
AI-beeldherkenning klinkt complex, maar in de kern gaat het erom machines te leren patronen te herkennen zoals mensen dat doen – alleen sneller en op een veel grotere schaal. Elke foto, satellietfoto of videobeeld is slechts data totdat een AI-systeem leert hoe het die moet interpreteren. Dat leerproces zet ruwe pixels om in betekenisvolle signalen: objecten, vormen, tekst of veranderingen in de tijd.
Dit artikel legt uit hoe AI-beeldherkenning achter de schermen werkt. Niet in abstracte theorie, maar in praktische termen: hoe afbeeldingen getallen worden, hoe modellen leren van voorbeelden en waarom datakwaliteit belangrijker is dan flitsende algoritmes. Als je je ooit hebt afgevraagd wat er precies gebeurt tussen het uploaden van een afbeelding en het ontvangen van een geautomatiseerd resultaat, dan begint het hier.
Wat beeldherkenning werkelijk betekent in AI
Beeldherkenning is het vermogen van een machine om patronen, objecten, tekst of kenmerken in een afbeelding te herkennen en er betekenis aan toe te kennen. Die betekenis kan eenvoudig zijn, zoals het herkennen van een auto, of complex, zoals het detecteren van vroege tekenen van gewasstress op luchtfoto's.
In tegenstelling tot traditionele software volgen AI-systemen geen vastgelegde regels zoals "als het vier wielen heeft, is het een auto". In plaats daarvan leren ze van voorbeelden. Duizenden of miljoenen gelabelde afbeeldingen worden gebruikt om het systeem te leren hoe iets eruitziet onder verschillende omstandigheden, hoeken, belichting en omgevingen.
In essentie is beeldherkenning een vorm van patroonherkenning die wordt aangestuurd door machinaal leren en, meer specifiek, door deep learning. Het systeem begrijpt geen concepten. Het leert statistische verbanden tussen visuele kenmerken en uitkomsten.
Hoe we bij FlyPix AI-beeldherkenning omzetten in concrete resultaten in de praktijk.
Bij VliegPix, We gebruiken AI-beeldherkenning als een praktisch hulpmiddel voor het werken met satelliet-, lucht- en dronebeelden op grote schaal. Ons doel is om teams te helpen van ruwe beelden naar heldere inzichten te komen, zonder wekenlang handmatig werk of complexe configuratie.
We maken gebruik van AI-agenten die objecten kunnen detecteren, monitoren en inspecteren in grote en complexe datasets. Gebruikers trainen aangepaste AI-modellen met hun eigen afbeeldingen en annotaties, zonder dat programmeerkennis vereist is. U bepaalt wat belangrijk is in uw data, en het systeem leert dit consistent te herkennen.
Snelheid is een belangrijk onderdeel van de waarde. Wat voorheen uren handmatige annotatie vergde, kan nu in seconden worden gedaan. Van landgebruikclassificatie en infrastructuurinspectie tot landbouw en milieumonitoring: de focus ligt altijd op snellere en betrouwbaardere beslissingen.
FlyPix is ontworpen om zich aan te passen aan verschillende sectoren en toepassingen, en niet om ze in één workflow te persen. Door AI-beeldherkenning flexibel en toegankelijk te houden, maken we het voor teams gemakkelijker om het in de dagelijkse praktijk toe te passen, en niet alleen in experimentele projecten.
Alles begint met pixels.
Elke digitale afbeelding is een raster van pixels. Elke pixel bevat numerieke waarden die kleur en helderheid beschrijven. In de meeste afbeeldingen betekent dit drie waarden per pixel voor rood, groen en blauw.
Voor een mens is een foto van een straat direct herkenbaar. Voor een AI-model is diezelfde afbeelding echter een grote matrix van getallen. Er is geen ingebouwd begrip van wegen, gebouwen of mensen. De uitdaging van beeldherkenning is om een systeem te leren hoe het deze getallen op een zinvolle manier kan interpreteren.
Voordat er überhaupt een leerproces plaatsvindt, wordt de afbeelding omgezet in een numeriek formaat dat het model kan verwerken. Resolutie, kleurdiepte en bestandsstructuur beïnvloeden hoeveel informatie beschikbaar is en hoe zwaar de berekening wordt.
