
Bilderkennung klingt zunächst einschüchternd. Neuronale Netze, Datensätze, Trainingsschleifen, GPUs – das kann überwältigend wirken, noch bevor man eine Zeile Code geschrieben hat. Doch in der Praxis geht es beim Aufbau einer KI für Bilderkennung weniger darum, alles auf einmal zu beherrschen, sondern vielmehr darum, Schritt für Schritt gute Entscheidungen zu treffen.
Im Kern geht es bei der Bilderkennung darum, einem System beizubringen, Muster in Bildern zu erkennen und auf Grundlage dieser Muster konsistente Schlussfolgerungen zu ziehen. Das kann die Identifizierung von Objekten, die Klassifizierung von Szenen, das Aufspüren von Fehlern oder das Markieren von Anomalien umfassen. Die zugrundeliegende Technologie ist leistungsstark, der Prozess selbst jedoch überraschend bodenständig: Aufgabe definieren, Daten aufbereiten, ein Modell trainieren, es gründlich testen und es dort einsetzen, wo es tatsächlich nützlich ist.
Dieser Artikel führt Sie praxisnah und unkompliziert durch diesen Prozess. Keine leeren Versprechungen, keine Abkürzungen und keine Annahme, dass Sie eine wissenschaftliche Arbeit verfassen. Er bietet Ihnen einen klaren Einblick in die Funktionsweise von KI-gestützter Bilderkennung, die wichtigsten Aspekte in jeder Phase und die häufigsten Fehlerquellen.

Beginnen Sie mit einem Problem, das Sie klar beschreiben können.
Bevor Sie mit Daten oder Modellen arbeiten, benötigen Sie eine klar definierte Aufgabe. Nicht “Bilder erkennen”, sondern etwas Konkretes.
- Ordnen Sie das gesamte Bild einer einzigen Kategorie zu?
- Suchst du Gegenstände und zeichnest Kästchen darum?
- Identifizieren Sie exakte Formen oder Grenzen auf Pixelebene?
Jedes dieser Probleme stellt ein anderes Problem mit unterschiedlichen Kosten und Risiken dar.
Viele Projekte scheitern, weil sie vage beginnen und zu spät kompliziert werden. Wenn Sie Ihr Ziel nicht in einem Satz jemandem ohne technischen Hintergrund erklären können, ist es noch nicht reif dafür.
Gute Beispiele
- “Sichtbare Schäden an Karosserieteilen anhand von Fotos erkennen.”
- “Zählen Sie gestapelte Baumstämme auf Luftbildern.”
- “Feststellen, ob ein Anbaugebiet frühe Stresssymptome aufweist.”
Schlechte Beispiele
- “KI zur Bildanalyse einsetzen.”
- “Intelligente Computer Vision entwickeln.”
Klarheit hier spart Monate später.
Verstehen, wie Bilder zu Zahlen werden.
Ein Computer sieht keine Objekte. Er sieht Zahlenreihen.
Jedes Bild wird in Pixel umgewandelt, und jedes Pixel wird zu einem Wert, der Intensität oder Farbe repräsentiert. Ein Farbbild ist kein Modell für ein Modell. Es ist ein Raster aus Zahlen über mehrere Kanäle.
Die Bilderkennung funktioniert, indem sie Muster in den Zahlen erkennt: Kanten, Formen, Texturen und Kontraste. Nicht weil das Modell die Bedeutung versteht, sondern weil es statistische Regelmäßigkeiten findet, die mit den Bezeichnungen korrelieren.
Das ist wichtig, weil es Ihre Sichtweise auf die Datenqualität verändert. Wenn das Modell versagt, liegt das oft daran, dass die verwendeten Zahlen inkonsistent, verrauscht oder irreführend sind.
