
AI image recognition sounds complex, but at its core, it’s about teaching machines to see patterns the way humans do – only faster and at a much larger scale. Every photo, satellite image, or video frame is just data until an AI system learns how to interpret it. That learning process is what turns raw pixels into meaningful signals: objects, shapes, text, or changes over time.
This article breaks down how AI image recognition actually works behind the scenes. Not in abstract theory, but in practical terms, how images become numbers, how models learn from examples, and why data quality matters more than flashy algorithms. If you’ve ever wondered what really happens between uploading an image and getting an automated result, this is where it starts.
What Image Recognition Really Means in AI
Image recognition is the ability of a machine to identify patterns, objects, text, or features inside an image and assign meaning to them. That meaning can be simple, like identifying a car, or complex, like detecting early signs of crop stress in aerial imagery.
Unlike traditional software, AI systems do not follow hard-coded rules such as “if it has four wheels, it is a car.” Instead, they learn from examples. Thousands or millions of labeled images are used to teach the system what something looks like across different conditions, angles, lighting, and environments.
At its core, image recognition is a form of pattern recognition driven by machine learning and, more specifically, deep learning. The system does not understand concepts. It learns statistical relationships between visual features and outcomes.
How We Turn AI Image Recognition Into Real-World Results at FlyPix
At FlyPix, we use AI image recognition as a practical tool for working with satellite, aerial, and drone imagery at scale. Our goal is to help teams move from raw images to clear insights without weeks of manual work or complex setup.
We rely on AI agents that can detect, monitor, and inspect objects across large and dense datasets. Users train custom AI models using their own imagery and annotations, without needing programming skills. You decide what matters in your data, and the system learns to recognize it consistently.
Speed is a big part of the value. What once required hours of manual annotation can now be done in seconds. From land-use classification and infrastructure inspection to agriculture and environmental monitoring, the focus is always on faster, more reliable decisions.
FlyPix is built to adapt to different industries and use cases, not force them into a single workflow. By keeping AI image recognition flexible and accessible, we make it easier for teams to apply it in everyday operations, not just experimental projects.
Everything Starts With Pixels
Every digital image is a grid of pixels. Each pixel contains numerical values that describe color and brightness. In most images, this means three values per pixel for red, green, and blue.
To a human, a photo of a street is immediately recognizable. To an AI model, that same image is a large matrix of numbers. There is no built-in understanding of roads, buildings, or people. The challenge of image recognition is teaching a system how to interpret these numbers in a meaningful way.
Before any learning happens, the image is converted into a numerical format that the model can process. Resolution, color depth, and file structure all affect how much information is available and how heavy the computation becomes.
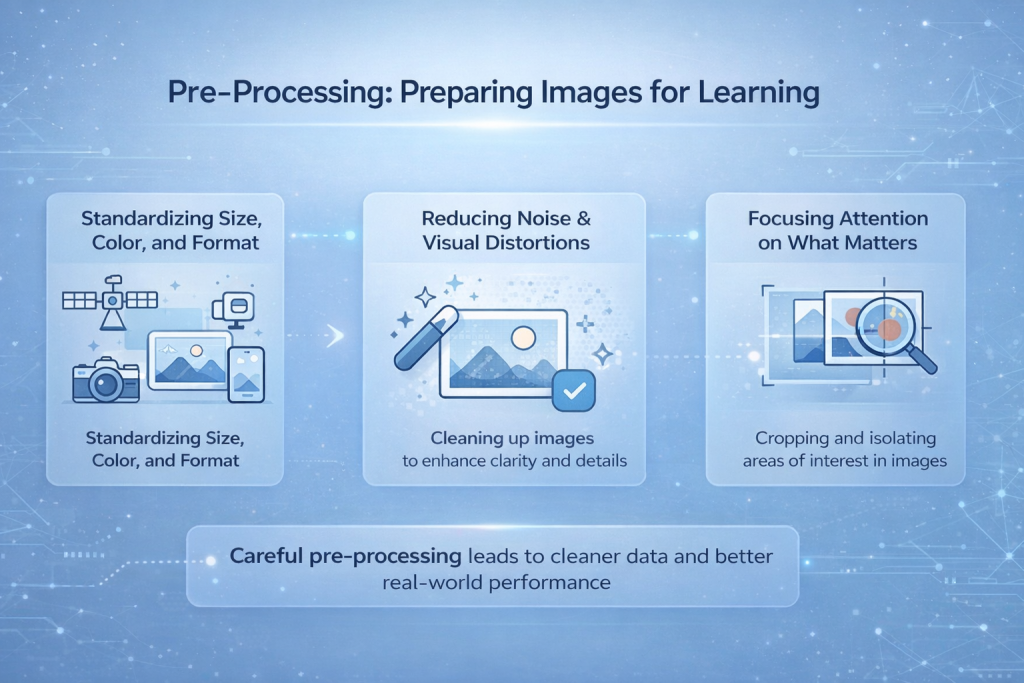
Pre-Processing: Preparing Images for Learning
Images collected from cameras, drones, satellites, or phones are almost never consistent. They come in different resolutions, lighting conditions, angles, and file formats. Some are sharp, others noisy or blurred. Feeding this raw mix directly into a model makes learning unstable and unpredictable. Pre-processing is the step where this visual chaos is brought under control.
