
OpenClawは、強力な言語モデルを実際に機能するパーソナルアシスタントに変えることができるオープンソースツールです。WhatsApp、Telegram、Discord、Slackなどのアプリでチャットしたり、メールの読み書き、送信、カレンダーの管理、ウェブブラウジング、ファイル操作、簡単なスクリプトの実行など、まるで眠らない頼れる同僚のように活躍します。.
最も重要なのは、どのAIモデルを接続するかです。OpenClaw自体は単なるメッセンジャーであり、実行者です。実際の思考、記憶、そして決定は、選択したモデル内で行われます。間違ったモデルを選択すると、システムが壊れたり、コストがかかりすぎたり、安全性が損なわれたりします。適切なモデルを選択すれば、スムーズで信頼できる動作が得られます。.
モデルの選択がすべてを変える理由
OpenClawにコマンドを送るたびに、これまでの会話履歴全体がモデルに送信されます。チャットが数日間続く場合は、数十万語に及ぶこともあります。モデルはそれをすべて理解し、以前の発言内容を記憶し、次に何をすべきかを判断し、どのボタンを押すか、どのメールを送信するかをOpenClawに知らせるための非常に正確な指示(ツールコールと呼ばれる)を書き込む必要があります。.
モデルが以前のメッセージの詳細を忘れ始めると(たとえ10回前でも)、すぐにミスを犯し、スレッドを破棄し始めます。ツール呼び出しのフォーマットやロジックが乱れると、アクションは完全に失敗するか、間違ったターゲット(間違ったメールを送信したり、間違ったカレンダーイベントを変更したり、間違ったファイルを操作したり)になってしまいます。また、モデルが受信メールや閲覧したWebページに隠された巧妙な言葉遣いに簡単に騙されてしまうと、悪意のあるプロンプトに誘導され、アシスタントが有害なコマンドを実行したり、機密情報を漏洩したりする可能性があります。.
つまり、モデルは単に「賢いか賢くないか」という問題ではありません。OpenClawでは、以下の3つの点において優れている必要があります。
- 混乱することなく長く記憶を保つ
- 指示に非常に正確に従う
- ツール(関数)を毎回正しく呼び出す
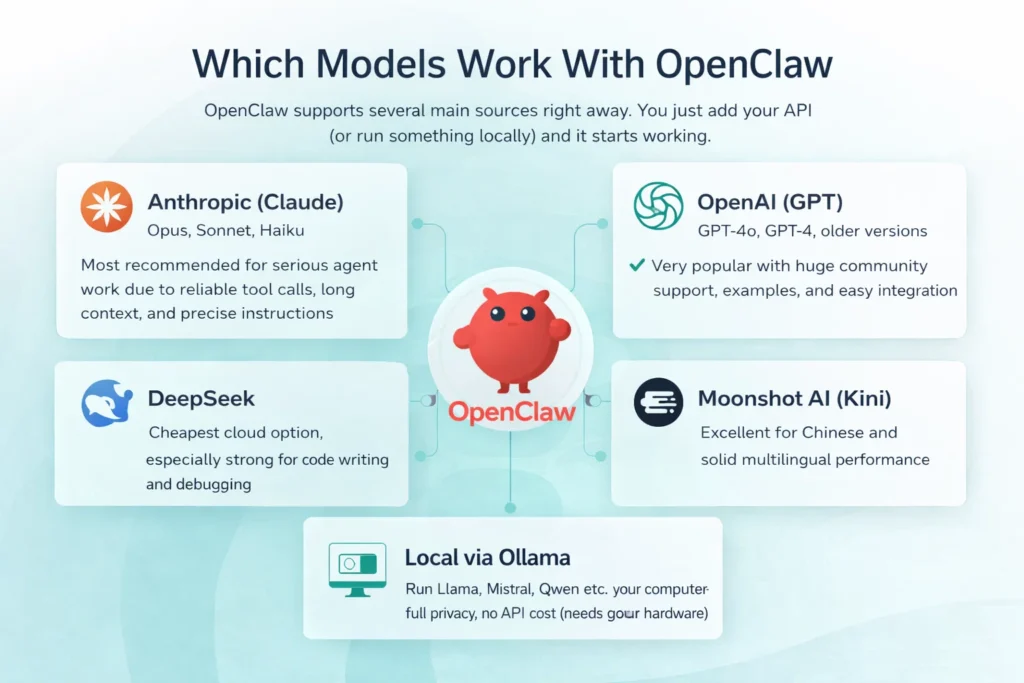
Openclawで動作するモデル
OpenClawは複数の主要ソースをすぐにサポートします。APIキーを追加するか、ローカルで何かを実行するだけで、すぐに動作を開始します。.
