
Beeldherkenning klinkt in eerste instantie misschien intimiderend. Neurale netwerken, datasets, trainingsloops, GPU's – het kan overweldigend lijken nog voordat je ook maar één regel code hebt geschreven. Maar in de praktijk draait het bij het bouwen van een AI voor beeldherkenning meer om het nemen van goede beslissingen, stap voor stap, dan om alles in één keer onder de knie te krijgen.
In essentie draait beeldherkenning om het trainen van een systeem om patronen in afbeeldingen te herkennen en consistente oordelen te vellen op basis van wat het ziet. Dat kan betekenen dat objecten worden geïdentificeerd, scènes worden geclassificeerd, defecten worden opgespoord of afwijkingen worden gesignaleerd. De technologie erachter is krachtig, maar het proces zelf is verrassend eenvoudig: definieer de taak, bereid de data voor, train een model, test het eerlijk en zet het in waar het daadwerkelijk nuttig is.
Dit artikel beschrijft dat proces op een praktische en nuchtere manier. Geen hype, geen shortcuts en geen aannames dat je een wetenschappelijk artikel aan het schrijven bent. Gewoon een helder overzicht van hoe AI voor beeldherkenning tegenwoordig wordt ontwikkeld, wat er echt toe doet in elke fase en waar mensen meestal de fout in gaan.

Begin met een probleem dat je duidelijk kunt beschrijven.
Voordat je met data of modellen aan de slag gaat, heb je een duidelijk omschreven taak nodig. Niet "afbeeldingen herkennen", maar iets concreets.
- Classificeert u een complete afbeelding in één categorie?
- Zoek je voorwerpen en teken je er kaders omheen?
- Identificeert u exacte vormen of grenzen op pixelniveau?
Elk van deze situaties is een ander probleem met verschillende kosten en risico's.
Veel projecten mislukken omdat ze vaag beginnen en pas te laat ingewikkeld worden. Als je je doel niet in één zin kunt uitleggen aan iemand zonder technische achtergrond, is het project nog niet klaar.
Goede voorbeelden
- “"Detecteer zichtbare schade aan carrosseriepanelen aan de hand van foto's."”
- “Tel het aantal opgestapelde boomstammen op luchtfoto's.”
- “"Bepaal of een gewasgebied vroege tekenen van stress vertoont."”
Slechte voorbeelden
- “Gebruik AI om afbeeldingen te analyseren.”
- “Ontwikkel slimme computervisie.”
Duidelijkheid op dit punt bespaart later maanden.
Begrijp hoe afbeeldingen getallen worden.
Een computer ziet geen objecten. Hij ziet reeksen getallen.
Elke afbeelding wordt omgezet in pixels, en elke pixel krijgt een waarde die intensiteit of kleur vertegenwoordigt. Een kleurenfoto is voor een model geen plaatje, maar een raster van getallen verdeeld over meerdere kanalen.
Beeldherkenning werkt door patronen in die getallen te leren. Randen, vormen, texturen, contrasten. Niet omdat het model de betekenis begrijpt, maar omdat het statistische regelmatigheden vindt die correleren met labels.
Dit is belangrijk omdat het je kijk op datakwaliteit verandert. Als het model faalt, komt dat vaak doordat de getallen die het ziet inconsistent, ruisig of misleidend zijn.
