

AIによる画像認識は複雑に聞こえるかもしれませんが、その本質は、機械に人間と同じようにパターンを認識させるように教えることです。ただし、より高速に、より大規模なスケールで認識させる必要があります。写真、衛星画像、動画フレームはすべて、AIシステムが解釈方法を学習するまでは単なるデータです。この学習プロセスによって、生のピクセルが意味のある信号、つまりオブジェクト、形状、テキスト、あるいは時間経過による変化に変換されます。.
この記事では、AIによる画像認識が実際にどのように舞台裏で機能しているかを解説します。抽象的な理論ではなく、実践的な観点から、画像がどのように数値化されるのか、モデルがどのように事例から学習するのか、そしてなぜデータの品質が派手なアルゴリズムよりも重要なのかを解説します。画像をアップロードしてから自動的に結果が表示されるまでの間に実際に何が起こっているのか疑問に思ったことがあるなら、この記事がその始まりです。.
AIにおける画像認識の真の意味
画像認識とは、画像内のパターン、物体、テキスト、または特徴を機械が識別し、それらに意味を割り当てる能力です。その意味は、車を識別するような単純なものから、航空写真から作物のストレスの初期兆候を検出するような複雑なものまで様々です。.
従来のソフトウェアとは異なり、AIシステムは「四輪車なら車」といったハードコードされたルールには従いません。代わりに、事例から学習します。数千、数百万枚のラベル付き画像を用いて、様々な条件、角度、照明、環境における物体の見え方をシステムに学習させます。.
画像認識の本質は、機械学習、より具体的にはディープラーニングによって駆動されるパターン認識の一種です。このシステムは概念を理解するのではなく、視覚的特徴と結果の間の統計的な関係を学習します。.
FlyPix で AI 画像認識を現実世界の成果に変える方法
で フライピックス, では、AI画像認識を、衛星画像、航空画像、ドローン画像を大規模に処理するための実用的なツールとして活用しています。私たちの目標は、チームが数週間にわたる手作業や複雑な設定なしに、生の画像から明確な洞察を得られるよう支援することです。.
私たちは、大規模で高密度なデータセット全体にわたって物体を検出、監視、検査できるAIエージェントを活用しています。ユーザーは、プログラミングスキルを必要とせず、独自の画像とアノテーションを使用してカスタムAIモデルをトレーニングできます。データの中で何が重要かを判断するだけで、システムはそれを一貫して認識するように学習します。.
スピードは価値の大きな部分を占めます。かつては手作業で何時間もかかっていたアノテーション作業が、今では数秒で完了します。土地利用分類やインフラ点検から農業や環境モニタリングまで、常に迅速かつ信頼性の高い意思決定が求められています。.
FlyPixは、単一のワークフローに押し付けるのではなく、様々な業界やユースケースに適応できるように構築されています。AI画像認識を柔軟かつアクセスしやすいものにすることで、実験的なプロジェクトだけでなく、日常業務にも容易に適用できるようになります。.
すべてはピクセルから始まる
すべてのデジタル画像はピクセルのグリッドで構成されています。各ピクセルには、色と明るさを表す数値が含まれています。ほとんどの画像では、1ピクセルあたり赤、緑、青の3つの値が含まれています。.
人間にとって、街路の写真はすぐに認識できます。しかし、AIモデルにとっては、同じ画像が膨大な数字の羅列に過ぎません。道路、建物、人物といったものをAIモデルがあらかじめ認識しているわけではありません。画像認識の課題は、これらの数字を意味のある形で解釈する方法をシステムに教えることです。.
学習を行う前に、画像はモデルが処理できる数値形式に変換されます。解像度、色深度、ファイル構造はすべて、利用可能な情報量と計算量に影響します。.