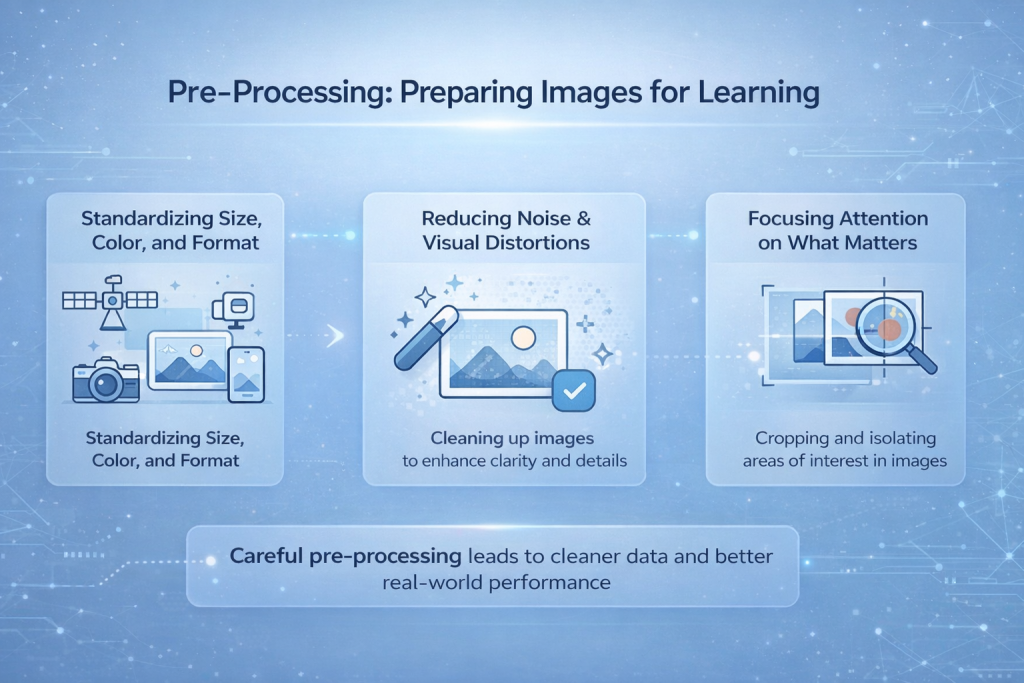
Voorbewerking: Afbeeldingen voorbereiden voor gebruik
Beelden die zijn vastgelegd door camera's, drones, satellieten of telefoons zijn vrijwel nooit consistent. Ze variëren in resolutie, lichtomstandigheden, hoek en bestandsformaat. Sommige zijn scherp, andere ruisig of wazig. Het direct invoeren van deze ruwe mix in een model maakt het leerproces instabiel en onvoorspelbaar. Voorbewerking is de stap waarin deze visuele chaos onder controle wordt gebracht.
Standaardisatie van formaat, kleur en indeling
Een van de eerste taken is het uniform maken van afbeeldingen. Modellen verwachten een consistente vorm als invoer, dus worden afbeeldingen aangepast aan een vaste resolutie. Kleurwaarden worden genormaliseerd, zodat verschillen in helderheid en contrast het leerproces niet verstoren. Dit helpt het model zich te concentreren op de structuur in plaats van afgeleid te worden door veranderingen in belichting of camera-instellingen.
Het verminderen van ruis en visuele vervormingen
Sensorruis, bewegingsonscherpte, compressieartefacten of weersomstandigheden kunnen belangrijke details verbergen. Voorbewerkingstechnieken helpen deze effecten te verminderen, waardoor randen en vormen gemakkelijker door het model kunnen worden gedetecteerd. Deze stap verbetert de afbeelding niet in menselijke zin, maar wel de leesbaarheid van de gegevens voor het netwerk.
De aandacht richten op wat belangrijk is.
In veel gevallen is slechts een deel van een afbeelding relevant. Door de afbeelding bij te snijden, te maskeren of gebieden van belang te isoleren, kunnen storende elementen worden verwijderd. Door te beperken wat het model ziet, verloopt het leerproces sneller en nauwkeuriger, met name bij taken zoals objectdetectie of medische beeldvorming.