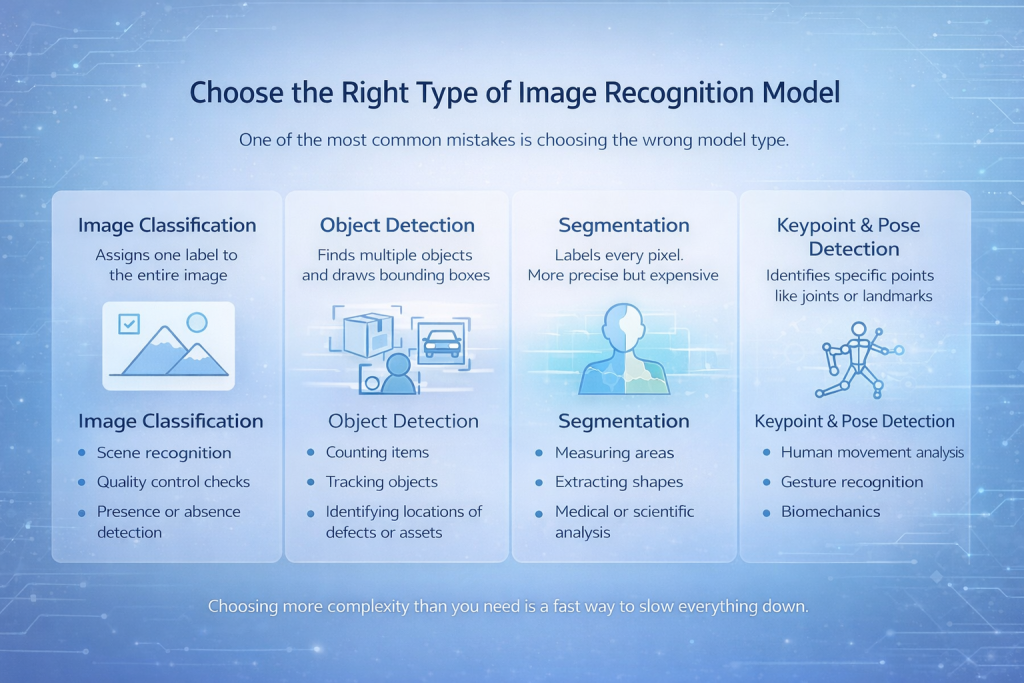
Kies het juiste type beeldherkenningsmodel.
Een van de meest voorkomende fouten is het kiezen van het verkeerde modeltype.
Er zijn verschillende hoofdcategorieën:
Beeldclassificatie
Het model kent één label toe aan de gehele afbeelding. Eenvoudig, snel en effectief wanneer het object van interesse de afbeelding domineert.
Het beste voor:
- Scèneherkenning
- kwaliteitscontroles
- Aanwezigheids- of afwezigheidsdetectie
Objectdetectie
Het model detecteert meerdere objecten en tekent daar omheen kaders.
Het beste voor:
- Artikelen tellen
- Volgobjecten
- Het lokaliseren van defecten of defecten.
Segmentatie
Elke pixel krijgt een label. Dit is nauwkeuriger, maar ook duurder.
Het beste voor:
- Meetgebieden
- Vormen extraheren
- Medische of wetenschappelijke analyse
Sleutelpunt- en houdingsdetectie
Het model identificeert specifieke punten zoals gewrichten of oriëntatiepunten.
Het beste voor:
- Analyse van menselijke beweging
- Gebarenherkenning
- Biomechanica
Het kiezen voor meer complexiteit dan nodig is, is een snelle manier om alles te vertragen.
Data is niet alleen belangrijk. Het is het project zelf.
Modellen trekken de aandacht. Data doen het echte werk.
Een sterk beeldherkenningssysteem is veel meer afhankelijk van de dataset dan van de architectuur. Zelfs het meest geavanceerde model zal falen als de data zwak of inconsistent is.
Kernprincipes die er echt toe doen:
Datavariëteit is belangrijker dan datavolume.
Tienduizend vergelijkbare afbeeldingen zijn vaak minder goed dan tweeduizend diverse. Verschillende hoeken, lichtomstandigheden, achtergronden, resoluties en apparaattypen zijn belangrijker dan het absolute aantal afbeeldingen.
Etiketten moeten overeenkomen met de werkelijkheid.
Als mensen discussiëren over labels, zal het model verwarring leren. Dubbelzinnige klassen moeten vroegtijdig worden samengevoegd of hergedefinieerd.
Evenwicht is belangrijk
Als één klasse domineert, wordt nauwkeurigheid misleidend. Een model kan "nauwkeurig" zijn door altijd de meerderheidsklasse te raden.