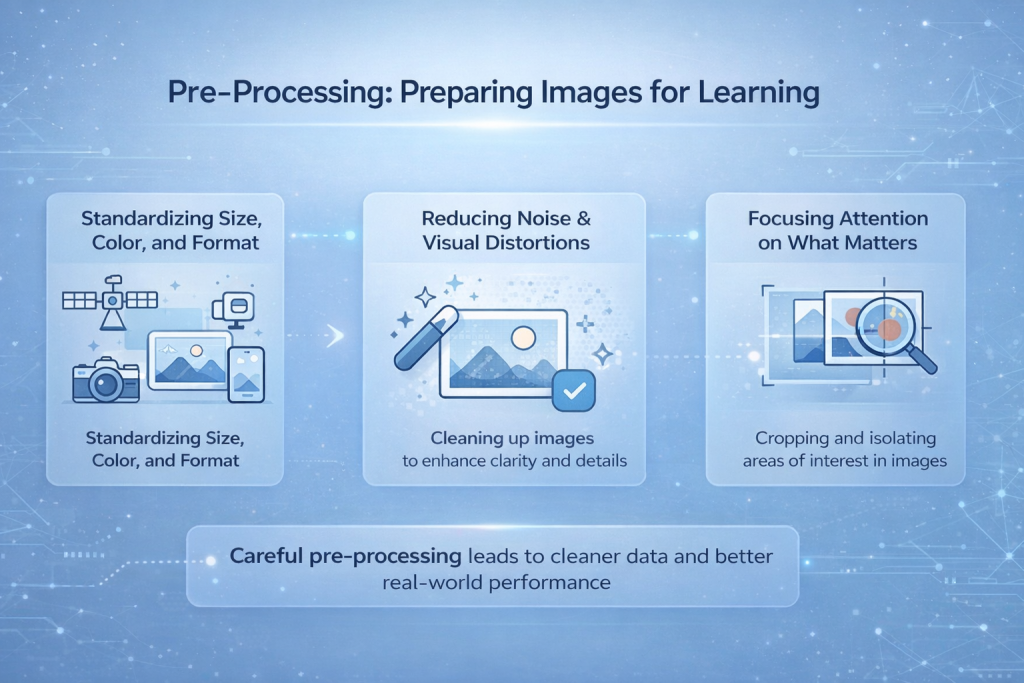
前処理:学習用画像の準備
カメラ、ドローン、衛星、スマートフォンなどから収集された画像は、ほとんど一貫性がありません。解像度、照明条件、角度、ファイル形式も様々です。鮮明なものもあれば、ノイズやぼやけが目立つものもあります。こうした生の画像をそのままモデルに入力すると、学習は不安定になり、予測不可能になります。前処理は、こうした視覚的な混沌を制御するためのステップです。.
サイズ、色、フォーマットの標準化
最初のタスクの一つは、画像を均一化することです。モデルは入力画像の形状が一定であると想定するため、画像は固定解像度にリサイズされます。色値は正規化されるため、明るさやコントラストの違いが学習プロセスに過大な影響を与えません。これにより、モデルは露出の変化やカメラ設定に惑わされることなく、構造に集中できるようになります。.
ノイズと視覚的な歪みを軽減する
センサーからのノイズ、モーションブラー、圧縮アーティファクト、あるいは気象条件によって、重要な詳細が隠れてしまうことがあります。前処理技術はこれらの影響を軽減し、モデルがエッジや形状を検出しやすくなります。この処理によって、人間の感覚で画像の品質が向上するわけではありませんが、ネットワークにとってのデータの可読性が向上します。.
重要なことに注目する
多くの場合、画像の一部だけが重要です。関心領域をトリミング、マスク、または分離することで、不要な情報を取り除くことができます。モデルが認識する領域を制限することで、特に物体検出や医用画像処理などのタスクにおいて、学習の速度と精度が向上します。.
前処理が実際のパフォーマンスに直接影響を与える理由
前処理は、それ自体ではモデルをより賢くするものではありません。学習のためのよりクリーンな環境を作り出すのです。このステップが急いでいたり、適切に設計されていなかったりすると、モデルは管理されたテストでは良好なパフォーマンスを示しても、現実世界の状況では機能しなくなる可能性があります。慎重な前処理は、理論上は機能するシステムと実際に機能するシステムの違いを生むことがよくあります。.
特徴学習:AIがパターンを見つける方法
人間は物体の特徴に注目することで認識を学習します。エッジ、形状、質感、比率など、すべてが重要な役割を果たします。AIモデルも同様ですが、より数学的な方法で学習します。.
現代の画像認識システムのほとんどは、畳み込みニューラルネットワーク(CNN)を利用しています。これらのネットワークは、画像上を移動する小さなフィルターを用いて画像をスキャンし、局所的なパターンを検出するように設計されています。.
CNNの初期層は、エッジ、コーナー、色のグラデーションといった非常に単純な特徴を検出する傾向があります。中間層は、これらを形状やテクスチャに組み合わせます。そして、より深い層は、これらの形状をオブジェクトや関心領域に対応する高次のパターンに組み立てます。.
鍵となるのは階層構造です。このモデルは、ピクセルから「これは木だ」と直接判断するのではなく、層ごとに理解を深めていきます。.
畳み込みが重要な理由
畳み込みにより、同じパターン検出器を画像全体に適用できます。垂直エッジは、画像の左側に現れても右側に現れても、垂直エッジのままです。.
