
画像認識は一見、難しそうに聞こえます。ニューラルネットワーク、データセット、学習ループ、GPUなど、コードを一行も書かないうちに、やることが山積みに思えるかもしれません。しかし実際には、画像認識AIを構築するには、すべてを一度に習得するよりも、段階的に適切な判断を下していくことが重要です。.
画像認識の本質は、システムに画像内のパターンを認識させ、見たものに基づいて一貫した判断を下せるように教えることです。これは、物体の識別、シーンの分類、欠陥の発見、異常のフラグ付けなど、様々な意味を持ちます。その基盤となる技術は強力ですが、プロセス自体は驚くほど現実的です。タスクを定義し、データを準備し、モデルを訓練し、誠実にテストを行い、実際に有用な場所に展開するというプロセスです。.
この記事では、そのプロセスを実践的かつ分かりやすく解説します。誇大広告や近道、そして研究論文を作成するという前提は一切ありません。画像認識AIが現在どのように構築されているか、各段階で何が重要か、そして人々がよく間違える点を明確に説明します。.

明確に説明できる問題から始める
データやモデルに触れる前に、明確に定義されたタスクが必要です。「画像を認識する」といったものではなく、具体的なタスクです。.
- 画像全体を 1 つのカテゴリに分類していますか?
- オブジェクトを見つけてその周りにボックスを描いていますか?
- ピクセルレベルで正確な形状や境界を識別していますか?
これらはそれぞれ異なる問題であり、コストとリスクも異なります。.
多くのプロジェクトは、漠然とした構想から始まり、複雑化が遅れて失敗に終わります。技術に詳しくない人に目標を一言で説明できないなら、まだ準備が整っていないと言えるでしょう。.
良い例
- “「写真から車体パネルの目に見える損傷を検出します。」”
- “「航空写真で積み重ねられた丸太の数を数えます。」”
- “「作物エリアに早期ストレスが発生しているかどうかを特定します。」”
悪い例
- “「AIを使って画像を分析する。」”
- “「スマートなコンピュータービジョンを構築する。」”
ここで明確にしておくと、数ヶ月後に役に立ちます。.
画像が数字になる仕組みを理解する
コンピュータは物体を認識しません。数値の配列を認識します。.
すべての画像はピクセルに変換され、各ピクセルは強度または色を表す値になります。カラー画像はモデルにとって単なる絵ではなく、複数のチャンネルにわたる数値のグリッドです。.
画像認識は、数字の中にあるパターンを学習することで機能します。エッジ、形状、テクスチャ、コントラストなどです。モデルが意味を理解しているからではなく、ラベルと相関する統計的な規則性を見つけるからです。.
これは、データ品質に対する考え方を変えるため重要です。モデルが失敗する場合は、多くの場合、モデルが捉える数値に矛盾、ノイズ、または誤解を招くような情報が含まれていることが原因です。.
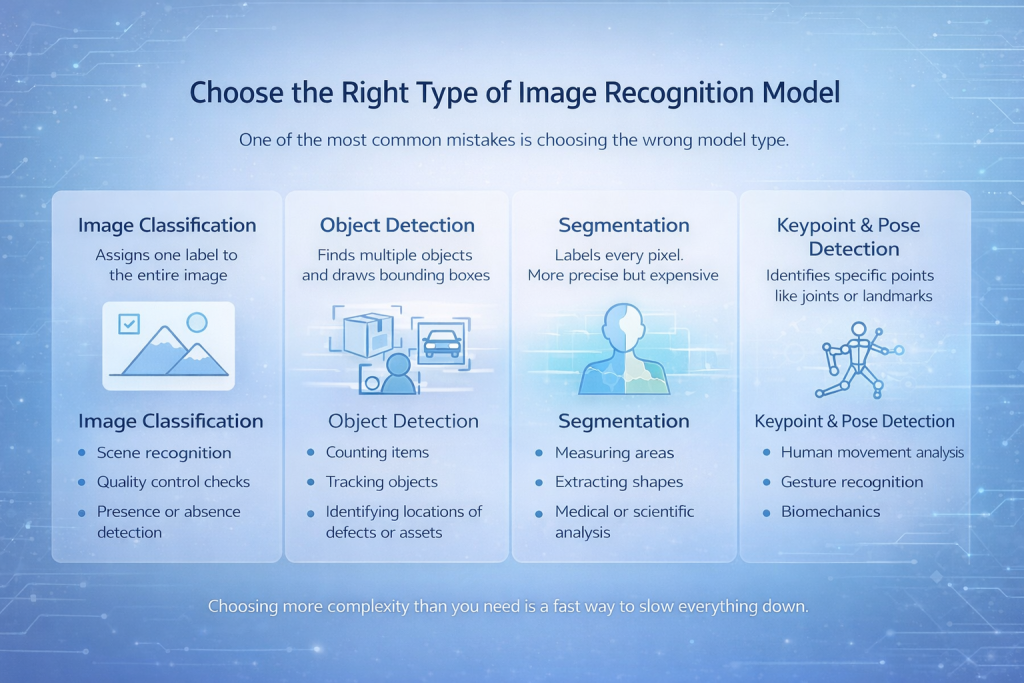
適切な画像認識モデルを選択する
最もよくある間違いの 1 つは、間違ったモデル タイプを選択することです。.