Standardizing Size, Color, and Format
One of the first tasks is making images uniform. Models expect a consistent input shape, so images are resized to a fixed resolution. Color values are normalized so that brightness and contrast differences do not overwhelm the learning process. This helps the model focus on structure instead of being distracted by exposure changes or camera settings.
Reducing Noise and Visual Distortions
Noise from sensors, motion blur, compression artifacts, or weather conditions can hide important details. Pre-processing techniques help reduce these effects, making edges and shapes easier for the model to detect. This step does not improve the image in a human sense, but it improves how readable the data is for the network.
Focusing Attention on What Matters
In many cases, only part of an image is relevant. Cropping, masking, or isolating regions of interest helps remove distractions. By limiting what the model sees, learning becomes faster and more precise, especially in tasks like object detection or medical imaging.
Why Pre-Processing Directly Affects Real-World Performance
Pre-processing does not make a model smarter on its own. What it does is create cleaner conditions for learning. When this step is rushed or poorly designed, models may perform well in controlled tests but break down in real-world situations. Careful pre-processing is often the difference between a system that works in theory and one that works in practice.
Feature Learning: How AI Finds Patterns
Humans learn to recognize objects by noticing features. Edges, shapes, textures, and proportions all play a role. AI models learn in a similar but more mathematical way.
Most modern image recognition systems rely on convolutional neural networks, or CNNs. These networks are designed to scan images using small filters that move across the image and detect local patterns.
Early layers in a CNN tend to detect very simple features like edges, corners, and color gradients. Middle layers combine those into shapes and textures. Deeper layers assemble those shapes into higher-level patterns that correspond to objects or regions of interest.
The key idea is hierarchy. The model does not jump directly from pixels to “this is a tree.” It builds that understanding layer by layer.
Why Convolution Matters
Convolution allows the same pattern detector to be applied across the entire image. A vertical edge is still a vertical edge whether it appears on the left side or the right side of the image.
This approach makes models more efficient and more robust. Instead of memorizing exact pixel arrangements, the system learns reusable visual patterns. This is one reason CNNs work so well across different image sizes and layouts.
Pooling layers are often added to reduce the size of the data while keeping important information. This helps control computation costs and prevents the model from becoming too sensitive to tiny variations.
Training the Model: Learning From Examples
Training is where image recognition actually happens. The model is shown a large set of labeled images. Each image is paired with the correct answer, such as “healthy crop,” “damaged road,” or “person present.”
During training, the process follows a repeating loop:
- The model analyzes an input image and generates a prediction
- The prediction is compared to the correct label
- The difference between the two is measured as an error
- The model adjusts its internal parameters to reduce that error
- The same process is repeated across thousands or millions of examples
This gradual adjustment is what allows the system to improve over time.
Backpropagation is the mechanism that makes this learning possible. It traces errors backward through the network and updates the weights of each layer so future predictions become more accurate.
The quality of training depends heavily on the data used. If the dataset is too small, poorly labeled, or biased toward certain conditions, the model will inherit those weaknesses. No amount of tuning can fully compensate for low-quality or unbalanced training data.
The Role of Labeled Data
Labeled data is the foundation of supervised image recognition. Every label tells the model what it should learn from an image.
Creating these labels is often the most expensive and time-consuming part of the process. Human annotators must carefully mark objects, draw bounding boxes, segment regions, or classify images.
High-quality annotation leads to better models. Poor annotation leads to confusion and unreliable results. This is why many image recognition failures can be traced back to the dataset rather than the algorithm.