Waarom voorbewerking de prestaties in de praktijk direct beïnvloedt
Voorbewerking maakt een model op zichzelf niet slimmer. Wat het wel doet, is schonere omstandigheden creëren voor het leerproces. Wanneer deze stap gehaast of slecht ontworpen is, kunnen modellen goed presteren in gecontroleerde tests, maar falen in de praktijk. Zorgvuldige voorbewerking is vaak het verschil tussen een systeem dat in theorie werkt en een systeem dat in de praktijk werkt.
Kenmerkleren: Hoe AI patronen vindt
Mensen leren objecten herkennen door op kenmerken te letten. Randen, vormen, texturen en verhoudingen spelen allemaal een rol. AI-modellen leren op een vergelijkbare, maar meer wiskundige manier.
De meeste moderne beeldherkenningssystemen maken gebruik van convolutionele neurale netwerken, ofwel CNN's. Deze netwerken zijn ontworpen om afbeeldingen te scannen met behulp van kleine filters die over de afbeelding bewegen en lokale patronen detecteren.
De eerste lagen in een CNN detecteren doorgaans zeer eenvoudige kenmerken zoals randen, hoeken en kleurgadiënten. Middelste lagen combineren deze tot vormen en texturen. Diepere lagen assembleren deze vormen tot patronen van een hoger niveau die overeenkomen met objecten of gebieden van belang.
Het kernidee is hiërarchie. Het model springt niet direct van pixels naar "dit is een boom". Het bouwt dat begrip laag per laag op.
Waarom convolutie belangrijk is
Convolutie maakt het mogelijk om dezelfde patroondetector op de gehele afbeelding toe te passen. Een verticale rand blijft een verticale rand, ongeacht of deze zich aan de linker- of rechterkant van de afbeelding bevindt.
Deze aanpak maakt modellen efficiënter en robuuster. In plaats van exacte pixelpatronen te onthouden, leert het systeem herbruikbare visuele patronen. Dit is een van de redenen waarom CNN's zo goed werken bij verschillende beeldformaten en -indelingen.
Poolinglagen worden vaak toegevoegd om de omvang van de data te verkleinen, terwijl belangrijke informatie behouden blijft. Dit helpt de rekenkosten te beheersen en voorkomt dat het model te gevoelig wordt voor kleine variaties.
Het model trainen: leren van voorbeelden
Training is het proces waarin beeldherkenning daadwerkelijk plaatsvindt. Het model krijgt een grote set gelabelde afbeeldingen te zien. Elke afbeelding is gekoppeld aan het juiste antwoord, zoals 'gezonde oogst', 'beschadigde weg' of 'persoon aanwezig'.“
Tijdens de training doorloopt het proces een herhalende cyclus:
- Het model analyseert een invoerbeeld en genereert een voorspelling.
- De voorspelling wordt vergeleken met het juiste label.
- Het verschil tussen de twee wordt gemeten als een fout.
- Het model past zijn interne parameters aan om die fout te verminderen.
- Hetzelfde proces wordt herhaald voor duizenden of miljoenen voorbeelden.
Deze geleidelijke aanpassing zorgt ervoor dat het systeem in de loop der tijd verbetert.
Backpropagatie is het mechanisme dat dit leerproces mogelijk maakt. Het spoort fouten terug in het netwerk en werkt de gewichten van elke laag bij, zodat toekomstige voorspellingen nauwkeuriger worden.
De kwaliteit van de training hangt sterk af van de gebruikte data. Als de dataset te klein is, slecht gelabeld is of eenzijdig gericht is op bepaalde omstandigheden, zal het model die zwakheden overnemen. Geen enkele vorm van optimalisatie kan de gevolgen van trainingsdata van lage kwaliteit of een onevenwichtige verdeling volledig compenseren.
De rol van gelabelde data
Gelabelde data vormen de basis van supervised beeldherkenning. Elk label vertelt het model wat het van een afbeelding moet leren.
Het aanmaken van deze labels is vaak het duurste en meest tijdrovende onderdeel van het proces. Menselijke annotatoren moeten objecten zorgvuldig markeren, kaders tekenen, regio's segmenteren of afbeeldingen classificeren.
Hoogwaardige annotatie leidt tot betere modellen. Slechte annotatie leidt tot verwarring en onbetrouwbare resultaten. Daarom zijn veel mislukkingen bij beeldherkenning terug te voeren op de dataset in plaats van op het algoritme.
