depende muito dos dados utilizados. Se o conjunto de dados for muito pequeno, mal rotulado ou tendencioso em relação a certas condições, o modelo herdará essas deficiências. Nenhum ajuste fino poderá compensar totalmente dados de treinamento de baixa qualidade ou desbalanceados.
O papel dos dados rotulados
Os dados rotulados são a base do reconhecimento supervisionado de imagens. Cada rótulo indica ao modelo o que ele deve aprender com uma imagem.
A criação dessas etiquetas costuma ser a parte mais cara e demorada do processo. Os anotadores humanos precisam marcar cuidadosamente os objetos, desenhar caixas delimitadoras, segmentar regiões ou classificar imagens.
Anotações de alta qualidade levam a modelos melhores. Anotações ruins levam à confusão e a resultados não confiáveis. É por isso que muitas falhas no reconhecimento de imagens podem ser atribuídas ao conjunto de dados, e não ao algoritmo.
Aprendizado por Transferência e Inferência: De um Modelo Pré-treinado a Previsões Reais
Treinar uma rede neural profunda do zero exige muitos dados rotulados e um poder computacional considerável, razão pela qual muitas equipes não começam do zero. Em vez disso, elas utilizam a aprendizagem por transferência.
Como funciona a aprendizagem por transferência
A aprendizagem por transferência começa com um modelo que já aprendeu características visuais gerais a partir de um grande conjunto de dados. Esse modelo pré-treinado já entende padrões comuns, como bordas, texturas e formas. A partir daí, ele é ajustado para uma tarefa específica usando um conjunto de dados menor e focado nessa tarefa.
Na prática, as camadas iniciais geralmente permanecem praticamente as mesmas, enquanto as camadas posteriores são retreinadas para se adequarem à nova tarefa. Por exemplo, um modelo treinado com imagens genéricas pode ser adaptado para reconhecer defeitos em componentes industriais ou padrões em exames médicos. Essa abordagem acelera o desenvolvimento e frequentemente melhora a precisão, especialmente quando o conjunto de dados é limitado.
Do treinamento à inferência
Uma vez que o modelo é treinado ou ajustado, ele entra no modo de inferência. Esta é a fase em que processa imagens novas e nunca vistas antes e produz previsões.
O pipeline de inferência espelha o pipeline de treinamento:
- As imagens são pré-processadas.
- Eles são transmitidos pela rede.
- O resultado é retornado como rótulos, probabilidades, objetos detectados ou regiões segmentadas.
Neste ponto, a prioridade muda. O objetivo não é mais o aprendizado, mas sim o desempenho consistente. Em sistemas reais, a inferência muitas vezes precisa ser executada em tempo real ou quase em tempo real, portanto, velocidade e confiabilidade importam tanto quanto a precisão bruta.
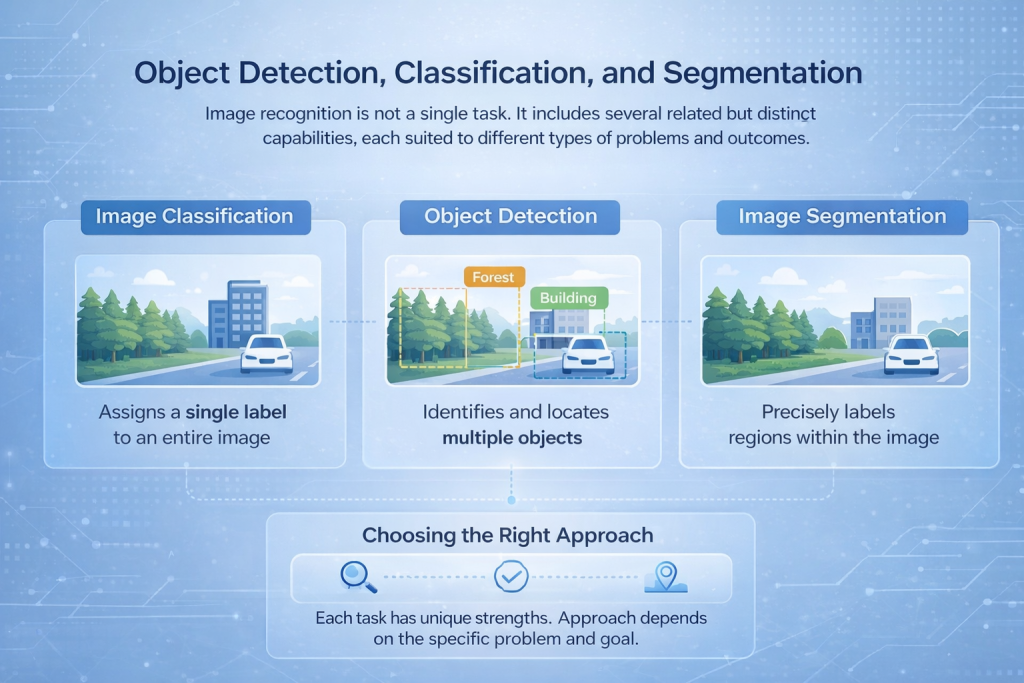
Detecção, classificação e segmentação de objetos
O reconhecimento de imagens não é uma tarefa única. Inclui diversas capacidades relacionadas, mas distintas, cada uma adequada a diferentes tipos de problemas e resultados.