Annotatie is waar kwaliteit wordt gewonnen of verloren.
Het labelen gebeurt vaak gehaast, en dat is later te merken. Slechte annotatie creëert problemen die moeilijk te herkennen zijn tijdens de training, maar pijnlijk duidelijk worden in de praktijk. Modellen worden instabiel, voorspellingen lijken willekeurig en er stapelen zich steeds meer uitzonderlijke gevallen op. Elke verkeerd gelabelde afbeelding vergiftigt stilletjes het leerproces.
Goede annotatie begint met duidelijke labelregels die iedereen op dezelfde manier volgt. Wanneer verschillende mensen labels anders interpreteren, leert het model verwarring in plaats van patronen. Consistentie is net zo belangrijk als nauwkeurigheid, daarom zijn regelmatige steekproeven en kleine audits essentieel. Ze helpen afwijkingen vroegtijdig op te sporen, voordat ze zich door de hele dataset verspreiden.
Ook annotaties moeten ruimte hebben om te evolueren. Naarmate er nieuwe uitzonderingen opduiken, moeten labels worden verfijnd in plaats van geforceerd in definities die niet langer passen. Dit soort iteratieve opschoning is tijdrovend, maar het loont de moeite in termen van modelstabiliteit.
AI-ondersteunde labeltools kunnen processen versnellen, met name bij grote datasets, maar ze vervangen geen menselijk oordeel. Ze herhalen simpelweg de logica die ze krijgen aangereikt. Als de regels onduidelijk of gebrekkig zijn, zal automatisering de fout alleen maar vergroten, niet corrigeren.
Voorbewerking is niet cosmetisch.
Voorbewerking gaat niet alleen over het er netjes uit laten zien van afbeeldingen. Het gaat erom ongewenste variatie te verminderen en te benadrukken wat er echt toe doet.
Veelvoorkomende stappen die daadwerkelijk helpen:
- Afbeeldingen verkleinen naar een consistente resolutie.
- Pixelwaarden normaliseren
- Oriëntatie corrigeren
- Het wegsnijden van irrelevante gebieden
Data-augmentatie verdient speciale aandacht. Simpele transformaties zoals roteren, spiegelen, helderheidsverschuivingen of het toevoegen van ruis kunnen de generalisatie aanzienlijk verbeteren. Het doel is niet om het model te misleiden, maar om het voor te bereiden op de realiteit.
Als je data er te perfect uitziet, zal je model in de praktijk in paniek raken.
Modelarchitectuur is minder belangrijk dan je denkt.
De verleiding is groot om het nieuwste of meest besproken model na te jagen. Transformers, enorme infrastructuur en complexe pijpleidingen zien er misschien indrukwekkend uit op papier, maar ze bieden geen garantie voor betere resultaten.
In de praktijk zijn veel betrouwbare beeldherkenningssystemen gebouwd op beproefde architecturen. Convolutionele neurale netwerken domineren dit domein nog steeds, en daar is een goede reden voor. Ze zijn stabiel, efficiënt en gemakkelijker te begrijpen wanneer er iets misgaat. Die betrouwbaarheid is vaak belangrijker dan een paar extra procentpunten in benchmarktests.
Transfer learning is meestal het slimste startpunt. Het gebruik van een model dat al heeft geleerd van grote en diverse datasets biedt een sterke basis, vooral wanneer je eigen data beperkt is. Finetuning werkt het beste wanneer de nieuwe taak redelijk dicht in de buurt komt van wat het model eerder heeft gezien, wanneer overfitting actief wordt tegengegaan en wanneer hertraining zorgvuldig in plaats van agressief gebeurt. Kleine, weloverwogen aanpassingen leveren doorgaans betere resultaten op dan brute-force hertraining.
Grotere modellen zijn niet altijd betere modellen. Ze kosten meer om te trainen, zijn moeilijker te debuggen en falen vaak op subtiele manieren die lastig te achterhalen zijn.
Training is een iteratief gesprek met je data.
Training is geen kwestie van één klik. Het is een continu proces.