Transferleren en inferentie: van een voorgegetraind model naar echte voorspellingen
Het trainen van een diep neuraal netwerk vanaf nul vereist veel gelabelde data en aanzienlijke rekenkracht. Daarom beginnen veel teams niet helemaal vanaf nul, maar maken ze gebruik van transfer learning.
Hoe Transfer Learning werkt
Transfer learning begint met een model dat al algemene visuele kenmerken heeft geleerd uit een grote dataset. Dat voorgegetrainde model begrijpt al gangbare patronen zoals randen, texturen en vormen. Vervolgens wordt het verfijnd voor een specifieke taak met behulp van een kleinere, taakgerichte dataset.
In de praktijk blijven de eerste lagen meestal grotendeels hetzelfde, terwijl latere lagen opnieuw worden getraind om aan de nieuwe taak te voldoen. Een model dat bijvoorbeeld is getraind op algemene afbeeldingen, kan worden aangepast om defecten in industriële componenten of patronen in medische scans te herkennen. Deze aanpak versnelt de ontwikkeling en verbetert vaak de nauwkeurigheid, vooral wanneer de dataset beperkt is.
Van training naar inferentie
Zodra het model getraind of verfijnd is, gaat het over naar de inferentiemodus. In deze fase verwerkt het nieuwe, onbekende afbeeldingen en genereert het voorspellingen.
De inferentiepipeline is een afspiegeling van de trainingspipeline:
- De afbeeldingen zijn vooraf bewerkt.
- Ze worden via het netwerk doorgegeven.
- De uitvoer wordt weergegeven als labels, waarschijnlijkheden, gedetecteerde objecten of gesegmenteerde regio's.
Op dit punt verschuift de prioriteit. Het doel is niet langer leren, maar consistente prestaties. In echte systemen moet inferentie vaak in realtime of bijna realtime plaatsvinden, dus snelheid en betrouwbaarheid zijn net zo belangrijk als pure nauwkeurigheid.
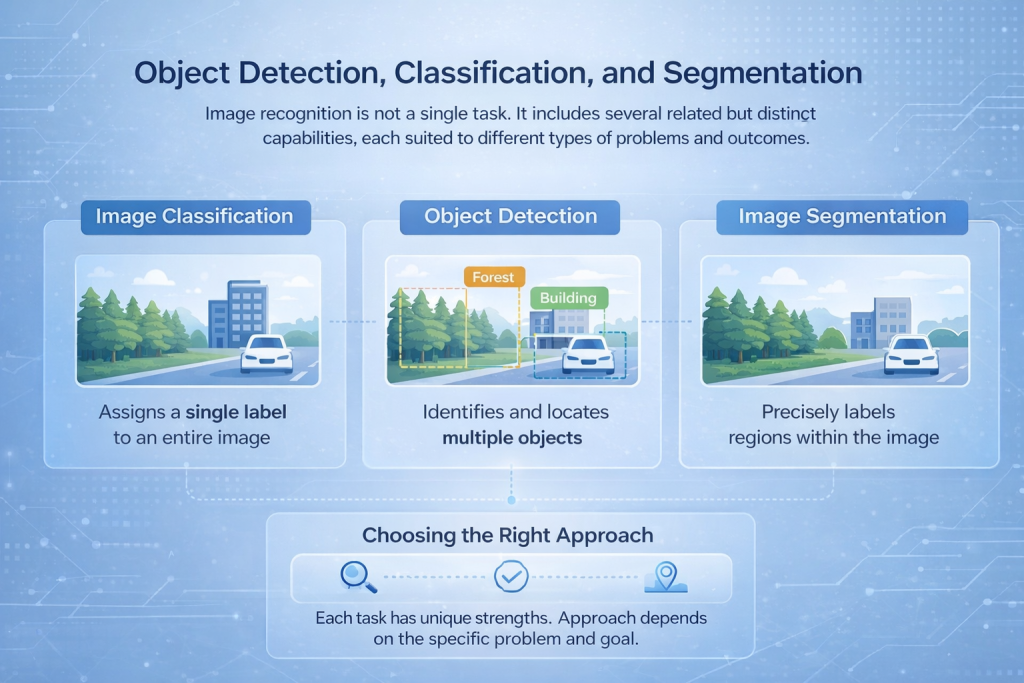
Objectdetectie, -classificatie en -segmentatie
Beeldherkenning is geen op zichzelf staande taak. Het omvat verschillende verwante, maar onderscheidende mogelijkheden, elk geschikt voor verschillende soorten problemen en resultaten.