- 人類学的(クロード)Opus、Sonnet、Haiku – 信頼性の高いツール呼び出し、長いコンテキスト、正確な指示により、本格的なエージェント業務に最も推奨されます。.
- オープンAI(GPT): GPT-4o、GPT-4、古いバージョン – 大規模なコミュニティ サポート、例、簡単な統合により非常に人気があります。.
- ディープシーク: 最も安価なクラウド オプション。特にコードの作成とデバッグに優れています。.
- ムーンショットAI(キミ): 中国語に最適で、多言語パフォーマンスも安定しています。.
- オラマ経由のローカル: Llama、Mistral、Qwen などをコンピューターで実行します – 完全なプライバシー、API コストなし (優れたハードウェアが必要)。.
FlyPix AI + OpenClaw: 意思決定の時間を増やし、手作業を減らす
で フライピックスAI 当社は、衛星画像、ドローン画像、航空画像からの地理空間分析の自動化を専門としています。物体の検出、計数、面積測定、経時変化の追跡を行い、わかりやすいレポートや地図を提供します。これにより、建設現場のモニタリング、農業、環境アセスメント、インフラ点検、都市計画といった分野のお客様に貢献しています。.
当社のプラットフォームは、これまで手作業によるGISタスクに費やされていた時間を最大99.7%削減します。高価なソフトウェアや専門のアナリストはもう必要ありません。当社のノーコードインターフェースにより、あらゆるチームが特定のオブジェクト向けのカスタムモデルを構築できます。.
分析が完了した後でも、レポートの作成、画像ファイルと結果の整理、フォローアップレビューや現地訪問のスケジュール設定、新しいデータを含む電子メールの整理、関係者への最新情報の準備など、かなりの量の管理作業が残っていることがわかっています。.
だからこそ、私たちは OpenClaw を自然で強力な補完物だと考えています。.
お客様は、最高レベルのデータプライバシーを維持し、オフラインで動作する無料のローカルAIアシスタント(Ollamaなど)を利用できます。これは、機密性の高い画像を扱う際に非常に重要です。OpenClawは、分析結果からのレポート作成、プロジェクト別または日付別のファイル整理、カレンダー管理、関連規制や研究の調査、簡単なサマリーの送信など、すべてのフォローアップタスクを自動的に処理します。.
GPTモデル:柔軟で使い慣れた
OpenAI の GPT モデルは、特に OpenAI エコシステム内での作業に慣れている人々の間では、OpenClaw にとって引き続き非常に強力で広く使用されている選択肢となっています。.
これらのモデルは、単純な質問や簡単な質問にすばやく応答する必要がある場合、コードやスクリプトを頻繁に生成してリスト、表、JSON などの構造化されたクリーンな出力が必要な場合、または OpenAI API を取り巻く膨大な既存の例、ライブラリ、チュートリアル、コミュニティが構築したツールのコレクションを活用したい場合に特に優れたパフォーマンスを発揮します。.
最新のClaudeモデルと比較すると、GPTバリアントは、非常に長い会話中や、極めて厳密な複数ステップのツール呼び出しが必要な場合、一貫性が若干劣る場合があります。しかし、日常的なワークフローのほとんどにおいて、実質的な差は小さいままです。既にOpenAIのサブスクリプションをお持ちの方、無料クレジットをご利用の方、あるいは単にその速度と全体的な使いやすさを重視する方にとって、GPT-4o(または類似のバリアント)は最も簡単で実用的な出発点となる傾向があります。多くのOpenClawユーザーは、その使いやすさからGPTから始め、より厳密な推論やより強力な組み込みセキュリティガードレールを必要とするタスクに遭遇した際に、Claudeに移行します。.
クロード:最も一般的な真剣な選択
Anthropic の Claude モデルは、慎重かつ論理的で、長く詳細な指示に従うのが得意なため、本格的な OpenClaw ユーザーの間で最も人気のある選択肢です。.
- 最上位レベル(Opusレベル): 機密データ (財務、健康、法律、個人情報) や複数ステップの複雑なワークフローを扱う場合、またはセキュリティが重要な場合 (プロンプトインジェクションやトリックに対する非常に強力な耐性) に最適です。.
- 中級レベル(ソネットレベル): ほとんどの人が日常的に使用するもの: 優れた品質とコストのバランスと十分な速さで、電子メール、カレンダー、Web 検索、標準的な自動化を確実に処理します。.
- ライトティア(俳句レベル): 安価で非常に高速ですが、時々発生するエラーがそれほど問題にならない単純なワンステップ コマンドにのみ適しています。.
そのため、Claude はデフォルトまたは主な推奨事項になることが多くなります。これは、OpenClaw の信頼性、長いコンテキスト、安全なツールの使用のニーズに、ほとんどの代替手段よりもよく適合するためです。.