Transfer Learning And Inference: From a Pretrained Model to Real Predictions
Training a deep neural network from scratch takes a lot of labeled data and serious computing power, which is why many teams do not start from zero. Instead, they use transfer learning.
How Transfer Learning Works
Transfer learning starts with a model that has already learned general visual features from a large dataset. That pretrained model already understands common patterns like edges, textures, and shapes. From there, it is fine-tuned for a specific job using a smaller, task-focused dataset.
In practice, the early layers usually stay mostly the same, while later layers are retrained to match the new task. For example, a model trained on general images can be adapted to recognize defects in industrial components or patterns in medical scans. This approach speeds up development and often improves accuracy, especially when your dataset is limited.
From Training to Inference
Once the model is trained or fine-tuned, it moves into inference mode. This is the stage where it processes new, unseen images and produces predictions.
The inference pipeline mirrors the training pipeline:
- Images are pre-processed
- They are passed through the network
- The output is returned as labels, probabilities, detected objects, or segmented regions
At this point, the priority shifts. The goal is no longer learning, it is consistent performance. In real systems, inference often needs to run in real time or near real time, so speed and reliability matter just as much as raw accuracy.
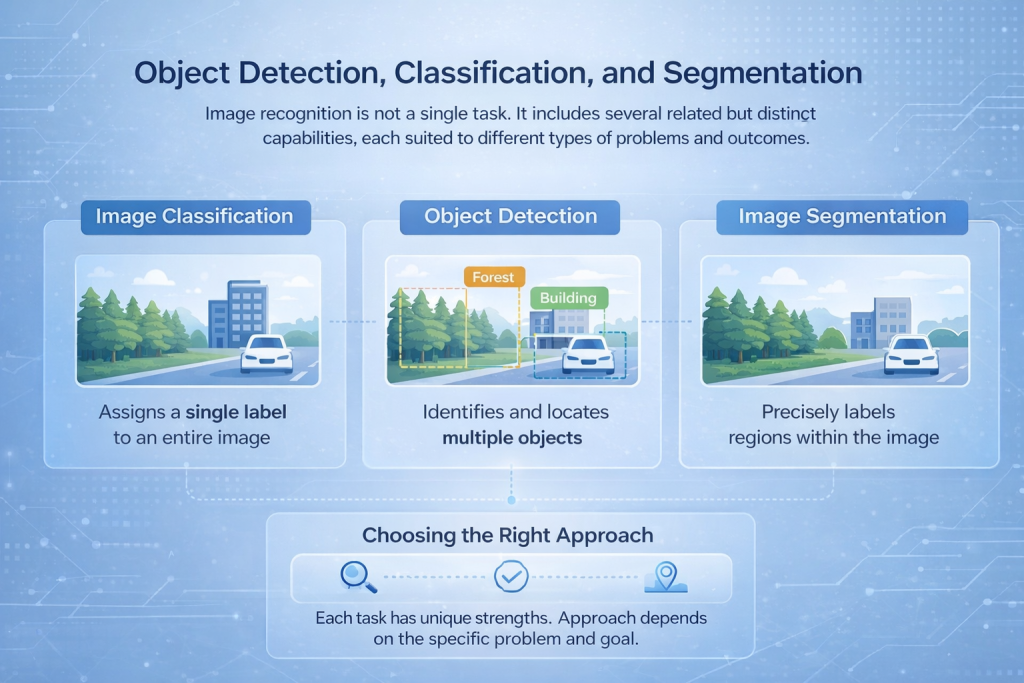
Object Detection, Classification, and Segmentation
Image recognition is not a single task. It includes several related but distinct capabilities, each suited to different types of problems and outcomes.
Image Classification
Image classification assigns one label to an entire image. The model looks at the full scene and decides what best describes it, such as identifying whether an image contains a forest, a building, or a vehicle. This approach works well when the overall content matters more than precise location.
Object Detection
Object detection goes a step further by identifying and locating multiple objects within the same image. Instead of a single label, the model draws bounding boxes around items of interest and classifies each one. This is commonly used in applications like traffic monitoring, security systems, and industrial inspection.
Image Segmentation
Segmentation provides the most detailed level of analysis. It labels individual pixels or regions within an image, allowing the system to separate objects with high precision. This is essential in use cases like medical imaging, land-use mapping, or surface analysis, where exact boundaries matter.