Beeldclassificatie
Bij beeldclassificatie wordt aan een complete afbeelding één label toegekend. Het model bekijkt de volledige scène en bepaalt wat deze het beste beschrijft, bijvoorbeeld of een afbeelding een bos, een gebouw of een voertuig bevat. Deze aanpak werkt goed wanneer de algehele inhoud belangrijker is dan de precieze locatie.
Objectdetectie
Objectdetectie gaat een stap verder door meerdere objecten binnen dezelfde afbeelding te identificeren en te lokaliseren. In plaats van één enkel label tekent het model begrenzingskaders rond de objecten van belang en classificeert elk object afzonderlijk. Dit wordt vaak gebruikt in toepassingen zoals verkeersmonitoring, beveiligingssystemen en industriële inspectie.
Beeldsegmentatie
Segmentatie biedt het meest gedetailleerde analyseniveau. Het labelt individuele pixels of gebieden binnen een afbeelding, waardoor het systeem objecten met hoge precisie kan scheiden. Dit is essentieel in toepassingen zoals medische beeldvorming, landgebruikskartering of oppervlakteanalyse, waar exacte grenzen van belang zijn.
De juiste aanpak kiezen
Elk van deze taken vereist een andere netwerkarchitectuur en trainingsstrategie. De juiste keuze hangt af van het probleem dat moet worden opgelost, of het nu gaat om het tellen van voertuigen, het lezen van tekst of het in kaart brengen van landgebruik op een gedetailleerd niveau.
Prestaties meten
Modellen voor beeldherkenning worden geëvalueerd aan de hand van metrieken zoals nauwkeurigheid, precisie, recall en intersection over union.
Alleen nauwkeurigheid is vaak misleidend. Een model dat een object zelden detecteert, kan nauwkeurig lijken simpelweg omdat het object zeldzaam is. Precisie en recall geven een duidelijker beeld van hoe betrouwbaar het model is.
Testen moet altijd gebeuren met data die het model nog nooit eerder heeft gezien. Dit helpt om te achterhalen of het systeem algemene patronen heeft geleerd of de trainingsset alleen maar heeft onthouden.
Complexiteit, vooroordelen en praktische beperkingen in de echte wereld
AI-beeldherkenning werkt het best in gecontroleerde omgevingen, maar de werkelijkheid is zelden gecontroleerd. Zodra modellen het laboratorium verlaten en met de realiteit te maken krijgen, worden de beperkingen veel duidelijker.
Waarom het moeilijk is om omstandigheden uit de echte wereld te modelleren
De lichtomstandigheden veranderen gedurende de dag. Objecten overlappen elkaar of verdwijnen gedeeltelijk uit beeld. Het weer beïnvloedt het zicht. Camera's bewegen, vallen uit of leggen onvolledige gegevens vast. Dit alles introduceert ruis waarmee modellen moeten leren omgaan.
Een systeem dat goed presteert tijdens het testen, kan problemen ondervinden zodra deze variabelen zich opstapelen. Daarom zijn continu testen, monitoren en bijscholen essentiële onderdelen van elk productiesysteem, en geen optionele verbeteringen.
De rol van menselijk toezicht
AI-beeldherkenning is krachtig, maar niet onfeilbaar. In veiligheidskritische of zeer belangrijke toepassingen blijft menselijke controle noodzakelijk. Mensen bieden context, oordeel en verantwoording in situaties waar geautomatiseerde beslissingen alleen niet volstaan.
Hoe vooringenomenheid beeldherkenningssystemen binnendringt
Modellen leren rechtstreeks van de data waarop ze getraind worden, inclusief de hiaten en onevenwichtigheden daarin. Als bepaalde omgevingen, populaties of omstandigheden ondervertegenwoordigd zijn, zal de prestatie in die gevallen daaronder lijden.
Vooroordelen worden vooral problematisch op gebieden zoals bewaking, toegangscontrole of openbare veiligheid, waar fouten reële gevolgen kunnen hebben. Deze problemen worden zelden uitsluitend door algoritmes veroorzaakt.
Waarom vooringenomenheid geen puur technisch probleem is
Er bestaat geen eenduidige technische oplossing voor vooringenomenheid. Het verbeteren van eerlijkheid en betrouwbaarheid vereist het volgende:
- Meer diverse en representatieve datasets
- Zorgvuldige evaluatie van verschillende scenario's
- Continue evaluatie van hoe modellen worden gebruikt en bijgewerkt.