このアプローチにより、モデルはより効率的かつ堅牢になります。システムは、正確なピクセル配置を記憶するのではなく、再利用可能な視覚パターンを学習します。これが、CNNがさまざまな画像サイズやレイアウトで非常にうまく機能する理由の一つです。.
プーリング層は、重要な情報を維持しながらデータサイズを削減するためによく追加されます。これにより計算コストを抑え、モデルが微細な変化に過度に敏感になるのを防ぐことができます。.
モデルのトレーニング:例からの学習
トレーニングでは、画像認識が実際に行われます。モデルにはラベル付けされた大量の画像セットが提示されます。各画像には、「健全な作物」「損傷した道路」「人がいる」といった正解が関連付けられます。“
トレーニング中、プロセスは次の繰り返しループに従います。
- モデルは入力画像を分析し予測を生成する
- 予測は正しいラベルと比較される
- 両者の差は誤差として測定される
- モデルは内部パラメータを調整してその誤差を減らす
- 同じプロセスが何千、何百万もの例で繰り返される
この段階的な調整により、システムは時間の経過とともに改善されます。.
この学習を可能にするメカニズムがバックプロパゲーションです。ネットワークを通じて誤差を遡及し、各層の重みを更新することで、将来の予測精度を高めます。.
トレーニングの質は、使用するデータに大きく依存します。データセットが小さすぎたり、ラベル付けが不十分だったり、特定の条件に偏っていたりすると、モデルはそれらの弱点を受け継いでしまいます。低品質または不均衡なトレーニングデータに対して、どんなにチューニングを施しても完全に補うことはできません。.
ラベル付きデータの役割
ラベル付きデータは教師あり画像認識の基盤です。すべてのラベルは、モデルが画像から何を学習すべきかを伝えます。.
これらのラベルの作成は、多くの場合、プロセスの中で最も費用と時間がかかる部分です。人間のアノテーターは、オブジェクトを慎重にマークし、境界ボックスを描画し、領域をセグメント化し、画像を分類する必要があります。.
高品質なアノテーションはより優れたモデルにつながります。質の低いアノテーションは混乱を招き、結果の信頼性を低下させます。そのため、多くの画像認識の失敗は、アルゴリズムではなくデータセットに起因しています。.
転移学習と推論:事前学習済みモデルから実際の予測へ
ディープニューラルネットワークをゼロから学習させるには、大量のラベル付きデータと高度な計算能力が必要です。そのため、多くのチームはゼロから始めるのではなく、転移学習を活用します。.
転移学習の仕組み
転移学習は、大規模なデータセットから一般的な視覚特徴を既に学習したモデルから始まります。この事前学習済みモデルは、エッジ、テクスチャ、形状といった一般的なパターンを既に理解しています。そこから、より小規模でタスクに焦点を絞ったデータセットを用いて、特定のジョブ向けに微調整されます。.
実際には、初期のレイヤーは基本的に同じままで、後期のレイヤーは新しいタスクに合わせて再学習されるのが一般的です。例えば、一般的な画像で学習したモデルを、工業用部品の欠陥や医療用スキャン画像のパターンを認識できるように適応させることができます。このアプローチは開発を加速させ、特にデータセットが限られている場合に精度を向上させる効果があります。.
トレーニングから推論へ
モデルがトレーニングまたは微調整されると、推論モードに移行します。これは、モデルが新しい、未知の画像を処理し、予測を生成する段階です。.
推論パイプラインはトレーニング パイプラインを反映します。
- 画像は前処理済み
- これらはネットワークを通じて渡される
- 出力はラベル、確率、検出されたオブジェクト、またはセグメント化された領域として返されます。
この時点で優先順位が変わります。目標はもはや学習ではなく、一貫したパフォーマンスです。実際のシステムでは、推論はリアルタイム、あるいはほぼリアルタイムで実行する必要があることが多いため、速度と信頼性は、純粋な精度と同じくらい重要になります。.