Je traint, observeert de resultaten, identificeert foutpatronen, past gegevens of parameters aan en herhaalt het proces.
Belangrijkste trainingsmethoden:
- Gebruik aparte trainings-, validatie- en testsets.
- Let op de verliescurves, niet alleen op de nauwkeurigheid.
- Stop met trainen wanneer de verbetering stagneert.
- Stem de leerfrequentie en batchgrootte zorgvuldig af.
GPU-acceleratie is onmisbaar voor serieus werk. Trainen op CPU's is prima voor leerdoelen, maar onpraktisch voor echte projecten. GPU's verkorten de iteratietijd, wat de modelkwaliteit direct verbetert doordat experimenteren mogelijk wordt.
Evaluatie moet verder gaan dan alleen nauwkeurigheid.
Nauwkeurigheid is een van de gemakkelijkst te berekenen meetwaarden, maar ook een van de gemakkelijkst te misinterpreteren. Een model kan zeer nauwkeurig lijken, maar in de praktijk toch nutteloos zijn.
Een goede evaluatie gaat dieper. Verwarringsmatrices helpen bloot te leggen waar het model consequent de verkeerde conclusies trekt. Precisie en recall zijn veel informatiever wanneer klassen onevenwichtig verdeeld zijn of wanneer bepaalde fouten meer impact hebben dan andere. Testen op volledig nieuwe, realistische afbeeldingen onthult vaak problemen die nooit aan het licht komen in schone validatiegegevens.
De meest waardevolle evaluatiestap blijft handmatige controle. Door direct te kijken naar mislukte voorspellingen en te vragen waarom ze zijn gebeurd, krijg je inzichten die geen enkele andere meetmethode volledig kan weergeven. Modellen zijn verrassend eerlijk over hun zwakheden als je de tijd neemt om hun fouten te onderzoeken in plaats van af te gaan op samenvattende cijfers.
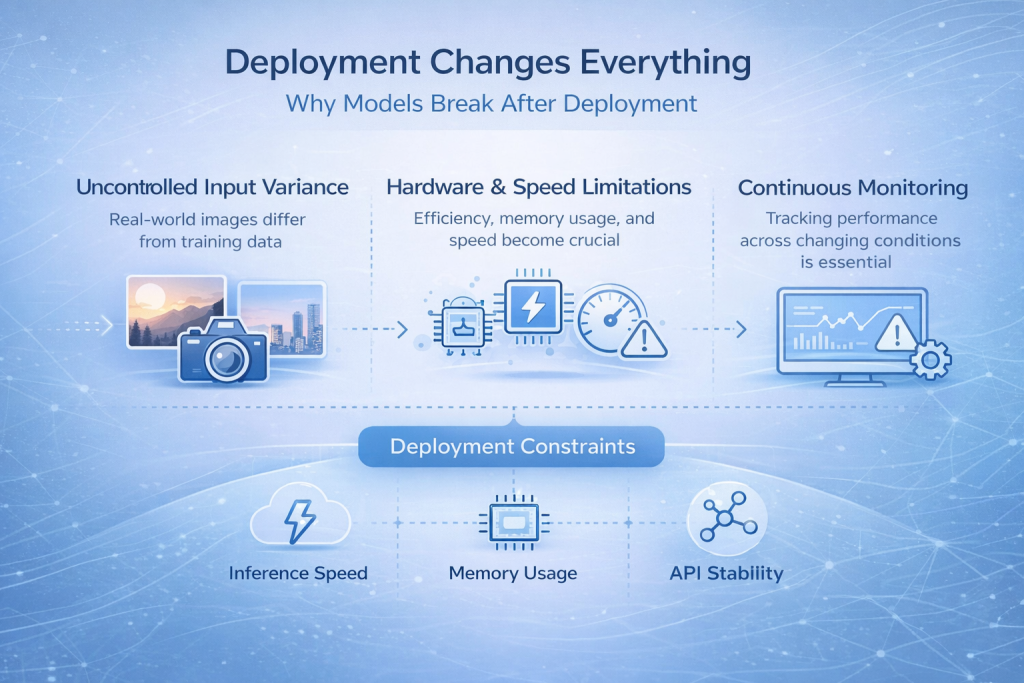
De implementatie verandert alles.