Vooroordelen zijn uiteindelijk een kwestie van data en processen. Om ze aan te pakken zijn weloverwogen keuzes nodig, niet alleen betere modellen.

Privacy en ethische overwegingen
Beeldherkenning omvat vaak gevoelige gegevens. Gezichten, locaties en gedrag kunnen uit beelden worden afgeleid, soms zonder dat de persoon in kwestie zich daar volledig van bewust is.
Verantwoord gebruik hangt van meer af dan alleen technische nauwkeurigheid. Het vereist duidelijke regels en bewuste grenzen, waaronder:
- Transparant beleid inzake gegevensverzameling en -gebruik
- Uitdrukkelijke toestemming wanneer persoonsgegevens betrokken zijn
- Veilige opslag en gecontroleerde toegang tot beeldgegevens.
- Naleving van lokale en internationale privacyregelgeving.
- Duidelijke verantwoording over hoe beslissingen die door het systeem worden genomen, worden gebruikt.
Ethische overwegingen zijn geen bijzaak. Ze bepalen het publieke vertrouwen, de wettelijke acceptatie en of beeldherkenningssystemen op de lange termijn levensvatbaar blijven.
Waarom beeldherkenning belangrijk is
Ondanks de uitdagingen is AI-beeldherkenning een essentieel hulpmiddel geworden in diverse sectoren. Het maakt automatisering mogelijk waar menselijke inspectie traag, duur of inconsistent zou zijn.
Van diagnostiek in de gezondheidszorg tot landbouw, van infrastructuurbewaking tot detailhandel: de mogelijkheid om inzichten uit visuele data te halen, verandert de manier waarop beslissingen worden genomen.
De werkelijke waarde schuilt niet in het vervangen van menselijk oordeel, maar in het aanvullen ervan. AI zorgt voor schaal en snelheid. Mensen zorgen voor context en verantwoordelijkheid.
Conclusie: Van pixels naar beslissingen
AI-beeldherkenning werkt omdat het een complexe menselijke vaardigheid opdeelt in beheersbare stappen. Pixels worden getallen. Getallen worden patronen. Patronen worden voorspellingen. Er is geen magisch moment waarop een machine een afbeelding ineens begrijpt. Er is alleen leren, herhaling en verfijning.
Inzicht in hoe dit proces werkt, helpt bij het stellen van realistische verwachtingen. Het helpt teams ook om betere systemen te bouwen, betere vragen te stellen en de technologie verantwoordelijker te gebruiken. Uiteindelijk gaat beeldherkenning er niet om dat machines zien zoals mensen. Het gaat erom dat machines anders zien en dat verschil gebruiken om sneller en consistentere beslissingen te nemen wanneer dat nodig is.
Veelgestelde vragen
AI-beeldherkenning is het proces waarbij een computer leert patronen in afbeeldingen te herkennen. In plaats van afbeeldingen te interpreteren zoals mensen dat doen, leert het systeem van voorbeelden en gebruikt het getallen en waarschijnlijkheden om te bepalen waar het naar kijkt.
Nee. AI begrijpt beelden niet conceptueel. Het verwerkt pixelwaarden en leert patronen op basis van statistische verbanden. De resultaten lijken misschien op wat mensen waarnemen, maar het proces is totaal anders.
De meeste moderne beeldherkenningssystemen maken gebruik van deep learning, met name convolutionele neurale netwerken. Deze modellen zijn ontworpen om visuele kenmerken zoals randen, vormen en texturen te leren via meerdere lagen.
Dat hangt af van de taak. Eenvoudige classificatieproblemen kunnen met duizenden afbeeldingen worden opgelost, terwijl complexe detectie- of segmentatietaken vaak tienduizenden of honderdduizenden gelabelde voorbeelden vereisen. De kwaliteit van de data is net zo belangrijk als de kwantiteit.
Annotatie vertelt het model wat het van elke afbeelding moet leren. Slechte annotatie leidt tot slechte voorspellingen. Hoogwaardige annotatie is vaak het meest tijdrovende onderdeel van het bouwen van een beeldherkenningssysteem, maar het heeft een directe invloed op de nauwkeurigheid en betrouwbaarheid.