
KI-Bilderkennung klingt komplex, aber im Kern geht es darum, Maschinen beizubringen, Muster so zu erkennen wie Menschen – nur schneller und in viel größerem Umfang. Jedes Foto, Satellitenbild oder Videobild ist zunächst nur Datenmaterial, bis ein KI-System lernt, es zu interpretieren. Dieser Lernprozess wandelt Rohpixel in aussagekräftige Signale um: Objekte, Formen, Text oder Veränderungen im Zeitverlauf.
Dieser Artikel erklärt die Funktionsweise der KI-Bilderkennung im Detail. Nicht abstrakt theoretisch, sondern ganz praktisch: Wie Bilder in Zahlen umgewandelt werden, wie Modelle aus Beispielen lernen und warum Datenqualität wichtiger ist als ausgefeilte Algorithmen. Wenn Sie sich jemals gefragt haben, was genau zwischen dem Hochladen eines Bildes und dem Erhalt eines automatisierten Ergebnisses passiert, finden Sie hier die Antwort.
Was Bilderkennung in der KI wirklich bedeutet
Bilderkennung ist die Fähigkeit einer Maschine, Muster, Objekte, Texte oder Merkmale in einem Bild zu erkennen und ihnen eine Bedeutung zuzuordnen. Diese Bedeutung kann einfach sein, wie die Identifizierung eines Autos, oder komplex, wie die Erkennung von frühen Anzeichen von Pflanzenstress in Luftbildern.
Anders als herkömmliche Software folgen KI-Systeme keinen fest einprogrammierten Regeln wie “Wenn es vier Räder hat, ist es ein Auto”. Stattdessen lernen sie aus Beispielen. Tausende oder Millionen von beschrifteten Bildern werden verwendet, um dem System beizubringen, wie etwas unter verschiedenen Bedingungen, Blickwinkeln, Lichtverhältnissen und Umgebungen aussieht.
Im Kern ist Bilderkennung eine Form der Mustererkennung, die auf maschinellem Lernen und insbesondere auf Deep Learning basiert. Das System versteht keine Konzepte. Es lernt statistische Zusammenhänge zwischen visuellen Merkmalen und Ergebnissen.
Wie wir bei FlyPix KI-Bilderkennung in reale Ergebnisse umsetzen
Bei FlyPix, Wir nutzen KI-Bilderkennung als praktisches Werkzeug für die Bearbeitung von Satelliten-, Luft- und Drohnenbildern in großem Umfang. Unser Ziel ist es, Teams dabei zu unterstützen, ohne wochenlange manuelle Arbeit oder komplexe Einrichtungsprozesse von Rohbildern zu aussagekräftigen Erkenntnissen zu gelangen.
Wir setzen auf KI-Systeme, die Objekte in großen und komplexen Datensätzen erkennen, überwachen und analysieren können. Nutzer trainieren eigene KI-Modelle mit ihren Bilddaten und Anmerkungen – Programmierkenntnisse sind dafür nicht erforderlich. Sie legen fest, welche Informationen in Ihren Daten relevant sind, und das System lernt, diese zuverlässig zu erkennen.
Geschwindigkeit ist ein wesentlicher Wertfaktor. Was früher stundenlange manuelle Datenerfassung erforderte, lässt sich heute in Sekundenschnelle erledigen. Von der Landnutzungsklassifizierung und Infrastrukturprüfung bis hin zur Landwirtschaft und Umweltüberwachung – der Fokus liegt stets auf schnelleren und zuverlässigeren Entscheidungen.
FlyPix ist so konzipiert, dass es sich an verschiedene Branchen und Anwendungsfälle anpasst und diese nicht in einen einzigen Workflow zwingt. Indem wir die KI-Bilderkennung flexibel und zugänglich gestalten, erleichtern wir es Teams, sie im täglichen Betrieb und nicht nur in experimentellen Projekten einzusetzen.
Alles beginnt mit Pixeln
Jedes digitale Bild besteht aus einem Raster von Pixeln. Jedes Pixel enthält numerische Werte, die Farbe und Helligkeit beschreiben. In den meisten Bildern bedeutet dies drei Werte pro Pixel für Rot, Grün und Blau.
Für einen Menschen ist ein Foto einer Straße sofort erkennbar. Für ein KI-Modell ist dasselbe Bild eine große Zahlenmatrix. Es besitzt kein angeborenes Verständnis von Straßen, Gebäuden oder Menschen. Die Herausforderung der Bilderkennung besteht darin, einem System beizubringen, diese Zahlen sinnvoll zu interpretieren.
