

O reconhecimento de imagens pode parecer intimidante à primeira vista. Redes neurais, conjuntos de dados, ciclos de treinamento, GPUs – pode parecer muita coisa antes mesmo de escrever uma linha de código. Mas, na prática, construir uma IA para reconhecimento de imagens tem mais a ver com tomar boas decisões passo a passo do que dominar tudo de uma vez.
Em sua essência, o reconhecimento de imagens consiste em ensinar um sistema a perceber padrões em imagens e a fazer julgamentos consistentes com base no que vê. Isso pode significar identificar objetos, classificar cenas, detectar defeitos ou sinalizar anomalias. A tecnologia por trás disso é poderosa, mas o processo em si é surpreendentemente simples: definir a tarefa, preparar os dados, treinar um modelo, testá-lo rigorosamente e implementá-lo onde for realmente útil.
Este artigo descreve esse processo de forma prática e objetiva. Sem exageros, sem atalhos e sem a suposição de que você está escrevendo um artigo científico. Apenas uma análise clara de como a IA de reconhecimento de imagem é construída hoje, o que realmente importa em cada etapa e onde as pessoas geralmente erram.

Comece com um problema que você possa descrever claramente.
Antes de mexer com dados ou modelos, você precisa de uma tarefa bem definida. Não "reconhecer imagens", mas algo concreto.
- Você está classificando uma imagem inteira em uma única categoria?
- Você está encontrando objetos e desenhando caixas ao redor deles?
- Você está identificando formas ou limites exatos em nível de pixel?
Cada um desses problemas é diferente, com custos e riscos distintos.
Muitos projetos fracassam porque começam vagos e se complicam tarde demais. Se você não consegue explicar seu objetivo em uma frase para alguém sem conhecimento técnico, ele ainda não está pronto.
Bons exemplos
- “Detectar danos visíveis nos painéis da carroceria a partir de fotos.”
- “Contar toras empilhadas em imagens aéreas.”
- “Identificar se uma área de cultivo apresenta sinais precoces de estresse.”
Maus exemplos
- “Use IA para analisar imagens.”
- “Construa um sistema de visão computacional inteligente.”
Clareza neste momento pode economizar meses mais tarde.
Entenda como as imagens se transformam em números
Um computador não vê objetos. Ele vê matrizes de números.
Cada imagem é convertida em pixels, e cada pixel se transforma em valores que representam intensidade ou cor. Uma imagem colorida não é uma figura para um modelo. É uma grade de números distribuída por múltiplos canais.
O reconhecimento de imagens funciona aprendendo padrões dentro desses números. Bordas, formas, texturas, contrastes. Não porque o modelo entenda o significado, mas porque encontra regularidades estatísticas que se correlacionam com os rótulos.
Isso é importante porque muda a forma como você pensa sobre a qualidade dos dados. Se o modelo falha, geralmente é porque os números que ele recebe são inconsistentes, ruidosos ou enganosos.
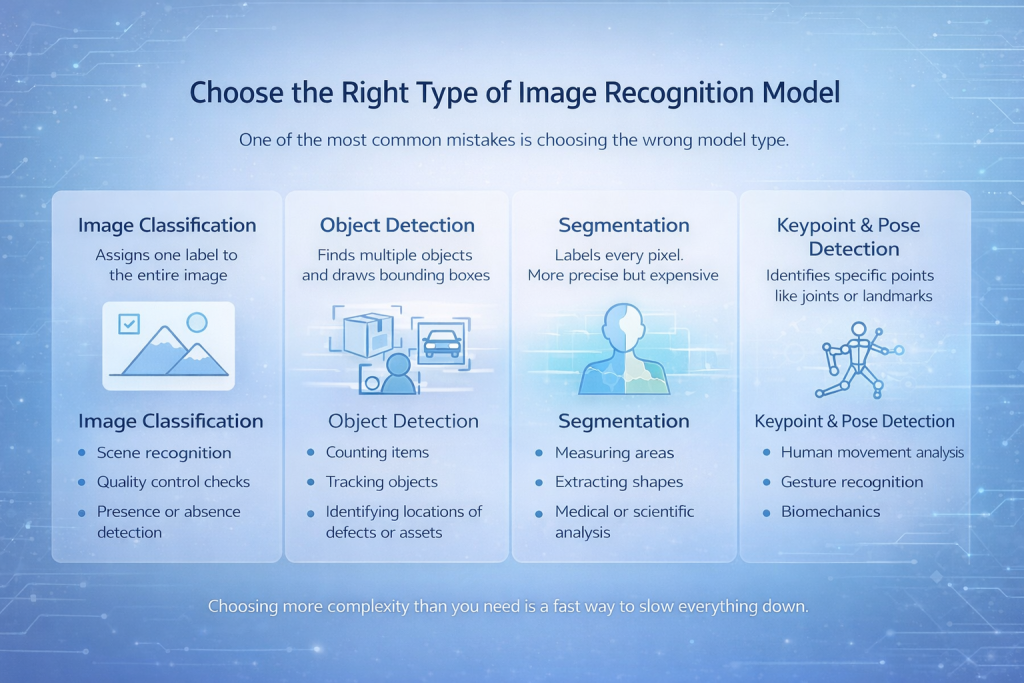
Escolha o tipo certo de modelo de reconhecimento de imagem
Um dos erros mais comuns é escolher o tipo de modelo errado.