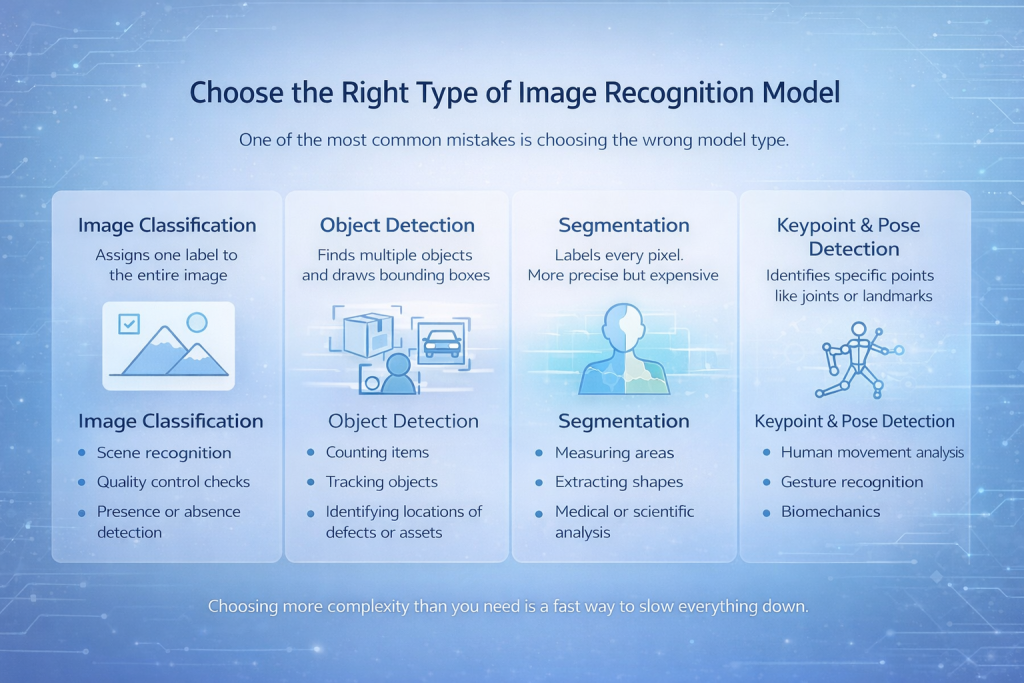
Wählen Sie den richtigen Typ von Bilderkennungsmodell
Einer der häufigsten Fehler ist die Wahl des falschen Modelltyps.
Es gibt mehrere Kernkategorien:
Bildklassifizierung
Das Modell ordnet dem gesamten Bild eine einzige Bezeichnung zu. Einfach, schnell und effektiv, wenn das relevante Objekt das Bild dominiert.
Geeignet für:
- Szenenerkennung
- Qualitätskontrollen
- Anwesenheits- oder Abwesenheitserkennung
Object Detection
Das Modell findet mehrere Objekte und zeichnet Begrenzungsrahmen um sie herum.
Geeignet für:
- Gegenstände zählen
- Objekte verfolgen
- Identifizierung von Fehler- oder Anlagenstandorten
Segmentierung
Jedem Pixel wird ein Label zugewiesen. Das ist präziser, aber auch teurer.
Geeignet für:
- Messbereiche
- Formen extrahieren
- Medizinische oder wissenschaftliche Analyse
Schlüsselpunkt- und Posenerkennung
Das Modell identifiziert spezifische Punkte wie Gelenke oder Orientierungspunkte.
Geeignet für:
- Analyse menschlicher Bewegungen
- Gestenerkennung
- Biomechanik
Die Wahl einer unnötig komplexen Lösung führt schnell dazu, dass alles nur noch langsamer wird.
Daten sind nicht nur wichtig. Sie sind das Projekt.
Modelle erregen Aufmerksamkeit. Daten leisten die eigentliche Arbeit.
Ein leistungsfähiges Bilderkennungssystem hängt weitaus stärker vom Datensatz als von der Architektur ab. Selbst das fortschrittlichste Modell versagt, wenn die Daten unzureichend oder inkonsistent sind.
Entscheidende Grundprinzipien:
Datenvielfalt schlägt Datenvolumen
Zehntausend ähnliche Bilder sind oft schlechter als zweitausend unterschiedliche. Unterschiedliche Blickwinkel, Lichtverhältnisse, Hintergründe, Auflösungen und Gerätetypen sind wichtiger als die reine Anzahl.
Etiketten müssen der Realität entsprechen
Wenn Menschen über Bezeichnungen streiten, lernt das Modell Verwirrung. Mehrdeutige Klassen sollten frühzeitig zusammengeführt oder neu definiert werden.
Ausgewogenheit ist wichtig
Wenn eine Klasse dominiert, wird die Genauigkeit irreführend. Ein Modell kann “genau” sein, indem es immer die Mehrheitsklasse vorhersagt.