Classificação de imagens
A classificação de imagens atribui um rótulo a uma imagem inteira. O modelo analisa a cena completa e decide o que melhor a descreve, como identificar se uma imagem contém uma floresta, um edifício ou um veículo. Essa abordagem funciona bem quando o conteúdo geral é mais importante do que a localização precisa.
Object Detection
A detecção de objetos vai um passo além, identificando e localizando múltiplos objetos na mesma imagem. Em vez de um único rótulo, o modelo desenha caixas delimitadoras ao redor dos itens de interesse e classifica cada um deles. Isso é comumente usado em aplicações como monitoramento de tráfego, sistemas de segurança e inspeção industrial.
Segmentação de imagens
A segmentação proporciona o nível de análise mais detalhado. Ela rotula pixels ou regiões individuais dentro de uma imagem, permitindo que o sistema separe objetos com alta precisão. Isso é essencial em casos de uso como imagens médicas, mapeamento de uso do solo ou análise de superfície, onde limites exatos são importantes.
Escolhendo a abordagem correta
Cada uma dessas tarefas exige arquiteturas de rede e estratégias de treinamento diferentes. A escolha certa depende do problema a ser resolvido, seja o objetivo contar veículos, ler texto ou mapear o uso da terra com alto nível de detalhe.
Medição de desempenho
Os modelos de reconhecimento de imagem são avaliados usando métricas como acurácia, precisão, recall e interseção sobre união.
A acurácia por si só costuma ser enganosa. Um modelo que raramente detecta um objeto pode parecer preciso simplesmente porque o objeto é raro. Precisão e revocação fornecem uma visão mais clara da confiabilidade do modelo.
Os testes devem sempre ser feitos com dados que o modelo nunca viu antes. Isso ajuda a revelar se o sistema aprendeu padrões gerais ou apenas memorizou o conjunto de treinamento.
Complexidade, viés e limitações práticas no mundo real
O reconhecimento de imagens por IA funciona melhor em ambientes controlados, mas os ambientes reais raramente são controlados. Assim que os modelos saem do laboratório e enfrentam condições do mundo real, suas limitações se tornam muito mais visíveis.
Por que as condições do mundo real são difíceis de modelar
A iluminação muda ao longo do dia. Objetos se sobrepõem ou desaparecem parcialmente da vista. As condições climáticas interferem na visibilidade. As câmeras se movem, falham ou capturam dados imperfeitos. Tudo isso introduz ruído que os modelos precisam aprender a lidar.
Um sistema que apresenta bom desempenho em testes pode ter dificuldades quando essas variáveis se acumulam. É por isso que testes contínuos, monitoramento e treinamento contínuo são partes essenciais de qualquer sistema de produção, e não melhorias opcionais.
O papel da supervisão humana
O reconhecimento de imagens por IA é poderoso, mas não infalível. Em aplicações críticas para a segurança ou de alto impacto, a revisão humana continua sendo necessária. Os humanos fornecem contexto, discernimento e responsabilidade em situações onde as decisões automatizadas, por si só, não são suficientes.
Como o viés influencia os sistemas de reconhecimento de imagem
Os modelos aprendem diretamente com os dados com os quais são treinados, incluindo suas lacunas e desequilíbrios. Se certos ambientes, populações ou condições estiverem sub-representados, o desempenho será prejudicado nesses casos.