Bevor das Modell lernt, wird das Bild in ein numerisches Format umgewandelt, das es verarbeiten kann. Auflösung, Farbtiefe und Dateistruktur beeinflussen, wie viele Informationen verfügbar sind und wie aufwändig die Berechnung ist.
Vorverarbeitung: Bilder für das Lernen vorbereiten
Bilder von Kameras, Drohnen, Satelliten oder Smartphones sind fast nie einheitlich. Sie weisen unterschiedliche Auflösungen, Lichtverhältnisse, Aufnahmewinkel und Dateiformate auf. Manche sind scharf, andere verrauscht oder unscharf. Die direkte Zufuhr dieser Rohdaten in ein Modell führt zu instabilem und unvorhersehbarem Lernprozess. Die Vorverarbeitung ist der Schritt, in dem dieses visuelle Chaos bereinigt wird.
Standardisierung von Größe, Farbe und Format
Eine der ersten Aufgaben besteht darin, die Bilder zu vereinheitlichen. Da die Modelle eine einheitliche Eingabeform erwarten, werden die Bilder auf eine feste Auflösung skaliert. Die Farbwerte werden normalisiert, damit Helligkeits- und Kontrastunterschiede den Lernprozess nicht beeinträchtigen. Dies hilft dem Modell, sich auf die Struktur zu konzentrieren, anstatt durch Belichtungsänderungen oder Kameraeinstellungen abgelenkt zu werden.
Reduzierung von Rauschen und visuellen Verzerrungen
Störungen durch Sensoren, Bewegungsunschärfe, Kompressionsartefakte oder Witterungseinflüsse können wichtige Details verdecken. Vorverarbeitungstechniken helfen, diese Effekte zu reduzieren und Kanten und Formen für das Modell leichter erkennbar zu machen. Dieser Schritt verbessert das Bild zwar nicht im menschlichen Sinne, aber er verbessert die Lesbarkeit der Daten für das Netzwerk.
Den Fokus auf das Wesentliche richten
In vielen Fällen ist nur ein Teil eines Bildes relevant. Durch Zuschneiden, Maskieren oder Isolieren von relevanten Bereichen lassen sich störende Elemente entfernen. Indem man den vom Modell wahrgenommenen Bereich einschränkt, wird das Lernen schneller und präziser, insbesondere bei Aufgaben wie Objekterkennung oder medizinischer Bildgebung.
Warum die Vorverarbeitung die Leistung in der Praxis direkt beeinflusst
Die Vorverarbeitung macht ein Modell nicht automatisch intelligenter. Sie schafft jedoch bessere Bedingungen für das Lernen. Wird dieser Schritt überhastet oder schlecht konzipiert, funktionieren Modelle zwar in kontrollierten Tests gut, versagen aber in realen Situationen. Eine sorgfältige Vorverarbeitung ist oft der entscheidende Unterschied zwischen einem System, das in der Theorie funktioniert, und einem, das auch in der Praxis funktioniert.
Merkmalslernen: Wie KI Muster erkennt
Menschen lernen, Objekte durch das Erkennen ihrer Merkmale zu erfassen. Kanten, Formen, Texturen und Proportionen spielen dabei eine Rolle. KI-Modelle lernen auf ähnliche, aber mathematischere Weise.
Die meisten modernen Bilderkennungssysteme basieren auf Convolutional Neural Networks (CNNs). Diese Netzwerke sind so konzipiert, dass sie Bilder mithilfe kleiner Filter scannen, die sich über das Bild bewegen und lokale Muster erkennen.
Die ersten Schichten eines CNN erkennen einfache Merkmale wie Kanten, Ecken und Farbverläufe. Mittlere Schichten kombinieren diese zu Formen und Texturen. Tiefere Schichten fügen diese Formen zu komplexeren Mustern zusammen, die Objekten oder relevanten Bereichen entsprechen.
Der Kerngedanke ist die Hierarchie. Das Modell springt nicht direkt von Pixeln zu “Das ist ein Baum”. Es baut dieses Verständnis Schicht für Schicht auf.
Warum Faltung wichtig ist
Die Faltung ermöglicht es, denselben Musterdetektor auf das gesamte Bild anzuwenden. Eine vertikale Kante bleibt eine vertikale Kante, unabhängig davon, ob sie sich auf der linken oder rechten Seite des Bildes befindet.