Existem várias categorias principais:
Classificação de imagens
O modelo atribui um único rótulo à imagem inteira. Simples, rápido e eficaz quando o objeto de interesse domina a imagem.
Melhor para:
- reconhecimento de cena
- Verificações de controle de qualidade
- Detecção de presença ou ausência
Object Detection
O modelo encontra múltiplos objetos e desenha caixas delimitadoras ao redor deles.
Melhor para:
- Contagem de itens
- Rastreamento de objetos
- Identificar a localização de defeitos ou ativos.
Segmentação
Cada pixel recebe uma etiqueta. Isso é mais preciso e mais caro.
Melhor para:
- Áreas de medição
- Extraindo formas
- Análise médica ou científica
Detecção de pontos-chave e poses
O modelo identifica pontos específicos, como articulações ou pontos de referência.
Melhor para:
- Análise do movimento humano
- Reconhecimento de gestos
- Biomecânica
Escolher um nível de complexidade maior do que o necessário é uma maneira rápida de tornar tudo mais lento.
Os dados não são apenas importantes. Eles são o projeto.
Os modelos chamam a atenção. Os dados é que fazem o trabalho de verdade.
Um sistema robusto de reconhecimento de imagens depende muito mais do conjunto de dados do que da arquitetura. O modelo mais avançado falhará se os dados forem fracos ou inconsistentes.
Princípios fundamentais que realmente importam:
Variedade de dados é mais importante que volume de dados
Dez mil imagens semelhantes costumam ser piores do que duas mil imagens diversas. Ângulos, condições de iluminação, planos de fundo, resoluções e tipos de dispositivos diferentes importam mais do que a quantidade bruta de imagens.
Os rótulos devem corresponder à realidade.
Se os humanos discutirem sobre os rótulos, o modelo aprenderá a lidar com a confusão. Classes ambíguas devem ser mescladas ou redefinidas o quanto antes.
O equilíbrio é importante
Se uma classe domina, a precisão torna-se enganosa. Um modelo pode ser "preciso" ao sempre prever a classe majoritária.
A anotação é onde a qualidade é conquistada ou perdida.
A rotulagem costuma ser feita às pressas, e isso fica evidente mais tarde. Anotações ruins criam problemas difíceis de detectar durante o treinamento, mas dolorosamente óbvios no uso real. Os modelos se tornam instáveis, as previsões parecem aleatórias e os casos extremos se acumulam. Cada imagem rotulada incorretamente prejudica silenciosamente o processo de aprendizado.
Uma boa anotação começa com regras de rotulagem claras que todos seguem da mesma maneira. Quando pessoas diferentes interpretam os rótulos de maneiras distintas, o modelo aprende confusão em vez de padrões. A consistência é tão importante quanto a precisão, e é por isso que verificações pontuais regulares e pequenas auditorias são essenciais. Elas ajudam a detectar desvios precocemente, antes que se espalhem pelo conjunto de dados.
A anotação também precisa de espaço para evoluir. À medida que novos casos extremos surgem, os rótulos devem ser refinados em vez de serem forçados a definições que já não se encaixam. Esse tipo de limpeza iterativa é lento, mas compensa em termos de estabilidade do modelo.
As ferramentas de rotulagem assistidas por IA podem acelerar o processo, especialmente em grandes conjuntos de dados, mas não substituem o julgamento humano. Elas simplesmente repetem a lógica que lhes é fornecida. Se as regras forem obscuras ou falhas, a automação irá ampliar o erro, em vez de corrigi-lo.