Bei der Annotation entscheidet sich, ob Qualität gewonnen oder verloren geht.
Die Beschriftung wird oft überhastet vorgenommen, was sich später bemerkbar macht. Mangelhafte Annotationen führen zu Problemen, die während des Trainings schwer zu erkennen sind, im praktischen Einsatz aber schmerzlich deutlich werden. Modelle werden instabil, Vorhersagen wirken willkürlich, und Grenzfälle häufen sich. Jedes falsch beschriftete Bild beeinträchtigt den Lernprozess.
Eine gute Annotation beginnt mit klaren Kennzeichnungsregeln, die von allen einheitlich befolgt werden. Wenn verschiedene Personen Kennzeichnungen unterschiedlich interpretieren, lernt das Modell Verwirrung statt Muster. Konsistenz ist genauso wichtig wie Genauigkeit, weshalb regelmäßige Stichproben und kleinere Überprüfungen unerlässlich sind. Sie helfen, Abweichungen frühzeitig zu erkennen, bevor sie sich im gesamten Datensatz ausbreiten.
Auch die Annotation muss sich weiterentwickeln können. Wenn neue Sonderfälle auftreten, sollten Bezeichnungen verfeinert werden, anstatt sie in Definitionen zu pressen, die nicht mehr passen. Diese iterative Bereinigung ist zwar langsam, zahlt sich aber durch die Stabilität des Modells aus.
KI-gestützte Kennzeichnungstools können Prozesse beschleunigen, insbesondere bei großen Datensätzen, ersetzen aber nicht das menschliche Urteilsvermögen. Sie wiederholen lediglich die vorgegebene Logik. Sind die Regeln unklar oder fehlerhaft, verstärkt die Automatisierung den Fehler, anstatt ihn zu beheben.
Vorbehandlung ist nicht kosmetisch.
Bei der Vorverarbeitung geht es nicht nur darum, Bilder sauber aussehen zu lassen. Es geht darum, unerwünschte Abweichungen zu reduzieren und das Wesentliche hervorzuheben.
Gängige Schritte, die tatsächlich helfen:
- Bilder auf eine einheitliche Auflösung skalieren
- Normalisierung der Pixelwerte
- Ausrichtung korrigieren
- irrelevante Bereiche abschneiden
Der Datenerweiterung gebührt besondere Aufmerksamkeit. Einfache Transformationen wie Rotation, Spiegelung, Helligkeitsverschiebung oder Rauscheinfügung können die Generalisierungsfähigkeit deutlich verbessern. Ziel ist es nicht, das Modell auszutricksen, sondern es auf die Realität vorzubereiten.
Wenn Ihre Daten zu perfekt aussehen, wird Ihr Modell in der realen Welt versagen.
Die Modellarchitektur ist weniger wichtig als Sie denken
Es besteht eine große Versuchung, dem neuesten oder meistdiskutierten Modell hinterherzujagen. Transformatoren, massive Backbone-Systeme und komplexe Pipelines mögen auf dem Papier beeindruckend aussehen, sind aber keine Garantie für bessere Ergebnisse.
In der Praxis basieren viele zuverlässige Bilderkennungssysteme auf bewährten Architekturen. Convolutional Neural Networks (CNNs) dominieren diesen Bereich aus gutem Grund. Sie sind stabil, effizient und leichter nachvollziehbar, wenn Fehler auftreten. Diese Zuverlässigkeit ist oft wichtiger als ein paar zusätzliche Prozentpunkte in Benchmark-Tests.
Transferlernen ist meist der beste Ausgangspunkt. Ein Modell, das bereits mit großen und vielfältigen Datensätzen gelernt hat, bietet eine solide Grundlage, insbesondere bei begrenzten eigenen Daten. Feinabstimmung ist am effektivsten, wenn die neue Aufgabe dem bisherigen Modell ähnelt, Überanpassung aktiv vermieden und das Retraining sorgfältig statt aggressiv durchgeführt wird. Kleine, gezielte Anpassungen sind in der Regel effektiver als ein umfassendes Retraining.
Größere Modelle sind nicht immer bessere Modelle. Sie sind teurer in der Anschaffung, schwieriger zu debuggen und weisen oft subtile Fehler auf, die schwer nachzuvollziehen sind.
Training ist ein iterativer Dialog mit Ihren Daten
Training ist keine Ein-Klick-Aktion. Es ist ein Kreislauf.