Dieser Ansatz macht Modelle effizienter und robuster. Anstatt exakte Pixelanordnungen zu speichern, lernt das System wiederverwendbare visuelle Muster. Dies ist einer der Gründe, warum CNNs bei unterschiedlichen Bildgrößen und -layouts so gut funktionieren.
Um die Datenmenge zu reduzieren und gleichzeitig wichtige Informationen zu erhalten, werden häufig Pooling-Layer eingesetzt. Dies trägt zur Kontrolle der Rechenkosten bei und verhindert, dass das Modell zu empfindlich auf kleinste Abweichungen reagiert.
Das Modell trainieren: Aus Beispielen lernen
Im Training findet die eigentliche Bilderkennung statt. Dem Modell wird eine große Menge an beschrifteten Bildern gezeigt. Jedes Bild wird mit der richtigen Antwort verknüpft, z. B. “gesunde Ernte”, “beschädigte Straße” oder “Person anwesend”.”
Während des Trainings verläuft der Prozess in einer sich wiederholenden Schleife:
- Das Modell analysiert ein Eingabebild und generiert eine Vorhersage.
- Die Vorhersage wird mit dem korrekten Label verglichen.
- Die Differenz zwischen den beiden Werten wird als Fehler gemessen.
- Das Modell passt seine internen Parameter an, um diesen Fehler zu reduzieren.
- Derselbe Prozess wiederholt sich bei Tausenden oder Millionen von Beispielen.
Diese schrittweise Anpassung ermöglicht es dem System, sich im Laufe der Zeit zu verbessern.
Die Rückpropagation ist der Mechanismus, der dieses Lernen ermöglicht. Sie verfolgt Fehler rückwärts durch das Netzwerk und aktualisiert die Gewichte jeder Schicht, sodass zukünftige Vorhersagen genauer werden.
Die Qualität des Trainings hängt stark von den verwendeten Daten ab. Ist der Datensatz zu klein, schlecht beschriftet oder in bestimmte Richtungen verzerrt, übernimmt das Modell diese Schwächen. Selbst gründlichste Optimierung kann minderwertige oder unausgewogene Trainingsdaten nicht vollständig kompensieren.
Die Rolle von gelabelten Daten
Beschriftete Daten bilden die Grundlage der überwachten Bilderkennung. Jede Beschriftung gibt dem Modell vor, was es aus einem Bild lernen soll.
Das Erstellen dieser Etiketten ist oft der teuerste und zeitaufwändigste Teil des Prozesses. Menschliche Bearbeiter müssen Objekte sorgfältig markieren, Begrenzungsrahmen zeichnen, Bereiche segmentieren oder Bilder klassifizieren.
Hochwertige Annotationen führen zu besseren Modellen. Mangelhafte Annotationen führen zu Verwirrung und unzuverlässigen Ergebnissen. Daher lassen sich viele Fehler bei der Bilderkennung eher auf den Datensatz als auf den Algorithmus zurückführen.
Transferlernen und Inferenz: Vom vortrainierten Modell zu realen Vorhersagen
Das Training eines tiefen neuronalen Netzes von Grund auf erfordert eine große Menge an gelabelten Daten und erhebliche Rechenleistung. Deshalb beginnen viele Teams nicht bei Null, sondern nutzen Transferlernen.
So funktioniert Transferlernen
Transferlernen beginnt mit einem Modell, das bereits allgemeine visuelle Merkmale aus einem großen Datensatz gelernt hat. Dieses vortrainierte Modell versteht bereits gängige Muster wie Kanten, Texturen und Formen. Anschließend wird es mithilfe eines kleineren, aufgabenspezifischen Datensatzes für eine bestimmte Aufgabe feinabgestimmt.
In der Praxis bleiben die frühen Schichten meist weitgehend unverändert, während spätere Schichten an die neue Aufgabe angepasst werden. Beispielsweise kann ein mit allgemeinen Bildern trainiertes Modell so angepasst werden, dass es Defekte an Industriekomponenten oder Muster in medizinischen Scans erkennt. Dieser Ansatz beschleunigt die Entwicklung und verbessert häufig die Genauigkeit, insbesondere bei kleinen Datensätzen.