主要なカテゴリがいくつかあります。
画像分類
このモデルは画像全体に1つのラベルを割り当てます。対象オブジェクトが画像の大部分を占めている場合、シンプルで高速かつ効果的です。.
最適な用途:
- シーン認識
- 品質管理チェック
- 存在または不在の検出
物体検出
モデルは複数のオブジェクトを検出し、それらの周囲に境界ボックスを描画します。.
最適な用途:
- アイテムを数える
- 追跡オブジェクト
- 欠陥や資産の場所を特定する
セグメンテーション
すべてのピクセルにラベルが付けられます。これはより正確ですが、コストも高くなります。.
最適な用途:
- 面積の測定
- 図形の抽出
- 医学的または科学的分析
キーポイントとポーズ検出
モデルは、関節やランドマークなどの特定のポイントを識別します。.
最適な用途:
- 人間の動作分析
- ジェスチャー認識
- バイオメカニクス
必要以上に複雑なものを選択すると、すべてがすぐに遅くなります。.
データは重要ではない。プロジェクトそのものが重要だ
モデルは注目を集めます。実際の作業はデータが行います。.
強力な画像認識システムは、アーキテクチャよりもデータセットに大きく依存します。データが脆弱であったり一貫性がなかったりすると、どんなに高度なモデルでも機能しなくなります。.
実際に重要な主要原則:
データの多様性はデータ量を上回る
似たような画像が1万枚あると、2000枚の異なる画像よりも品質が劣ることがよくあります。角度、照明条件、背景、解像度、デバイスの種類の違いが、枚数そのものよりも重要です。.
ラベルは現実と一致しなければならない
人間がラベルについて議論すると、モデルは混乱を学習します。曖昧なクラスは早期に統合または再定義する必要があります。.
バランスが重要
あるクラスが優勢になると、精度は誤解を招く可能性があります。モデルは常に多数派クラスを推測することで「正確」になることがあります。.
注釈は品質の成否を左右する
ラベル付けはしばしば急いで行われ、後々それが露呈します。不適切なアノテーションは、学習中には発見しにくいものの、実際の使用時には痛々しいほど明白な問題を引き起こします。モデルは不安定になり、予測はランダムに感じられ、エッジケースが山積みになります。誤ったラベル付けがされた画像一つ一つが、学習プロセスを静かに蝕んでいきます。.
優れたアノテーションは、誰もが同じ方法で従う明確なラベル付けルールから始まります。人によってラベルの解釈が異なると、モデルはパターンではなく混乱を学習します。一貫性は正確性と同じくらい重要です。だからこそ、定期的なスポットチェックと小規模な監査が不可欠です。これらは、データセット全体に広がる前に、ドリフトを早期に発見するのに役立ちます。.
アノテーションにも進化の余地が必要です。新たなエッジケースが出現するたびに、もはや適合しない定義に無理やりラベルを当てはめるのではなく、ラベルを洗練させる必要があります。このような反復的なクリーンアップは時間がかかりますが、モデルの安定性という点では大きな効果があります。.