O viés torna-se especialmente problemático em áreas como vigilância, controle de acesso ou segurança pública, onde os erros podem ter consequências reais. Esses problemas raramente são causados apenas por algoritmos.
Por que o viés não é um problema puramente técnico
Não existe uma solução técnica única para o viés. Melhorar a imparcialidade e a confiabilidade exige:
- Conjuntos de dados mais diversos e representativos
- Avaliação cuidadosa em diferentes cenários
- Revisão contínua de como os modelos são usados e atualizados.
O viés é, em última análise, um desafio relacionado a dados e processos. Lidá-lo exige escolhas deliberadas, e não apenas modelos melhores.

Privacidade e Considerações Éticas
O reconhecimento de imagens frequentemente envolve dados sensíveis. Rostos, localizações e comportamentos podem ser inferidos a partir de imagens, às vezes sem que o sujeito esteja totalmente ciente disso.
O uso responsável depende de mais do que precisão técnica. Requer regras claras e limites conscientes, incluindo:
- Políticas transparentes de coleta e uso de dados
- Consentimento explícito quando houver envolvimento de dados pessoais.
- Armazenamento seguro e acesso controlado aos dados de imagem.
- Conformidade com as regulamentações de privacidade locais e internacionais
- Responsabilização clara pela forma como as decisões tomadas pelo sistema são utilizadas.
As considerações éticas não são um detalhe secundário. Elas moldam a confiança pública, a aceitação legal e a viabilidade dos sistemas de reconhecimento de imagem a longo prazo.
Por que o reconhecimento de imagem é importante
Apesar dos desafios, o reconhecimento de imagens por IA tornou-se uma ferramenta essencial em diversos setores. Ele possibilita a automação em situações onde a inspeção humana seria lenta, cara ou inconsistente.
Desde diagnósticos na área da saúde até agricultura, monitoramento de infraestrutura e varejo, a capacidade de extrair informações de dados visuais muda a forma como as decisões são tomadas.
O verdadeiro valor não reside em substituir o julgamento humano, mas em aprimorá-lo. A IA lida com a escala e a velocidade. Os humanos lidam com o contexto e a responsabilidade.
Conclusão: Dos pixels às decisões
O reconhecimento de imagens por IA funciona porque divide uma habilidade humana complexa em etapas gerenciáveis. Pixels se transformam em números. Números se transformam em padrões. Padrões se transformam em previsões. Não existe um momento mágico em que uma máquina repentinamente entende uma imagem. Existe apenas aprendizado, iteração e refinamento.
Compreender como esse processo funciona ajuda a estabelecer expectativas realistas. Também ajuda as equipes a construir sistemas melhores, fazer perguntas mais pertinentes e usar a tecnologia de forma mais responsável. No fim das contas, o reconhecimento de imagem não se trata de máquinas enxergando como humanos. Trata-se de máquinas enxergando de forma diferente e usando essa diferença para tomar decisões mais rápidas e consistentes quando necessário.
Perguntas frequentes
O reconhecimento de imagens por IA é o processo de ensinar um computador a identificar padrões em imagens. Em vez de compreender as imagens da mesma forma que os humanos, o sistema aprende com exemplos e usa números e probabilidades para decidir o que está observando.
Não. A IA não compreende imagens conceitualmente. Ela processa valores de pixels e aprende padrões com base em relações estatísticas. Os resultados podem parecer semelhantes à percepção humana, mas o processo é completamente diferente.
A maioria dos sistemas modernos de reconhecimento de imagens utiliza aprendizado profundo, particularmente redes neurais convolucionais. Esses modelos são projetados para aprender características visuais como bordas, formas e texturas por meio de múltiplas camadas.
Isso depende da tarefa. Problemas simples de classificação podem funcionar com milhares de imagens, enquanto tarefas complexas de detecção ou segmentação geralmente exigem dezenas ou centenas de milhares de exemplos rotulados. A qualidade dos dados é tão importante quanto a quantidade.
A anotação informa ao modelo o que ele deve aprender com cada imagem. Rotulagem inadequada leva a previsões imprecisas. A anotação de alta qualidade costuma ser a parte mais demorada da construção de um sistema de reconhecimento de imagens, mas afeta diretamente a precisão e a confiabilidade.