Vom Training zur Schlussfolgerung
Sobald das Modell trainiert oder feinabgestimmt ist, wechselt es in den Inferenzmodus. In dieser Phase verarbeitet es neue, unbekannte Bilder und erstellt Vorhersagen.
Die Inferenzpipeline spiegelt die Trainingspipeline wider:
- Die Bilder werden vorverarbeitet
- Sie werden durch das Netzwerk weitergeleitet.
- Die Ausgabe erfolgt in Form von Bezeichnungen, Wahrscheinlichkeiten, erkannten Objekten oder segmentierten Regionen.
An diesem Punkt verschiebt sich die Priorität. Ziel ist nicht mehr das Lernen, sondern eine konstante Leistung. In realen Systemen muss die Inferenz oft in Echtzeit oder nahezu in Echtzeit erfolgen, daher sind Geschwindigkeit und Zuverlässigkeit genauso wichtig wie die reine Genauigkeit.
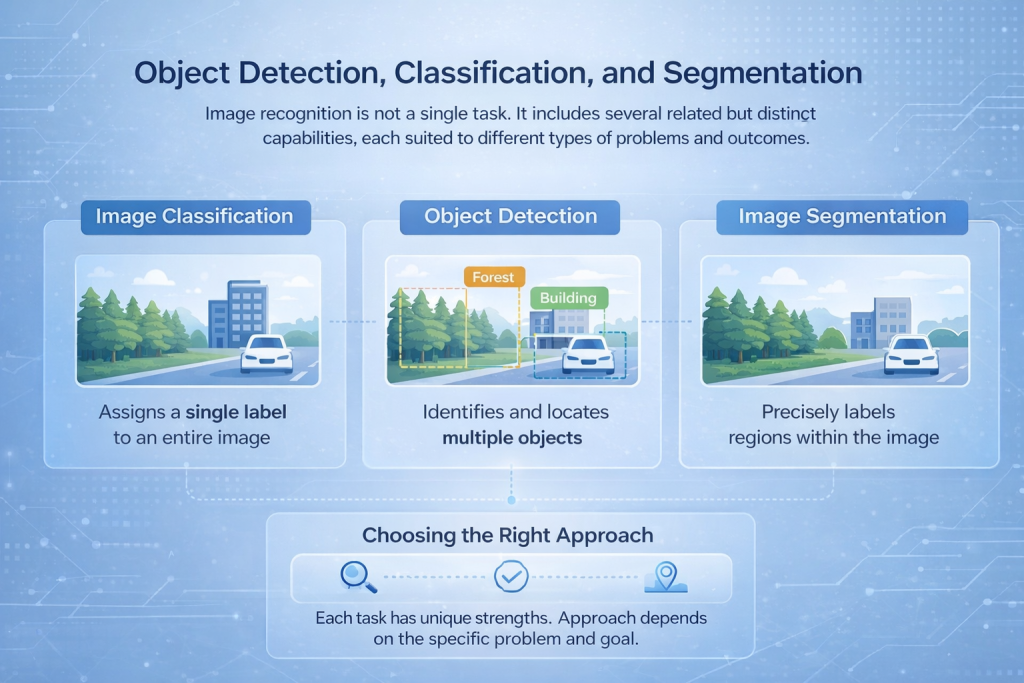
Objekterkennung, Klassifizierung und Segmentierung
Bilderkennung ist keine einheitliche Aufgabe. Sie umfasst mehrere verwandte, aber unterschiedliche Fähigkeiten, die jeweils für verschiedene Problemtypen und Ergebnisse geeignet sind.
Bildklassifizierung
Die Bildklassifizierung ordnet einem gesamten Bild eine einzige Kategorie zu. Das Modell analysiert die gesamte Szene und entscheidet, welche Kategorie sie am besten beschreibt, beispielsweise ob ein Bild einen Wald, ein Gebäude oder ein Fahrzeug enthält. Dieser Ansatz eignet sich gut, wenn der Gesamtinhalt wichtiger ist als der genaue Standort.
Object Detection
Die Objekterkennung geht noch einen Schritt weiter, indem sie mehrere Objekte im selben Bild identifiziert und lokalisiert. Anstatt nur ein einzelnes Label zu verwenden, zeichnet das Modell Begrenzungsrahmen um die relevanten Objekte und klassifiziert jedes einzelne. Dies wird häufig in Anwendungen wie Verkehrsüberwachung, Sicherheitssystemen und industriellen Inspektionen eingesetzt.