O pré-processamento não é cosmético.
O pré-processamento não se resume a deixar as imagens com uma aparência impecável. Trata-se de reduzir variações indesejadas e realçar o que realmente importa.
Medidas comuns que realmente ajudam:
- Redimensionar imagens para uma resolução consistente
- Normalizando os valores dos pixels
- Corrigindo a orientação
- Recortar áreas irrelevantes
O aumento de dados merece atenção especial. Transformações simples como rotação, inversão, ajustes de brilho ou injeção de ruído podem melhorar drasticamente a generalização. O objetivo não é enganar o modelo, mas prepará-lo para a realidade.
Se seus dados parecerem perfeitos demais, seu modelo entrará em pânico no mundo real.
A arquitetura do modelo importa menos do que você pensa.
Existe uma forte tentação de seguir o modelo mais recente ou mais comentado. Transformadores, redes robustas e pipelines complexos podem parecer impressionantes no papel, mas não garantem melhores resultados.
Na prática, muitos sistemas confiáveis de reconhecimento de imagens são construídos sobre arquiteturas bem estabelecidas. As redes neurais convolucionais ainda dominam esse campo por um motivo: elas são estáveis, eficientes e mais fáceis de entender quando algo dá errado. Essa confiabilidade muitas vezes importa mais do que obter alguns pontos percentuais extras em testes de desempenho.
A aprendizagem por transferência geralmente é o ponto de partida mais inteligente. Usar um modelo que já aprendeu com conjuntos de dados grandes e diversos fornece uma base sólida, especialmente quando seus próprios dados são limitados. O ajuste fino funciona melhor quando a nova tarefa é razoavelmente semelhante ao que o modelo já viu antes, quando o sobreajuste é controlado ativamente e quando o re-treinamento é feito com cuidado, em vez de de forma agressiva. Ajustes pequenos e deliberados tendem a ter um desempenho melhor do que o re-treinamento por força bruta.
Modelos maiores nem sempre são modelos melhores. Eles custam mais para treinar, são mais difíceis de depurar e frequentemente falham de maneiras sutis e difíceis de rastrear.
O treinamento é uma conversa iterativa com seus dados.
O treinamento não é uma operação de um clique. É um processo contínuo.
Você treina, observa os resultados, identifica padrões de falha, ajusta os dados ou parâmetros e repete o processo.
Práticas essenciais de treinamento:
- Utilize conjuntos de treinamento, validação e teste separados.
- Observe as curvas de perda, não apenas a precisão.
- Pare de treinar quando a melhora estagnar.
- Ajuste cuidadosamente a taxa de aprendizado e o tamanho do lote.
A aceleração por GPU não é opcional para trabalhos sérios. O treinamento em CPUs é adequado para aprendizado, mas impraticável para projetos reais. As GPUs reduzem o tempo de iteração, o que melhora diretamente a qualidade do modelo, permitindo a experimentação.
A avaliação deve ir além da precisão.
A precisão é uma das métricas mais fáceis de calcular e uma das mais fáceis de interpretar erroneamente. Um modelo pode parecer altamente preciso e ainda assim ser inútil em condições reais.
Uma boa avaliação vai além. Matrizes de confusão ajudam a expor onde o modelo consistentemente toma decisões erradas. Precisão e revocação são muito mais informativas quando as classes estão desbalanceadas ou quando certos erros são mais custosos do que outros. Testar com imagens completamente novas e do mundo real frequentemente revela problemas que nunca aparecem em dados de validação limpos.
A etapa de avaliação mais valiosa ainda é a revisão manual. Analisar diretamente as previsões falhas e questionar os motivos pelos quais elas ocorreram fornece insights que nenhuma métrica consegue capturar completamente. Os modelos são surpreendentemente honestos sobre suas fragilidades se você dedicar tempo para examinar seus erros em vez de confiar apenas em números resumidos.