Deepseek: ほとんどお金をかけたくないとき
DeepSeekモデルは、コストを最優先するOpenClawユーザーに人気です。ClaudeやGPTに比べてコストはほんのわずかでありながら、基本的なタスクから中程度のタスクまで効果的に処理します。.
以下の用途に適しています:
- 簡単なメールの整理と返信
- 基本的なカレンダーの変更(イベントの追加、確認、移動)
- クイックコードヘルプ、小さなスクリプト、定期的なデバッグ
- 綿密な計画なしで簡単に自動化
毎日の使用が軽度から中程度(20~50 インタラクション)の場合、重要でない作業には使用可能でありながら、プレミアム モデルよりも 5~20 倍安価になることがよくあります。.
トレードオフは現実である:
- 長い会話が苦手(詳細を忘れやすい)
- 複雑な複数ステップのワークフローに苦労している
- 重要なタスク(財務、法務、顧客とのコミュニケーション)の精度が低い
- クロードよりも低い即発注射抵抗
最適なフィット: 予算が厳しく、タスクは主に単純/中程度で、難しいタスクについては信頼性が若干低くなります。.
多くのユーザーは、日常的な作業の 80~90% に DeepSeek を実行し、機密性の高い複雑なケースにのみ強力なモデルに切り替えます。これにより、重要な部分をカバーしながら料金を非常に低く抑えることができます。.

ローカルモデル(Ollama):ゼロコスト、最大限のプライバシー
データがマシンから一切漏れないようにしたいなら、Ollama経由のローカルモデルが唯一の現実的な方法です。オープンウェイトモデルをダウンロードし、お手持ちのハードウェアで実行すると、OpenClawはローカルサーバーを介して直接そのモデルと通信します。APIキー、クラウドプロバイダー、ログは一切不要です。.
より大きなモデル(Llama 3.1 70B、Qwen 2.5 72B、またはMistralの派生モデルなど、約70Bのパラメータを持つもの)は、メール処理、カレンダー管理、基本的なWeb検索、簡単なコードヘルプといったOpenClawの多くのタスクにおいて、ミドルクラスのクラウドモデルに驚くほど近いパフォーマンスを発揮します。強力なハードウェア(48GB以上のRAM、高性能GPU、またはApple Siliconの統合メモリ)を搭載したマシンであれば、日常的な実作業に十分対応できます。.
小型モデル(7B~13B、Llama 3.1 8B、Phi-3 Mini、Mistral 7Bなど)は、16~32GBのRAMを搭載した一般的なノートパソコンでも問題なく動作します。これらのモデルは高速で動作コストも低いですが、明らかに性能が劣ります。多段階の推論処理が難しく、コンテキストをすぐに忘れてしまい、複雑な処理ではミスが多くなります。.
実際に気づく欠点:
- 高品質を実現するにはハードウェア要件が重要であり、大規模なモデルには強力なGPUや大量のRAMが必要であり、それがなければすべてが劇的に遅くなる。
- 応答時間は通常、クラウド API よりも遅くなります (応答ごとに数秒長く、低性能のマシンではさらに長くなる場合があります)
- コンテキストの長さは限られています。ほとんどのローカルモデルは8K~32Kトークンで上限が設定されます(新しいモデルの中にはトリックによって上限が上がるものもあります)。一方、OpenClawセッションはそれをはるかに超えることが多く、エージェントは以前の詳細を失い始めます。
最適なフィットプライバシーを最優先にした設定、オフラインでの作業、請求書なしでのアイデアのテスト、またはクラウド サービスに信頼を置けない機密性の高い個人情報/財務情報/法的データを処理している場合などです。.
OpenClaw では各モデルの月額料金はいくらですか?
月額料金はモデルと利用状況によって異なります。OpenClawは毎回完全な会話履歴を送信するため、長時間のチャットや頻繁なタスクはトークンの使用量を増加させます。低頻度使用の場合は1日あたり10~15タスク、中頻度使用の場合は30~50タスク、高頻度使用の場合は100タスク以上(常時接続エージェント)となります。.
実際のユーザーパターンに基づくおおよその月額費用:
- 最高級クロード(オプスレベル): 軽度 $80–150、中等度 $200–400、重度 $500–750+
- 中級クロード(ソネットレベル): 軽度 $15–30、中等度 $40–80、重度 $100–200
- GPT-4o(OpenAI): 軽度 $12–25、中等度 $30–60、重度 $80–150
- DeepSeekまたはライトクロード(俳句レベル): 軽度から中等度 $5–15 以下、重度は通常 $30 未満
- Ollama経由のローカルモデル: $0 APIコスト(電気代とハードウェア代のみ)
実際の数値は、セッションの長さ、ツールの呼び出し回数、プロンプトの効率によって異なります。OpenClawダッシュボードまたはプロバイダーコンソールで1週間の使用状況を追跡し、実際の支出額をご確認ください。ワークロードに最適なプランを選択することで、最大限のコスト削減を実現できます。.