Waarom modellen na implementatie niet meer werken
Veel beeldherkenningsmodellen presteren goed tijdens de ontwikkeling, maar laten het vervolgens stilletjes afweten zodra ze in gebruik worden genomen. Dit is een van de meest voorkomende en frustrerende momenten in het hele proces.
De reden is simpel. Invoergegevens uit de praktijk lijken zelden op trainingsgegevens. Afbeeldingen zijn afkomstig van verschillende camera's, de lichtomstandigheden veranderen gedurende de dag, er kunnen compressieartefacten optreden en gebruikers volgen niet altijd de ideale gebruikspatronen. Zelfs kleine veranderingen in de manier waarop afbeeldingen worden vastgelegd, kunnen een model buiten het bereik brengen waarvoor het is getraind.
Wat in een gecontroleerde omgeving stabiel leek, blijkt plotseling onbetrouwbaar te zijn.
De beperkingen die je niet kunt negeren
Bij de implementatie moet je verder kijken dan alleen de nauwkeurigheid van het model. De inferentiesnelheid wordt cruciaal wanneer voorspellingen in realtime nodig zijn. Geheugengebruik is belangrijk wanneer het model op edge-apparaten of mobiele hardware draait. Hardwarebeperkingen bepalen welke architecturen überhaupt haalbaar zijn, en API-stabiliteit wordt essentieel zodra andere systemen afhankelijk zijn van je voorspellingen.
Monitoring is niet langer een optie, maar een noodzaak. Zonder inzicht in hoe het model zich na de release gedraagt, kunnen fouten onopgemerkt blijven totdat het vertrouwen verloren is.
Het model bruikbaar maken
Het exporteren van een model naar formaten zoals TensorFlow Lite of ONNX is niet zomaar een technische stap aan het einde van de pipeline. Het is onderdeel van het proces om een getraind model geschikt te maken voor gebruik in een productieomgeving. Deze formaten helpen het model aan te passen aan verschillende omgevingen, verminderen de overhead en verbeteren de compatibiliteit met de implementatiedoelen.
Een model dat goed presteert op een laptop, maar niet geschikt is voor implementatie, is nog niet af. Echt succes wordt pas bereikt wanneer het systeem consistent werkt waar het bedoeld is.
Beeldherkenning in de praktijk: hoe wij het bij FlyPix AI realiseren
Bij FlyPix-AI, We benaderen beeldherkenning niet als een laboratoriumoefening. We werken dagelijks met satelliet-, lucht- en dronebeelden, waar scènes dicht op elkaar staan, objecten elkaar overlappen en de omstandigheden nooit perfect zijn. Die realiteit bepaalt hoe we AI ontwikkelen en gebruiken.
Ons doel is altijd eenvoudig geweest: de knelpunten van handmatige visuele analyse wegnemen. Teams besteedden honderden uren aan het annoteren van beelden, het controleren van de resultaten en het opnieuw controleren ervan wanneer de omstandigheden veranderden. We hebben FlyPix ontwikkeld om dat werk te automatiseren met behulp van AI-agenten die objecten op grote schaal kunnen detecteren, monitoren en inspecteren, zonder aan nauwkeurigheid in te boeten.
Wat voor ons het belangrijkst is, is de praktische bruikbaarheid. Je zou geen diepgaande AI-kennis of een team van machine learning-engineers nodig moeten hebben om een model te trainen dat werkt voor jouw specifieke toepassing. Met FlyPix kunnen teams aangepaste beeldherkenningsmodellen creëren met hun eigen annotaties, gericht op de objecten die er echt toe doen in hun branche. Bouwplaatsen, havens, landbouwgrond, infrastructuur, bosgebieden – de beelden verschillen, maar de uitdaging blijft hetzelfde.