Bildsegmentierung
Die Segmentierung ermöglicht die detaillierteste Analyse. Sie kennzeichnet einzelne Pixel oder Bereiche innerhalb eines Bildes und erlaubt dem System so, Objekte mit hoher Präzision zu trennen. Dies ist unerlässlich in Anwendungsfällen wie der medizinischen Bildgebung, der Landnutzungskartierung oder der Oberflächenanalyse, wo exakte Grenzen entscheidend sind.
Die richtige Herangehensweise wählen
Jede dieser Aufgaben erfordert unterschiedliche Netzwerkarchitekturen und Trainingsstrategien. Die richtige Wahl hängt vom jeweiligen Problem ab, sei es die Zählung von Fahrzeugen, das Lesen von Texten oder die detaillierte Kartierung der Landnutzung.
Leistungsmessung
Bilderkennungsmodelle werden anhand von Metriken wie Genauigkeit, Präzision, Trefferquote und Schnittmenge über Vereinigung bewertet.
Genauigkeit allein ist oft irreführend. Ein Modell, das ein Objekt selten erkennt, kann genau erscheinen, nur weil das Objekt selten ist. Präzision und Trefferquote geben ein klareres Bild von der Zuverlässigkeit des Modells.
Tests sollten stets mit Daten durchgeführt werden, die das Modell noch nie zuvor gesehen hat. Dies hilft aufzudecken, ob das System allgemeine Muster gelernt oder lediglich den Trainingsdatensatz auswendig gelernt hat.
Komplexität in der realen Welt, Verzerrungen und praktische Grenzen
KI-Bilderkennung funktioniert am besten in kontrollierten Umgebungen, doch reale Umgebungen sind selten kontrolliert. Sobald die Modelle das Labor verlassen und mit realen Bedingungen konfrontiert werden, treten ihre Grenzen viel deutlicher zutage.
Warum reale Bedingungen schwer zu modellieren sind
Die Lichtverhältnisse ändern sich im Laufe des Tages. Objekte überlagern sich oder verschwinden teilweise aus dem Blickfeld. Das Wetter beeinträchtigt die Sicht. Kameras bewegen sich, fallen aus oder liefern fehlerhafte Daten. All dies führt zu Störungen, mit denen Modelle umgehen lernen müssen.
Ein System, das in Tests gut funktioniert, kann Probleme bekommen, sobald sich diese Variablen häufen. Deshalb sind kontinuierliches Testen, Überwachen und Nachschulen unerlässliche Bestandteile jedes Produktionssystems und keine optionalen Verbesserungen.
Die Rolle der menschlichen Aufsicht
Die KI-Bilderkennung ist leistungsstark, aber nicht unfehlbar. In sicherheitskritischen oder besonders kritischen Anwendungen bleibt die menschliche Überprüfung unerlässlich. Menschen liefern Kontext, Urteilsvermögen und Verantwortlichkeit in Situationen, in denen automatisierte Entscheidungen allein nicht ausreichen.
Wie Voreingenommenheit in Bilderkennungssysteme gelangt
Modelle lernen direkt aus den Daten, mit denen sie trainiert wurden, einschließlich ihrer Lücken und Ungleichgewichte. Sind bestimmte Umgebungen, Bevölkerungsgruppen oder Zustände unterrepräsentiert, leidet die Leistung in diesen Fällen.
Voreingenommenheit wird besonders in Bereichen wie Überwachung, Zugangskontrolle oder öffentlicher Sicherheit problematisch, wo Fehler reale Konsequenzen haben können. Diese Probleme werden selten allein durch Algorithmen verursacht.
Warum Voreingenommenheit kein rein technisches Problem ist
Es gibt keine einfache technische Lösung für Verzerrungen. Um Fairness und Zuverlässigkeit zu verbessern, ist Folgendes erforderlich:
- Vielfältigere und repräsentativere Datensätze
- Sorgfältige Bewertung verschiedener Szenarien
- Laufende Überprüfung der Verwendung und Aktualisierung der Modelle
Verzerrungen sind letztlich eine Herausforderung für Daten und Prozesse. Ihre Bekämpfung erfordert bewusste Entscheidungen, nicht nur bessere Modelle.

Datenschutz und ethische Überlegungen
Bilderkennung beinhaltet oft sensible Daten. Gesichter, Orte und Verhaltensweisen können aus Bildern abgeleitet werden, manchmal ohne dass sich die betroffene Person dessen vollständig bewusst ist.