Man trainiert, beobachtet die Ergebnisse, identifiziert Fehlermuster, passt Daten oder Parameter an und wiederholt den Vorgang.
Wichtige Schulungspraktiken:
- Verwenden Sie separate Trainings-, Validierungs- und Testdatensätze.
- Achten Sie auf die Verlustkurven, nicht nur auf die Genauigkeit.
- Beende das Training, wenn keine Fortschritte mehr erzielt werden.
- Passen Sie die Lernrate und die Batchgröße sorgfältig an.
Für anspruchsvolle Aufgaben ist GPU-Beschleunigung unerlässlich. Das Training auf CPUs eignet sich zwar zum Lernen, ist aber für reale Projekte unpraktisch. GPUs verkürzen die Iterationszeit und verbessern so die Modellqualität direkt, da sie Experimente ermöglichen.
Die Bewertung muss über die Genauigkeit hinausgehen.
Genauigkeit ist eine der am einfachsten zu berechnenden Kennzahlen und gleichzeitig eine der am leichtesten misszuverstehenden. Ein Modell kann hochgenau erscheinen und dennoch unter realen Bedingungen nutzlos sein.
Eine gute Evaluierung geht tiefer. Konfusionsmatrizen helfen aufzudecken, wo das Modell systematisch falsche Entscheidungen trifft. Präzision und Trefferquote sind deutlich aussagekräftiger, wenn die Klassen unausgewogen sind oder bestimmte Fehler schwerwiegendere Folgen haben als andere. Tests mit völlig neuen, realen Bildern decken oft Probleme auf, die in sauberen Validierungsdaten nie sichtbar werden.
Der wertvollste Evaluierungsschritt ist nach wie vor die manuelle Überprüfung. Die direkte Betrachtung fehlgeschlagener Vorhersagen und die Frage nach deren Ursachen liefern Erkenntnisse, die keine Kennzahl vollständig erfassen kann. Modelle sind erstaunlich ehrlich hinsichtlich ihrer Schwächen, wenn man sich die Zeit nimmt, ihre Fehler zu untersuchen, anstatt sich auf zusammenfassende Zahlen zu verlassen.
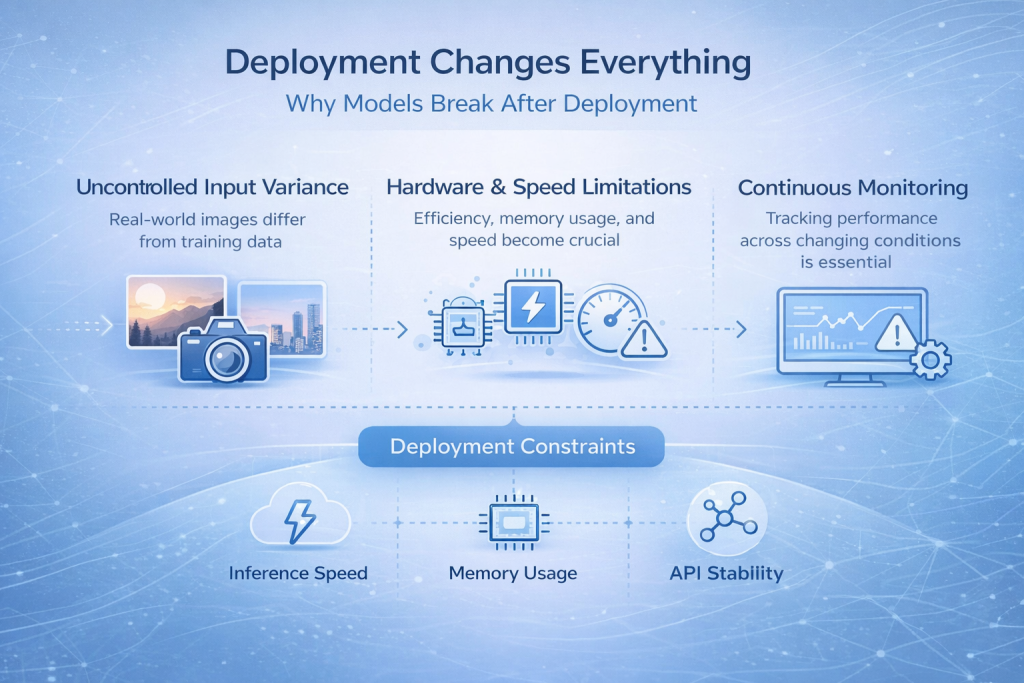
Die Bereitstellung ändert alles
Warum Modelle nach der Bereitstellung nicht mehr funktionieren
Viele Bilderkennungsmodelle funktionieren während der Entwicklung gut, versagen dann aber nach dem Einsatz. Dies ist einer der häufigsten und frustrierendsten Momente im gesamten Prozess.