AI支援によるラベリングツールは、特に大規模なデータセットでは処理速度を向上できますが、人間の判断を代替するものではありません。与えられたロジックをそのまま繰り返すだけです。ルールが不明確であったり欠陥があったりすると、自動化によって間違いが修正されるのではなく、拡大されてしまいます。.
前処理は見た目だけの問題ではない
前処理は、単に画像をきれいに見せるだけではありません。不要なばらつきを減らし、重要な部分を強調することです。.
実際に役立つ一般的な手順:
- 画像を一貫した解像度にサイズ変更する
- ピクセル値の正規化
- 向きを修正する
- 無関係な領域を切り取る
データ拡張には特別な注意が必要です。回転、反転、明るさの変化、ノイズの注入といった単純な変換は、汎化率を劇的に向上させる可能性があります。目標はモデルを騙すことではなく、現実に適応させることです。.
データが完璧すぎると、モデルは現実世界でパニックに陥ります。.
モデルアーキテクチャはあなたが思っているほど重要ではない
最新のモデルや話題のモデルを追いかけたくなる誘惑に駆られます。トランスフォーマー、大規模なバックボーン、複雑なパイプラインは、一見魅力的に見えますが、必ずしも優れた結果が得られるとは限りません。.
実際には、多くの信頼性の高い画像認識システムは、確立されたアーキテクチャ上に構築されています。畳み込みニューラルネットワークが依然としてこの分野で優位に立っているのには理由があります。畳み込みニューラルネットワークは安定性と効率性に優れ、問題が発生した際にも理解しやすいからです。この信頼性は、ベンチマークテストで数パーセントのスコアを上げることよりも、多くの場合重要です。.
転移学習は通常、最も賢明な出発点です。大規模で多様なデータセットから既に学習済みのモデルを使用することで、特に自身のデータが限られている場合には、強固な基盤を築くことができます。微調整は、新しいタスクがモデルが過去に経験したものに適度に近い場合、過学習が積極的に抑制されている場合、そして再学習が積極的ではなく慎重に行われる場合に最も効果的です。小規模で意図的な調整は、力ずくの再学習よりも優れた結果をもたらす傾向があります。.
モデルが大きくなればなるほど、必ずしも優れたモデルになるとは限りません。学習コストが高くなり、デバッグが難しくなり、追跡が困難な微妙な不具合が発生することも少なくありません。.
トレーニングはデータとの反復的な対話です
トレーニングはワンクリック操作ではありません。ループです。.
トレーニング、結果の観察、障害パターンの特定、データまたはパラメータの調整、そしてこれを繰り返します。.
主なトレーニング方法:
- トレーニング、検証、テストのセットを別々に使用します
- 正確さだけでなく損失曲線も監視する
- 改善が停滞したらトレーニングを中止する
- 学習率とバッチサイズを慎重に調整する
本格的な作業においては、GPUアクセラレーションは必須です。CPUでのトレーニングは学習には適していますが、実際のプロジェクトでは現実的ではありません。GPUは反復処理時間を短縮し、実験を可能にすることでモデルの品質を直接的に向上させます。.
評価は正確さを超える必要がある
精度は計算が最も容易な指標の一つであると同時に、最も誤解されやすい指標の一つでもあります。モデルは非常に高精度に見えても、現実世界では役に立たない場合があります。.
優れた評価はより深く掘り下げます。混同行列は、モデルが常に誤った判断を下す箇所を明らかにするのに役立ちます。クラスのバランスが崩れている場合や、特定の誤りが他の誤りよりも大きなコストを伴っている場合、適合率と再現率ははるかに有益な情報となります。全く新しい実世界の画像でテストを行うと、クリーンな検証データでは決して現れない問題が明らかになることがよくあります。.
最も価値のある評価ステップは、依然として手動によるレビューです。予測の失敗を直接観察し、その理由を問うことで、いかなる指標も完全に捉えきれない洞察が得られます。モデルは、要約された数値を信じるのではなく、時間をかけて誤りを検証すれば、その弱点について驚くほど正直に答えてくれます。.