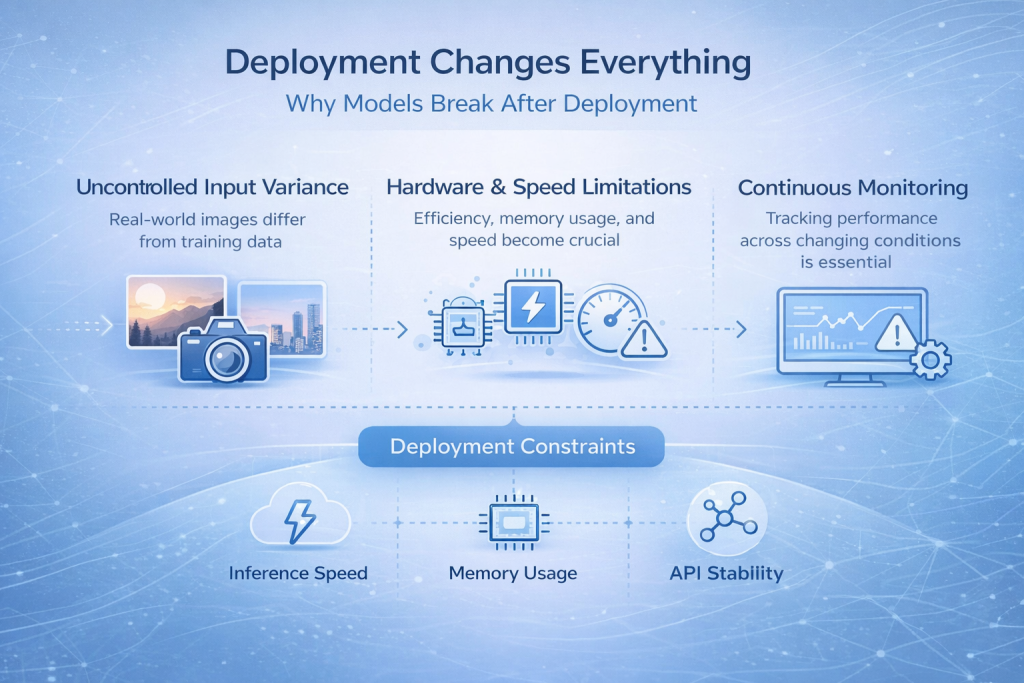
A implantação muda tudo.
Por que os modelos param de funcionar após a implantação
Muitos modelos de reconhecimento de imagem têm um bom desempenho durante o desenvolvimento, mas falham silenciosamente após a implementação. Este é um dos momentos mais comuns e frustrantes de todo o processo.
O motivo é simples. Os dados de entrada do mundo real raramente se parecem com os dados de treinamento. As imagens vêm de câmeras diferentes, as condições de iluminação mudam ao longo do dia, artefatos de compressão aparecem e os usuários não seguem padrões de uso ideais. Mesmo pequenas mudanças na forma como as imagens são capturadas podem levar um modelo para fora do espaço em que ele aprendeu a operar.
O que parecia estável em um ambiente controlado de repente se torna não confiável.
As restrições que você não pode ignorar
A implementação força você a pensar além da precisão do modelo. A velocidade de inferência torna-se crítica quando as previsões são necessárias em tempo real. O uso de memória importa quando o modelo é executado em dispositivos de borda ou hardware móvel. As limitações de hardware ditam que tipo de arquiteturas são viáveis, e a estabilidade da API torna-se essencial quando outros sistemas dependem de suas previsões.
O monitoramento também deixa de ser um diferencial e se torna uma necessidade. Sem visibilidade de como o modelo se comporta após o lançamento, as falhas podem passar despercebidas até que a confiança seja perdida.
Tornando o modelo utilizável
Exportar um modelo para formatos como TensorFlow Lite ou ONNX não é apenas uma etapa técnica no final do processo. Faz parte da transformação de um modelo treinado em algo que possa ser efetivamente usado em produção. Esses formatos ajudam a adaptar o modelo a diferentes ambientes, reduzir a sobrecarga e melhorar a compatibilidade com os destinos de implantação.
Um modelo que apresenta bom desempenho em um notebook, mas não resiste à implementação, não está finalizado. O verdadeiro sucesso só acontece quando o sistema funciona de forma consistente no ambiente para o qual foi projetado.
Reconhecimento de imagens no mundo real: como o implementamos na FlyPix AI
No FlyPix IA, Não encaramos o reconhecimento de imagens como um exercício de laboratório. Trabalhamos diariamente com imagens de satélite, aéreas e de drones, em cenários complexos, com objetos sobrepostos e condições nunca perfeitas. Essa realidade molda a forma como desenvolvemos e utilizamos a IA.