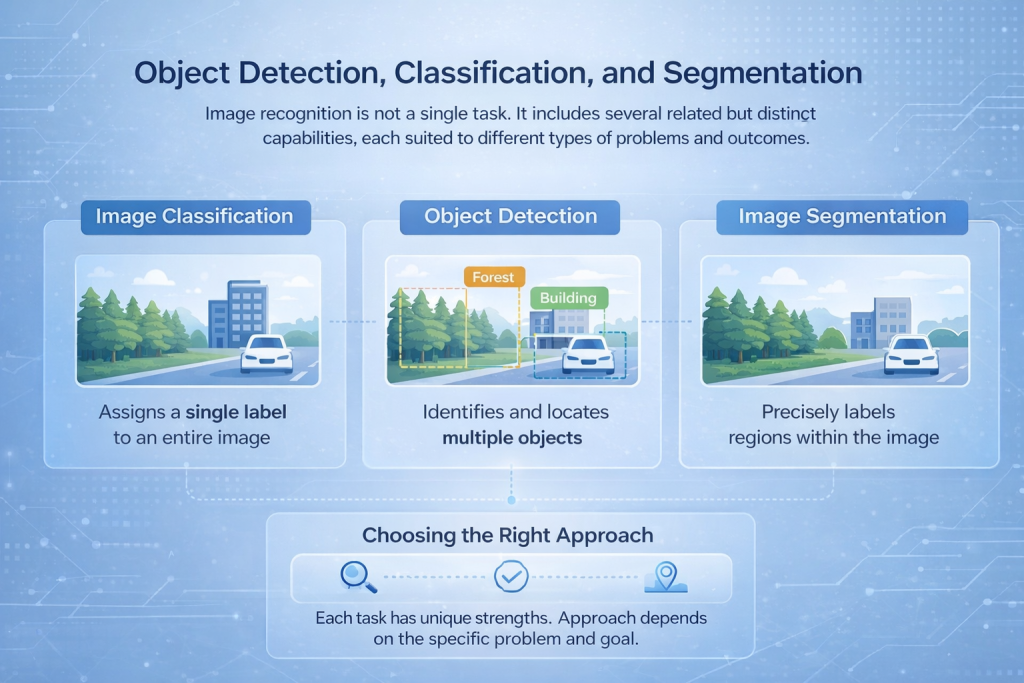
物体検出、分類、セグメンテーション
画像認識は単一のタスクではありません。関連性はあるものの異なる複数の機能が含まれており、それぞれが異なる種類の問題や結果に適しています。.
画像分類
画像分類では、画像全体に1つのラベルを割り当てます。モデルはシーン全体を見て、そのシーンを最もよく表すものを決定します。例えば、画像に森林、建物、車両が含まれているかどうかを識別します。このアプローチは、正確な位置よりも全体的なコンテンツが重要である場合に適しています。.
物体検出
物体検出はさらに一歩進んで、同一画像内の複数の物体を識別し、その位置を特定します。単一のラベルではなく、モデルは対象物の周囲に境界ボックスを描画し、それぞれを分類します。これは、交通監視、セキュリティシステム、産業検査などのアプリケーションで広く利用されています。.
画像セグメンテーション
セグメンテーションは、最も詳細な分析を提供します。画像内の個々のピクセルまたは領域にラベルを付けることで、システムは高精度にオブジェクトを分離できます。これは、医療用画像処理、土地利用マッピング、地表分析など、正確な境界が重要なユースケースにおいて不可欠です。.
適切なアプローチの選択
これらのタスクにはそれぞれ異なるネットワークアーキテクチャとトレーニング戦略が必要です。適切な選択は、車両のカウント、テキストの読み取り、あるいは詳細な土地利用のマッピングなど、解決する問題によって異なります。.
パフォーマンスの測定
画像認識モデルは、精度、適合率、再現率、和集合に対する交差などの指標を使用して評価されます。.
精度だけでは誤解を招くことがよくあります。ある物体をめったに検出しないモデルは、その物体が稀であるという理由だけで、正確に見える場合があります。適合率と再現率は、モデルの信頼性をより明確に示します。.
テストは常に、モデルがこれまでに見たことのないデータで実施する必要があります。これにより、システムが一般的なパターンを学習したのか、それとも単にトレーニングセットを記憶しただけなのかを明らかにすることができます。.
現実世界の複雑さ、バイアス、そして実用的な限界
AI画像認識は制御された環境で最も効果的に機能しますが、現実の環境では制御されることはほとんどありません。モデルが研究室を出て現実世界の状況に直面すると、限界がより顕著になります。.
現実世界の状況をモデル化するのがなぜ難しいのか
一日を通して照明は変化します。物体は重なったり、部分的に視界から消えたりします。天候によって視界が悪くなることもあります。カメラが動いたり、故障したり、不完全なデータを捉えたりします。これらすべてがノイズを発生させ、モデルはそれらに対処する方法を学習しなければなりません。.
テストでは良好なパフォーマンスを発揮するシステムでも、これらの変数が積み重なると、パフォーマンスが低下する可能性があります。だからこそ、継続的なテスト、監視、そして再トレーニングは、本番システムにおいて、単なるオプション的な改善ではなく、不可欠な要素なのです。.