Der Grund ist einfach. Reale Eingabedaten ähneln selten den Trainingsdaten. Bilder stammen von verschiedenen Kameras, die Lichtverhältnisse ändern sich im Laufe des Tages, Kompressionsartefakte treten auf, und Nutzer folgen nicht idealen Nutzungsmustern. Schon geringfügige Änderungen bei der Bildaufnahme können ein Modell aus dem Bereich herausholen, in dem es trainiert wurde.
Was in einer kontrollierten Umgebung stabil aussah, wird plötzlich unzuverlässig.
Die Einschränkungen, die Sie nicht ignorieren können
Die Implementierung zwingt dazu, über die reine Modellgenauigkeit hinauszudenken. Die Inferenzgeschwindigkeit wird entscheidend, wenn Vorhersagen in Echtzeit benötigt werden. Der Speicherverbrauch spielt eine wichtige Rolle, wenn das Modell auf Edge-Geräten oder mobiler Hardware ausgeführt wird. Hardwarebeschränkungen bestimmen, welche Architekturen überhaupt realisierbar sind, und die API-Stabilität wird unerlässlich, sobald andere Systeme von Ihren Vorhersagen abhängen.
Die Überwachung entwickelt sich von einer wünschenswerten Zusatzfunktion zu einer Notwendigkeit. Ohne Einblick in das Verhalten des Modells nach der Veröffentlichung können Fehler unbemerkt bleiben, bis das Vertrauen verloren geht.
Das Modell nutzbar machen
Der Export eines Modells in Formate wie TensorFlow Lite oder ONNX ist nicht nur ein technischer Schritt am Ende der Pipeline. Er ist Teil der Umwandlung eines trainierten Modells in ein produktionsreifes Produkt. Diese Formate helfen, das Modell an verschiedene Umgebungen anzupassen, den Overhead zu reduzieren und die Kompatibilität mit den Zielsystemen zu verbessern.
Ein Modell, das auf einem Notebook gut funktioniert, aber im Produktiveinsatz versagt, ist noch nicht ausgereift. Wirklicher Erfolg stellt sich erst ein, wenn das System dort, wo es eingesetzt werden soll, zuverlässig funktioniert.
Bilderkennung in der realen Welt: Wie wir sie bei FlyPix AI entwickeln
Bei FlyPix AI, Wir betrachten Bilderkennung nicht als Laborübung. Wir arbeiten täglich mit Satelliten-, Luft- und Drohnenbildern, in denen Szenen dicht beschaffen sind, Objekte sich überlappen und die Bedingungen nie perfekt sind. Diese Realität prägt unsere Entwicklung und Anwendung von KI.
Unser Ziel war von Anfang an einfach: die manuelle Bildanalyse als Engpass zu beseitigen. Teams verbrachten Hunderte von Stunden damit, Bildmaterial zu annotieren, Ergebnisse zu überprüfen und diese bei veränderten Bedingungen erneut zu kontrollieren. Wir haben FlyPix entwickelt, um diese Arbeit mithilfe von KI-Agenten zu automatisieren, die Objekte in großem Umfang erkennen, überwachen und untersuchen können – ohne dabei an Genauigkeit einzubüßen.
Uns ist die Praktikabilität am wichtigsten. Sie benötigen weder tiefgreifende KI-Kenntnisse noch ein Team von Machine-Learning-Experten, um ein Modell zu trainieren, das für Ihren Anwendungsfall geeignet ist. Mit FlyPix können Teams individuelle Bilderkennungsmodelle mit ihren eigenen Annotationen erstellen, die sich auf die Objekte konzentrieren, die in ihrer Branche wirklich relevant sind. Baustellen, Häfen, landwirtschaftliche Flächen, Infrastrukturanlagen, Forstgebiete – die Bildmaterialien sind unterschiedlich, die Herausforderung jedoch dieselbe.