Nosso objetivo sempre foi simples: eliminar o gargalo da análise visual manual. As equipes gastavam centenas de horas anotando imagens, verificando resultados e verificando-os novamente sempre que as condições mudavam. Criamos o FlyPix para automatizar esse trabalho usando agentes de IA capazes de detectar, monitorar e inspecionar objetos em grande escala, sem sacrificar a precisão.
O que mais importa para nós é a praticidade. Você não precisa de conhecimento profundo em IA ou de uma equipe de engenheiros de aprendizado de máquina para treinar um modelo que funcione para o seu caso de uso. Com o FlyPix, as equipes podem criar modelos personalizados de reconhecimento de imagem usando suas próprias anotações, focados nos objetos que realmente importam em seu setor. Canteiros de obras, portos, terras agrícolas, ativos de infraestrutura, áreas florestais – as imagens são diferentes, mas o desafio é o mesmo.
Também projetamos tudo pensando na implementação. Os dados geoespaciais do mundo real mudam constantemente, portanto, os modelos devem lidar com variações desde o primeiro dia. Isso significa construir sistemas que funcionem de forma confiável fora de ambientes de demonstração limpos, processem grandes volumes de imagens rapidamente e forneçam resultados que as equipes possam usar imediatamente. Para nós, o reconhecimento de imagem só é bem-sucedido quando se mostra eficaz nas operações diárias, e não apenas durante os testes.
Ciclos de feedback mantêm o modelo ativo
Uma IA de reconhecimento de imagem não é estática. Os dados mudam. Os ambientes mudam. As expectativas mudam.
Sistemas duradouros são projetados levando em consideração o feedback:
- Coletar novas imagens após a implantação
- Casos de falha de rastreamento
- Recicle periodicamente
- Ajuste os rótulos quando a realidade mudar.
Ignorar o aprendizado pós-implantação é uma das maneiras mais rápidas de perder a confiança no sistema.
Conclusão
Criar uma IA de reconhecimento de imagens que realmente funcione não se resume a seguir os modelos mais recentes, mas sim a acertar os fundamentos. Definição clara do problema, trabalho disciplinado com os dados, avaliação criteriosa e planejamento realista de implementação são muito mais importantes do que a escolha de um único algoritmo.
Os sistemas mais confiáveis não são os mais complexos. São aqueles construídos com uma compreensão genuína de como as imagens se alteram no mundo real e como os modelos reagem a essas alterações. São treinados com dados que refletem a realidade, avaliados com métricas que revelam fragilidades e implementados considerando as limitações desde o início.
Se há uma lição a tirar, é esta: o reconhecimento de imagem é um processo de engenharia, não um experimento isolado. Quando você o encara dessa forma, itera cuidadosamente e se mantém focado em aplicações reais, os resultados tendem a se manter muito tempo depois do término da demonstração.
Perguntas frequentes
A inteligência artificial para reconhecimento de imagens é um tipo de sistema de visão computacional que aprende a identificar padrões, objetos ou características em imagens. Ela funciona analisando dados de pixels e usando modelos treinados para associar padrões visuais a rótulos ou resultados.
Nem sempre. Embora grandes conjuntos de dados ajudem, a diversidade e a qualidade importam mais do que o volume bruto. Com a aprendizagem por transferência e o aumento de dados adequado, modelos úteis podem ser treinados em conjuntos de dados relativamente pequenos, mas bem selecionados.
Para a maioria dos projetos, começar com uma rede neural convolucional comprovada e aplicar aprendizado por transferência é uma abordagem segura e eficaz. Modelos mais complexos só devem ser usados quando houver uma razão clara e dados suficientes para justificá-los.
A acurácia por si só não basta. Você deve analisar as matrizes de confusão, a precisão e a revocação, e testar o modelo em imagens do mundo real que nunca fizeram parte do treinamento. A revisão manual das falhas costuma ser a etapa mais reveladora.
Isso geralmente ocorre porque as imagens de produção diferem dos dados de treinamento. Alterações na iluminação, na qualidade da câmera, na compressão da imagem ou no comportamento do usuário podem afetar o desempenho. Essa discrepância é comum e deve ser prevista durante o desenvolvimento.
Sim. A implantação não é uma etapa final que pode ser ignorada até o fim. Limitações de hardware, velocidade de inferência, uso de memória e requisitos de integração influenciam a forma como o modelo deve ser construído e treinado.