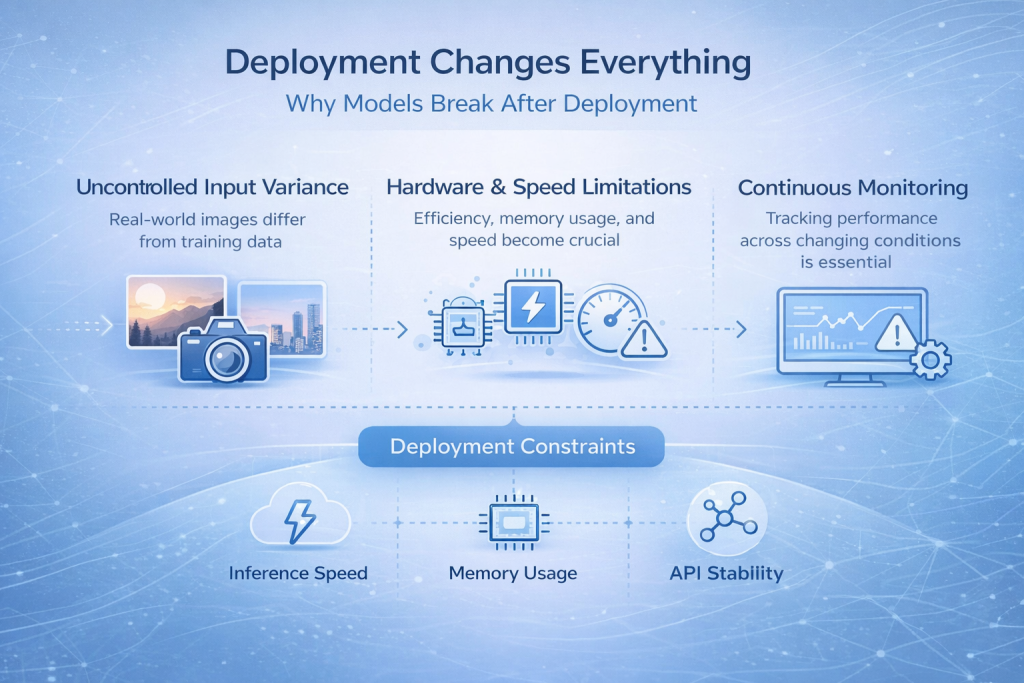
展開はすべてを変える
モデルがデプロイメント後に壊れる理由
多くの画像認識モデルは開発段階では良好なパフォーマンスを発揮しますが、デプロイされると突然機能しなくなります。これは、開発プロセス全体の中で最も一般的で、かつ最も苛立たしい瞬間の一つです。.
理由は簡単です。現実世界の入力データは、学習データとほとんど同じではありません。画像は異なるカメラから取得され、照明条件は一日を通して変化し、圧縮アーティファクトが発生し、ユーザーは理想的な使用パターンを踏んでいません。画像の撮影方法がわずかに異なるだけでも、モデルは学習した動作範囲から外れてしまう可能性があります。.
制御された環境では安定しているように見えたものが、突然信頼できなくなります。.
無視できない制約
デプロイメントでは、モデルの精度を超えた思考が求められます。リアルタイムの予測が必要な場合は、推論速度が重要になります。モデルをエッジデバイスやモバイルハードウェアで実行する場合は、メモリ使用量が重要になります。ハードウェアの制約によって、どのようなアーキテクチャが実現可能かが決まります。また、他のシステムが予測に依存するようになると、APIの安定性が不可欠になります。.
監視は、あれば良いというレベルから、必要不可欠なレベルへと変化しています。リリース後のモデルの動作を可視化できなければ、信頼を失うまで障害に気付かれない可能性があります。.
モデルを使えるようにする
TensorFlow LiteやONNXなどのフォーマットへのモデルのエクスポートは、パイプラインの最終段階における単なる技術的なステップではありません。これは、トレーニング済みのモデルを実際に本番環境で使用できるものにするためのプロセスの一部です。これらのフォーマットは、モデルをさまざまな環境に適応させ、オーバーヘッドを削減し、デプロイメントターゲットとの互換性を向上させるのに役立ちます。.
ノートパソコンでは問題なく動作しても、実際に導入に耐えられないモデルは、まだ完成ではありません。真の成功は、システムが想定された用途で安定して動作して初めて実現します。.