Wir entwickeln alles mit Blick auf den Einsatz. Geodaten in der Praxis verändern sich ständig, daher müssen Modelle von Anfang an mit solchen Variationen umgehen können. Das bedeutet, Systeme zu entwickeln, die auch außerhalb von Testumgebungen zuverlässig funktionieren, große Bildmengen schnell verarbeiten und Ergebnisse liefern, auf die Teams sofort reagieren können. Für uns ist Bilderkennung erst dann erfolgreich, wenn sie sich im täglichen Betrieb bewährt, nicht nur während der Testphase.
Rückkopplungsschleifen halten das Modell am Leben
Eine KI zur Bilderkennung ist nicht statisch. Daten verändern sich. Umgebungen verändern sich. Erwartungen verändern sich.
Langlebige Systeme werden unter Berücksichtigung von Feedback entwickelt:
- Sammeln Sie nach der Bereitstellung neue Images.
- Gleisausfallfälle
- Regelmäßiges Nachschulen
- Beschriftungen anpassen, wenn sich die Realität ändert.
Das Ignorieren von Erkenntnissen nach der Implementierung ist einer der schnellsten Wege, das Vertrauen in das System zu verlieren.
Schlussfolgerung
Die Entwicklung einer tatsächlich funktionierenden KI zur Bilderkennung erfordert weniger die Jagd nach den neuesten Modellen, sondern vielmehr das korrekte Verständnis der Grundlagen. Eine klare Problemdefinition, disziplinierte Datenarbeit, sorgfältige Evaluierung und realistische Einsatzplanung sind weitaus wichtiger als die Wahl eines einzelnen Algorithmus.
Die zuverlässigsten Systeme sind nicht die komplexesten. Sie basieren auf einem fundierten Verständnis dafür, wie sich Bilder in der realen Welt verändern und wie Modelle auf diese Veränderungen reagieren. Sie werden mit realitätsnahen Daten trainiert, anhand von Metriken evaluiert, die Schwächen aufdecken, und von Anfang an unter Berücksichtigung der jeweiligen Einschränkungen eingesetzt.
Die wichtigste Erkenntnis ist diese: Bilderkennung ist ein technischer Prozess, kein einmaliges Experiment. Wenn man so vorgeht, sorgfältig iterativ vorgeht und sich an der realen Anwendung orientiert, sind die Ergebnisse in der Regel auch lange nach der Demo noch relevant.
Häufig gestellte Fragen
Bilderkennungs-KI ist ein System der Computer Vision, das lernt, Muster, Objekte oder Merkmale in Bildern zu erkennen. Es analysiert Pixeldaten und verwendet trainierte Modelle, um visuelle Muster mit Bezeichnungen oder Ergebnissen zu verknüpfen.
Nicht immer. Große Datensätze sind zwar hilfreich, doch Diversität und Qualität sind wichtiger als die reine Datenmenge. Mit Transferlernen und geeigneter Datenaugmentation lassen sich nützliche Modelle auch auf relativ kleinen, aber sorgfältig zusammengestellten Datensätzen trainieren.
Für die meisten Projekte ist es ein sicherer und effektiver Ansatz, mit einem bewährten Convolutional Neural Network (CNN) zu beginnen und Transfer Learning anzuwenden. Komplexere Modelle sollten nur dann eingesetzt werden, wenn ein triftiger Grund dafür vorliegt und ausreichend Daten vorhanden sind.
Genauigkeit allein genügt nicht. Sie sollten Konfusionsmatrizen, Präzision und Trefferquote betrachten und das Modell mit realen Bildern testen, die nicht Teil des Trainings waren. Die manuelle Überprüfung der Fehler ist oft der aufschlussreichste Schritt.
Dies geschieht üblicherweise, weil sich Produktionsbilder von den Trainingsdaten unterscheiden. Änderungen der Beleuchtung, der Kameraqualität, der Bildkomprimierung oder des Nutzerverhaltens können die Leistung beeinträchtigen. Diese Diskrepanz ist häufig und muss bei der Entwicklung berücksichtigt werden.
Ja. Die Bereitstellung ist kein letzter Schritt, der bis zum Schluss ignoriert werden kann. Hardwarebeschränkungen, Inferenzgeschwindigkeit, Speichernutzung und Integrationsanforderungen beeinflussen allesamt, wie das Modell erstellt und trainiert werden sollte.