人間の監督の役割
AI画像認識は強力ですが、絶対確実ではありません。安全性が極めて重要、あるいは影響度の高いアプリケーションでは、人間によるレビューが依然として必要です。自動化された判断だけでは不十分な状況では、人間が文脈、判断、そして説明責任を提供します。.
画像認識システムにバイアスが入り込む仕組み
モデルは、学習に使用したデータから、そのギャップや不均衡も含めて直接学習します。特定の環境、集団、または状況が十分に表現されていない場合、パフォーマンスが低下します。.
監視、アクセス制御、公共安全といった分野では、バイアスは特に問題となります。これらの分野では、エラーが深刻な結果をもたらす可能性があります。これらの問題は、アルゴリズムだけによって引き起こされることはほとんどありません。.
バイアスが純粋に技術的な問題ではない理由
バイアスを技術的に解決する方法は一つではありません。公平性と信頼性を向上させるには、以下のことが必要です。
- より多様で代表的なデータセット
- さまざまなシナリオにわたる慎重な評価
- モデルの使用方法と更新方法の継続的なレビュー
バイアスは究極的にはデータとプロセスの課題です。これに対処するには、より良いモデルだけでなく、意図的な選択が必要です。.

プライバシーと倫理的配慮
画像認識には、しばしば機密データが関係します。顔、場所、行動などが画像から推測される場合もありますが、対象者がそのことに完全に気づいていない場合もあります。.
責任ある使用は、技術的な正確さだけでは不十分です。明確なルールと意識的な制限が必要です。具体的には、以下のようなものがあります。
- 透明なデータ収集と使用ポリシー
- 個人データが関係する場合の明示的な同意
- 画像データの安全な保管とアクセス制御
- 国内および国際的なプライバシー規制の遵守
- システムによって行われた決定がどのように使用されるかについての明確な説明責任
倫理的配慮は後付けのものではありません。倫理的配慮は、社会の信頼、法的受容、そして画像認識システムが長期的に存続できるかどうかを左右します。.
画像認識が重要な理由
AI画像認識は課題を抱えながらも、あらゆる業界で不可欠なツールとなっています。人間による検査では時間がかかり、コストがかかり、一貫性が欠けていた箇所の自動化を可能にします。.
医療診断から農業、インフラ監視から小売まで、視覚データから洞察を引き出す能力は意思決定の方法を変えます。.
真の価値は人間の判断を置き換えることではなく、それを補強することにあります。AIは規模とスピードを担い、人間は文脈と責任を担います。.
結論:ピクセルから意思決定へ
AIによる画像認識は、人間の複雑な能力を扱いやすい段階に分解することで機能します。ピクセルは数字になり、数字はパターンになり、パターンは予測になります。機械が突然画像を理解するような魔法のような瞬間はありません。あるのは学習、反復、そして改良の繰り返しだけです。.
このプロセスの仕組みを理解することで、現実的な期待値を設定することが可能になります。また、チームがより優れたシステムを構築し、より適切な質問をし、より責任あるテクノロジー活用にも役立ちます。結局のところ、画像認識とは、機械が人間のように視覚化することではなく、機械が人間とは異なる視覚を持ち、その違いを利用して、重要な場面でより迅速かつ一貫性のある意思決定を行うことなのです。.
よくある質問
AI画像認識とは、コンピューターに画像内のパターンを識別させるプロセスです。人間が画像を理解するのとは異なり、システムは事例から学習し、数値と確率を用いて対象を判断します。.
いいえ。AIは画像を概念的に理解するわけではありません。ピクセル値を処理し、統計的な関係に基づいてパターンを学習します。結果は人間の知覚に似ているように見えるかもしれませんが、そのプロセスは全く異なります。.
現代の画像認識システムのほとんどは、特に畳み込みニューラルネットワーク(CNN)と呼ばれるディープラーニングを採用しています。これらのモデルは、エッジ、形状、テクスチャといった視覚的特徴を複数のレイヤーを通して学習するように設計されています。.
それはタスクによって異なります。単純な分類問題であれば数千枚の画像で済むかもしれませんが、複雑な検出やセグメンテーションのタスクでは、数万、数十万枚のラベル付きサンプルが必要になることがよくあります。データの質は量と同じくらい重要です。.
アノテーションは、モデルが各画像から何を学習すべきかを伝えます。ラベル付けが不十分だと、予測精度も低くなります。高品質なアノテーションは、画像認識システムの構築において最も時間のかかる部分であることが多いですが、精度と信頼性に直接影響を及ぼします。.