Verantwortungsvoller Umgang erfordert mehr als nur technische Genauigkeit. Er bedarf klarer Regeln und bewusster Grenzen, darunter:
- Transparente Datenerfassungs- und Nutzungsrichtlinien
- Ausdrückliche Einwilligung, wenn es um personenbezogene Daten geht
- Sichere Speicherung und kontrollierter Zugriff auf Bilddaten
- Einhaltung lokaler und internationaler Datenschutzbestimmungen
- Klare Verantwortlichkeit für die Verwendung der vom System getroffenen Entscheidungen
Ethische Erwägungen sind kein nachträglicher Gedanke. Sie prägen das Vertrauen der Öffentlichkeit, die rechtliche Akzeptanz und die Frage, ob Bilderkennungssysteme langfristig praktikabel bleiben.
Warum Bilderkennung wichtig ist
Trotz ihrer Herausforderungen hat sich die KI-Bilderkennung branchenübergreifend zu einem unverzichtbaren Werkzeug entwickelt. Sie ermöglicht die Automatisierung dort, wo die menschliche Inspektion langsam, teuer oder uneinheitlich wäre.
Von der medizinischen Diagnostik bis zur Landwirtschaft, von der Infrastrukturüberwachung bis zum Einzelhandel – die Fähigkeit, aus visuellen Daten Erkenntnisse zu gewinnen, verändert die Art und Weise, wie Entscheidungen getroffen werden.
Der wahre Wert liegt nicht im Ersetzen, sondern im Erweitern menschlichen Urteilsvermögens. KI kümmert sich um Skalierung und Geschwindigkeit. Menschen kümmern sich um Kontext und Verantwortung.
Fazit: Von Pixeln zu Entscheidungen
KI-Bilderkennung funktioniert, weil sie eine komplexe menschliche Fähigkeit in überschaubare Schritte zerlegt. Pixel werden zu Zahlen. Zahlen werden zu Mustern. Muster werden zu Vorhersagen. Es gibt keinen magischen Moment, in dem eine Maschine plötzlich ein Bild versteht. Es gibt nur Lernen, Iteration und Verfeinerung.
Das Verständnis dieses Prozesses hilft, realistische Erwartungen zu entwickeln. Es unterstützt Teams außerdem dabei, bessere Systeme zu entwickeln, die richtigen Fragen zu stellen und die Technologie verantwortungsvoller einzusetzen. Letztendlich geht es bei der Bilderkennung nicht darum, dass Maschinen wie Menschen sehen. Es geht darum, dass Maschinen anders sehen und diesen Unterschied nutzen, um in entscheidenden Momenten schnellere und konsistentere Entscheidungen zu treffen.
Häufig gestellte Fragen
KI-Bilderkennung ist der Prozess, einem Computer beizubringen, Muster in Bildern zu erkennen. Anstatt Bilder wie Menschen zu verstehen, lernt das System anhand von Beispielen und verwendet Zahlen und Wahrscheinlichkeiten, um zu entscheiden, was es betrachtet.
Nein. KI versteht Bilder nicht konzeptionell. Sie verarbeitet Pixelwerte und lernt Muster anhand statistischer Zusammenhänge. Die Ergebnisse mögen der menschlichen Wahrnehmung ähneln, aber der Prozess ist völlig anders.
Die meisten modernen Bilderkennungssysteme nutzen Deep Learning, insbesondere Convolutional Neural Networks (CNNs). Diese Modelle sind darauf ausgelegt, visuelle Merkmale wie Kanten, Formen und Texturen durch mehrere Schichten zu erlernen.
Das hängt von der Aufgabe ab. Einfache Klassifizierungsprobleme lassen sich mit Tausenden von Bildern lösen, während komplexe Erkennungs- oder Segmentierungsaufgaben oft Zehntausende oder Hunderttausende von annotierten Beispielen erfordern. Die Datenqualität ist dabei genauso wichtig wie die Datenmenge.
Die Annotation gibt dem Modell vor, was es aus jedem Bild lernen soll. Unzureichende Beschriftungen führen zu fehlerhaften Vorhersagen. Die Erstellung hochwertiger Annotationen ist oft der zeitaufwändigste Teil beim Aufbau eines Bilderkennungssystems, beeinflusst aber direkt dessen Genauigkeit und Zuverlässigkeit.