現実世界における画像認識:FlyPix AI での画像認識の構築方法
で フライピックスAI, 私たちは画像認識を実験室での演習として捉えていません。衛星画像、航空画像、ドローン画像を日々扱っていますが、そこには密集した風景や重なり合う物体、そして決して完璧な状況などありません。こうした現実が、AIの構築と活用方法を形作っています。.
私たちの目標は常にシンプルです。それは、手作業による視覚分析のボトルネックを取り除くことです。チームは画像に注釈を付け、結果を確認し、状況が変わるたびに再度確認することに何百時間も費やしていました。FlyPixは、精度を犠牲にすることなく、大規模な物体の検出、監視、検査を行うことができるAIエージェントを用いて、この作業を自動化するために開発されました。.
私たちにとって最も重要なのは実用性です。ユースケースに適したモデルをトレーニングするために、深いAI知識や機械学習エンジニアのチームは必要ありません。FlyPixを使えば、チームは独自のアノテーションを使用して、それぞれの業界で実際に重要なオブジェクトに焦点を当てたカスタム画像認識モデルを作成できます。建設現場、港湾、農地、インフラ資産、森林地帯など、画像は異なりますが、課題は同じです。.
私たちは、あらゆるものを実装を念頭に置いて設計しています。現実世界の地理空間データは常に変化するため、モデルは初日から変化に対応できなければなりません。つまり、クリーンなデモ環境以外でも確実に動作し、大量の画像を迅速に処理し、チームが即座に対応できる結果を提供するシステムを構築するということです。私たちにとって、画像認識はテスト時だけでなく、日常の運用でも問題なく動作して初めて成功につながります。.
フィードバックループがモデルを維持する
画像認識AIは静的ではありません。データは変化し、環境は変化し、期待も変化します。.
長持ちするシステムはフィードバックを考慮して設計されています。
- 展開後に新しい画像を収集する
- トラック故障事例
- 定期的に再訓練する
- 現実が変化したらラベルを調整する
導入後の学習を無視することは、システムへの信頼を最も早く失う方法の 1 つです。.
結論
実際に機能する画像認識AIを構築するには、最新モデルを追いかけるのではなく、基礎を正しく理解することが重要です。明確な問題定義、規律あるデータ処理、思慮深い評価、そして現実的な導入計画は、単一のアルゴリズムの選択よりもはるかに重要です。.
最も信頼性の高いシステムは、最も複雑なシステムではありません。現実世界で画像がどのように変化し、モデルがその変化にどのように反応するかを真摯に理解した上で構築されたシステムです。現実を反映したデータで学習され、弱点を明らかにする指標で評価され、導入初日から制約条件を考慮して導入されます。.
一つだけ覚えておいてほしいのは、画像認識はエンジニアリングプロセスであり、一度きりの実験ではないということです。このように扱い、慎重に反復し、実際の使用状況に根ざした開発を行えば、デモが終わってからも結果は長く続く傾向があります。.
よくある質問
画像認識AIは、画像内のパターン、物体、または特徴を識別することを学習するコンピュータービジョンシステムの一種です。ピクセルデータを分析し、学習済みモデルを用いて視覚パターンをラベルまたは結果に関連付けることで機能します。.
必ずしもそうではありません。大規模なデータセットは役立ちますが、量よりも多様性と品質が重要です。転移学習と適切な拡張により、比較的小規模ながらも適切にキュレーションされたデータセットで有用なモデルを学習できます。.
ほとんどのプロジェクトでは、実績のある畳み込みニューラルネットワークから始めて転移学習を適用するのが安全かつ効果的なアプローチです。より複雑なモデルは、明確な理由と十分なデータがある場合にのみ使用すべきです。.
精度だけでは不十分です。混同行列、適合率、再現率を確認し、学習に使用したことのない実世界の画像でモデルをテストする必要があります。失敗例を手動で確認することが、多くの場合、最も多くの発見につながるステップです。.
これは通常、本番環境の画像とトレーニングデータが異なるために発生します。照明、カメラの画質、画像圧縮、ユーザーの行動など、さまざまな変化がパフォーマンスに影響を与える可能性があります。このギャップはよくあるため、開発段階で計画する必要があります。.
はい。デプロイメントは最後まで無視できる最終ステップではありません。ハードウェアの制限、推論速度、メモリ使用量、統合要件などはすべて、モデルの構築とトレーニング方法に影響を与えます。.