We ontwerpen alles met het oog op implementatie. Geospatiale data uit de praktijk verandert voortdurend, dus modellen moeten vanaf dag één met variatie om kunnen gaan. Dat betekent dat we systemen bouwen die betrouwbaar presteren, ook buiten schone demo's, die grote hoeveelheden beeldmateriaal snel verwerken en die resultaten leveren waar teams direct mee aan de slag kunnen. Voor ons is beeldherkenning pas succesvol als het standhoudt in de dagelijkse praktijk, niet alleen tijdens het testen.
Feedbacklussen houden het model in leven.
Een AI voor beeldherkenning is niet statisch. Gegevens veranderen. Omgevingen veranderen. Verwachtingen veranderen.
Duurzame systemen worden ontworpen met feedback in gedachten:
- Verzamel nieuwe afbeeldingen na de implementatie.
- Storingen in het spoor volgen
- Periodieke bijscholing
- Labels aanpassen wanneer de realiteit verandert.
Het negeren van leerprocessen na de implementatie is een van de snelste manieren om het vertrouwen in het systeem te verliezen.
Conclusie
Het bouwen van een goed werkende AI voor beeldherkenning draait minder om het najagen van de nieuwste modellen en meer om het goed aanpakken van de basisprincipes. Een duidelijke probleemdefinitie, gedisciplineerd datawerk, zorgvuldige evaluatie en een realistische implementatieplanning zijn veel belangrijker dan de keuze voor een specifiek algoritme.
De meest betrouwbare systemen zijn niet de meest complexe. Het zijn de systemen die gebouwd zijn met een eerlijk begrip van hoe beelden in de echte wereld veranderen en hoe modellen op die veranderingen reageren. Ze worden getraind met data die de realiteit weerspiegelt, geëvalueerd met behulp van meetwaarden die zwakke punten aan het licht brengen, en vanaf dag één ingezet met de beperkingen in gedachten.
Als er één conclusie te trekken valt, is het deze: beeldherkenning is een engineeringproces, geen eenmalig experiment. Wanneer je het op die manier benadert, zorgvuldig itereert en de focus houdt op de praktijk, blijven de resultaten doorgaans lang na de demonstratie overeind.
Veelgestelde vragen
AI voor beeldherkenning is een type computervisiesysteem dat leert patronen, objecten of kenmerken in afbeeldingen te herkennen. Het werkt door pixelgegevens te analyseren en getrainde modellen te gebruiken om visuele patronen te koppelen aan labels of uitkomsten.
Niet altijd. Hoewel grote datasets nuttig zijn, zijn diversiteit en kwaliteit belangrijker dan de hoeveelheid data. Met transfer learning en de juiste data-augmentatie kunnen bruikbare modellen getraind worden op relatief kleine, maar zorgvuldig samengestelde datasets.
Voor de meeste projecten is het een veilige en effectieve aanpak om te beginnen met een bewezen convolutioneel neuraal netwerk en transfer learning toe te passen. Complexere modellen moeten alleen worden gebruikt als daar een duidelijke reden voor is en er voldoende data beschikbaar is om ze te onderbouwen.
Alleen nauwkeurigheid is niet genoeg. Je moet kijken naar verwarringsmatrices, precisie en recall, en het model testen op echte afbeeldingen die nooit onderdeel waren van de training. Handmatige controle van mislukkingen is vaak de meest onthullende stap.
Dit gebeurt meestal omdat de productiebeelden afwijken van de trainingsdata. Veranderingen in belichting, camerakwaliteit, beeldcompressie of gebruikersgedrag kunnen allemaal de prestaties beïnvloeden. Deze discrepantie komt vaak voor en moet tijdens de ontwikkeling worden meegenomen in de planning.
Ja. Implementatie is geen laatste stap die tot het einde kan worden overgeslagen. Hardwarelimieten, inferentiesnelheid, geheugengebruik en integratievereisten hebben allemaal invloed op hoe het model moet worden gebouwd en getraind.