Choosing the Right Approach
Each of these tasks requires different network architectures and training strategies. The right choice depends on the problem being solved, whether the goal is counting vehicles, reading text, or mapping land use at a fine level of detail.
Measuring Performance
Image recognition models are evaluated using metrics such as accuracy, precision, recall, and intersection over union.
Accuracy alone is often misleading. A model that rarely detects an object may appear accurate simply because the object is rare. Precision and recall provide a clearer picture of how reliable the model is.
Testing should always be done on data that the model has never seen before. This helps reveal whether the system has learned general patterns or merely memorized the training set.
Real-World Complexity, Bias, and Practical Limits
AI image recognition works best in controlled settings, but real environments are rarely controlled. Once models leave the lab and face real-world conditions, limitations become much more visible.
Why Real-World Conditions Are Hard to Model
Lighting changes throughout the day. Objects overlap or partially disappear from view. Weather interferes with visibility. Cameras move, fail, or capture imperfect data. All of this introduces noise that models must learn to handle.
A system that performs well in testing can struggle once these variables pile up. This is why continuous testing, monitoring, and retraining are essential parts of any production system, not optional improvements.
The Role of Human Oversight
AI image recognition is powerful, but it is not infallible. In safety-critical or high-impact applications, human review remains necessary. Humans provide context, judgment, and accountability in situations where automated decisions alone are not enough.
How Bias Enters Image Recognition Systems
Models learn directly from the data they are trained on, including its gaps and imbalances. If certain environments, populations, or conditions are underrepresented, performance will suffer in those cases.
Bias becomes especially problematic in areas like surveillance, access control, or public safety, where errors can have real consequences. These issues are rarely caused by algorithms alone.
Why Bias Is Not a Purely Technical Problem
There is no single technical fix for bias. Improving fairness and reliability requires:
- More diverse and representative datasets
- Careful evaluation across different scenarios
- Ongoing review of how models are used and updated
Bias is ultimately a data and process challenge. Addressing it requires deliberate choices, not just better models.

Privacy and Ethical Considerations
Image recognition often involves sensitive data. Faces, locations, and behaviors can be inferred from images, sometimes without the subject being fully aware of it.
Responsible use depends on more than technical accuracy. It requires clear rules and conscious limits, including:
- Transparent data collection and usage policies
- Explicit consent where personal data is involved
- Secure storage and controlled access to image data
- Compliance with local and international privacy regulations
- Clear accountability for how decisions made by the system are used
Ethical considerations are not an afterthought. They shape public trust, legal acceptance, and whether image recognition systems remain viable over the long term.
Why Image Recognition Matters
Despite its challenges, AI image recognition has become a critical tool across industries. It enables automation where human inspection would be slow, expensive, or inconsistent.
From healthcare diagnostics to agriculture, infrastructure monitoring to retail, the ability to extract insight from visual data changes how decisions are made.
The real value lies not in replacing human judgment, but in augmenting it. AI handles scale and speed. Humans handle context and responsibility.
Conclusion: From Pixels to Decisions
AI image recognition works because it breaks a complex human ability into manageable steps. Pixels become numbers. Numbers become patterns. Patterns become predictions. There is no magic moment where a machine suddenly understands an image. There is only learning, iteration, and refinement.
Understanding how this process works helps set realistic expectations. It also helps teams build better systems, ask better questions, and use the technology more responsibly. In the end, image recognition is not about machines seeing like humans. It is about machines seeing differently, and using that difference to make faster, more consistent decisions when it matters.
Frequently Asked Questions
AI image recognition is the process of teaching a computer to identify patterns in images. Instead of understanding pictures the way humans do, the system learns from examples and uses numbers and probabilities to decide what it is looking at.
No. AI does not understand images conceptually. It processes pixel values and learns patterns based on statistical relationships. The results may look similar to human perception, but the process is entirely different.
Most modern image recognition systems use deep learning, particularly convolutional neural networks. These models are designed to learn visual features such as edges, shapes, and textures through multiple layers.
That depends on the task. Simple classification problems may work with thousands of images, while complex detection or segmentation tasks often require tens or hundreds of thousands of labeled examples. Data quality matters as much as quantity.
Annotation tells the model what it should learn from each image. Poor labeling leads to poor predictions. High-quality annotation is often the most time-consuming part of building an image recognition system, but it directly affects accuracy and reliability.