クイックガイド: OpenClaw のどのジョブにどのモデルを使うか
| 仕事 / ユースケース | 推奨モデル | このモデルが最も適している理由 |
| 日常のアシスタント(メール、カレンダー、メッセージ、クイックリサーチ) | 中級クロード(ソネットレベル)またはGPT-4o | 日常的なタスクに信頼性があり、速度とコストのバランスが良好で、コンテキストとツールを適切に処理します。 |
| 大量のコーディング、スクリプトの作成と修正、最初から動作する必要がある自動化 | 強力なクロード(オプスレベル)または強力なGPT | 優れた推論、正確なコード出力、複雑なロジックとデバッグにおけるミスの減少 |
| 長い文書の読み取り、大規模なレポートの要約、詳細な分析 | クロード(どのティアでも、できれば中位/上位)またはジェミニ(入手可能であれば) | 優れたロングコンテキスト処理と構造化された抽出/要約 |
| 超プライベートな作業 - デバイスからデータが一切出ない | Ollama 経由の大型ローカル モデル (例: Llama 70B、Qwen、Mistral) | すべての処理はハードウェア上で行われ、完全なプライバシーが確保され、API呼び出しは不要です。 |
| 予算が非常に限られているため、基本的な単純なタスクのみ | DeepSeekまたは小規模ローカルモデル | 非常に低コスト(または無料)ですが、ワンステップコマンドや軽い自動化には十分です。 |
| 中国語または英語以外の多言語作業が多い | Kimi(Moonshot AI)またはGPT-4o | 優れた多言語能力、特に中国語が流暢かつ正確 |
Openclawのモデルを比較する際に本当に重要なこと
OpenClaw のモデルを選択する際に実際に確認される主な事項は次のとおりです。
- 間違ったフォーマットやロジックエラーなしに、ツール呼び出しをどれだけ正確かつ確実に実行できるか
- 以前の詳細を忘れたり混同したりすることなく、長い会話履歴をどれだけうまく保存できるか
- 追加、省略、変更することなく、指示に厳密に従うかどうか
- 複雑なタスクを小さく、安全で、正しいステップに分割する効率
- 応答速度(チャットが遅れることなく自然に感じられるか)
- 通常の日常使用で月額いくらかかるか
まとめ
OpenClawには「最適な」単一のモデルはありません。何を最も頻繁に行うか、どれくらいの予算を使えるか、そしてプライバシーと速度のどちらを重視するかによって、最適なモデルは異なります。.
クロード モデル (特に中央のもの) は、継続的な修正なしで信頼性の高いエージェントの動作を求めるほとんどの人にとって、依然として最も安全な選択肢です。.
GPT モデルは、すでに OpenAI の世界に住んでいる場合や、迅速に創造的な回答が必要な場合に最適です。.
品質が完璧である必要がない場合、DeepSeek は多額の費用を節約します。.
ローカル モデルを使用すると、ハードウェアがあれば完全な制御が可能になり、継続的なコストはゼロになります。.
まずは設定が最も簡単なもの(通常はClaude SonnetかGPT-4o)から始め、1週間使ってみて何が気になるか確認してから、別のものを試してみましょう。OpenClawなら簡単に切り替えられるので、縛られることはありません。.
よくある質問
まずはClaude Sonnet(ミドルバージョン)から始めましょう。信頼性が高く、日常的なタスクのほとんどを問題なくこなせるだけでなく、多くのガイドも書かれています。.
はい。いつでもモデルを切り替えたり、設定でタスク/エージェントごとに異なるモデルを設定したりできます。.
単純なタスクやプライベートなタスクであれば、特に強力なハードウェアで大規模なタスクを実行する場合は、クラウドモデルの方が適しています。複雑で長時間の会話や高度なセキュリティが必要な場合は、クラウドモデルの方が適していることが多いです。.
指示に正確に従い、長いチャットを記憶し、ツールを正しく呼び出すのが非常に得意です。これにより、自動化の不具合やセキュリティリスクを軽減できます。.
はい、タスクが基本から中程度で、難しいタスクの信頼性が多少低くても構わないのであれば、それは可能です。まともな結果を得るための最も安価な方法の一つです。.
はい。騙されにくく、ルールを厳格に守るモデルは、特にランダムなメールやウェブサイトを読む際に、システム全体をより安全にします。.
毎日のメッセージ数を確認しましょう。使用量が少ない場合、ほとんどのモデルは安価です。使用量が多い場合、より安価なモデル(DeepSeek、Haiku、Local)が最も費用を節約できます。1週間後にダッシュボードでトークンの使用状況を確認してください。.